|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
Backpropagarea
Cautarea se face de-a lungul unor directii conjugate, ceea ce produce o convergenta mai rapida decat aplicand metoda coborarii pe gradient. Pentru a actualiza ponderile, la fiecare iteratie se cauta in directia gradientului conjugat pentru a determina valoarea care minimizeaza functia de-a lungul acelei linii.
Metoda Fletcher-Reeves (traincgf)
La prima iteratie algoritmul cauta in directia gradientului
![]()
Se face o cautare liniara de-a lungul directiei curente de cautare pentru a determina pasul de actualizare
![]()
Urmatoarea directie de cautare se alege astfel incat sa fie conjugata cu directiile anterioare de cautare
![]()
unde
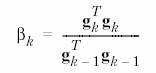
p = [-1 -1 2 2;0 5 0 5];
t = [-1 -1 1 1];
net=newff(minmax(p),[3,1],,'traincgf');
net.trainParam.show = 5;
net.trainParam.epochs = 300;
net.trainParam.goal = 1e-5;
[net,tr]=train(net,p,t);
Functia implicita de cautare liniara este srchcha (se poate schimba modificand valoarea parametrului srchFcn).
Rulati programul demonstrativ nnd12cg.
Metoda Polak-Ribiere (traincgp)
Diferenta fata de metoda anterioara consta in modul de calculare a lui bk
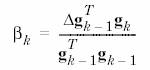
p = [-1 -1 2 2;0 5 0 5];
t = [-1 -1 1 1];
net=newff(minmax(p),[3,1],,'traincgp');
net.trainParam.show = 5;
net.trainParam.epochs = 300;
net.trainParam.goal = 1e-5;
[net,tr]=train(net,p,t);
Metoda Powel-Beale (traincgb)
In cazul tuturor metodelor gradientului conjugat, directia de cautare va fi resetata periodic la valoarea negativului gradientului. Momentul standard de resetare are loc cand numarul iteratiilor este egal cu numarul parametrilor retelei. Pentru metoda Powel-Beale resetarea se face cand proprietatea de ortogonalitate intre gradientul curent si cel anterior nu mai este indeplinita. Acest lucru este testat cu inegalitatea
![]()
Daca aceasta conditie este satisfacuta, directia de cautare este resetata la negativul gradientului.
p = [-1 -1 2 2;0 5 0 5];
t = [-1 -1 1 1];
net=newff(minmax(p),[3,1],,'traincgb');
net.trainParam.show = 5;
net.trainParam.epochs = 300;
net.trainParam.goal = 1e-5;
[net,tr]=train(net,p,t);
Golden Section Search (srchgol)
Primul pas este localizarea intervalului in care se afla minimul functiei de performanta prin evaluarea functiei intr-o secventa de puncte, aflate la inceput la distanta delta si dubland distanta la fiecare pas de-a lungul directiei de cautare. Daca performanta creste intre 2 puncte successive atunci minimul a fost localizat. Urmatorul pas este reducerea intervalului in care se afla minimul. Se aleg 2 puncte in interval si in functie de valorile functie de performanta in aceste puncte, intervalul se micsoreaza. Procedura continua pana cand lungimea intervalului devina mai mica decat delta/scale_tol.
Sa se ruleze programul demonstrativ nnd12sd1.
Brent's Search (srchbre)
Este o combinatie intre cautarea golden section si interpolarea patratica. Se incepe prin stabilirea intervalului ca la metoda anterioara, insa se evalueaza functia de performanta in mai multe puncte. Se determina functia patratica ce trece prin aceste puncte si se calculeaza minimul ei. Daca minimul cade in interval, se foloseste la urmatorul pas al cautarii si se face o noua aproximare patratica. Daca minimul cade in afara intervalului atunci se aplica un pas al metodei golden search.
Hybrid Bisection-Cubic Search (srchhyb)
Este o combinatie intre metoda bisectiei si interpolarea cubica. Se realizeaza o interpolare cubica a unei functii folosind valorile functiei de performanta si derivatele ei in 2 punte. Daca minimul functiei obtinute cade in interval atunci se foloseste pentru a micsora intervalul. Altfel se aplica metoda bisectiei.
Charalambous'Search (srchcha)
Este o metoda hibrida. Foloseste interpolarea cubica impreuna cu o metoda de sectionare.
Algoritmul BFGS (trainbfg)
Metoda lui
![]()
unde Ak este Hessiana functei de performanta la momentul k. Calcularea Hessianei in cazul unei retele neurale feedforward necesita calcule complexe. Metodele quasi-Newton lucreaza cu aproximari ale Hessianei.
p = [-1 -1 2 2;0 5 0 5];
t = [-1 -1 1 1];
net=newff(minmax(p),[3,1],,'trainbfg');
net.trainParam.show = 5;
net.trainParam.epochs = 300;
net.trainParam.goal = 1e-5;
[net,tr]=train(net,p,t);
Acest algoritm necesita mai multe calcule si mai multa memorie decat metodele gradientului conjugat. La fiecare pas se memoreaza aproximarea Hessianei care are dimensiunea numarului de parametri din retea.
Algoritmul One Step Secant (trainoss)
Poate fi considerat un compromis intre metoda gradientului conjugat si metoda quasi-Newton. Nu se memoreaza matricea Hessiana completa; la fiecare pas se presupune ca aproximarea anterioara este matricea identitate.
p = [-1 -1 2 2;0 5 0 5];
t = [-1 -1 1 1];
net=newff(minmax(p),[3,1],,'trainoss');
net.trainParam.show = 5;
net.trainParam.epochs = 300;
net.trainParam.goal = 1e-5;
[net,tr]=train(net,p,t);
Algoritmul Levenberg-Marquardt (trainlm)
Cand functia de performanta este suma de termeni patratici, Hessiana poate fi aproximata astfel
![]()
si gradientul poate fi calculat
![]()
unde matricea J este Jacobianul ce contine derivatele functiei de eroare in raport cu ponderile si bias-urile iar e este vectorul erorilor. Calcularea matricei J este mai putin complexa decat calcularea Hessianei.
Algoritmul Levenberg-Marquardt foloseste urmatoarea regula de actualizare a parametrilor
![]()
Daca m este 0 se obtine
metoda
Parametrii invatarii: mu, mu_dec, mu_inc, mu_max.
p = [-1 -1 2 2;0 5 0 5];
t = [-1 -1 1 1];
net=newff(minmax(p),[3,1],,'trainlm');
net.trainParam.show = 5;
net.trainParam.epochs = 300;
net.trainParam.goal = 1e-5;
[net,tr]=train(net,p,t);
Rulati programul demonstrativ nnd12m.
Copyright © 2025 - Toate drepturile rezervate