|







 |  |
|
| |
 | Aeronautica | Comunicatii | Constructii | Electronica | Navigatie | Pompieri |
| Tehnica mecanica |
Particularitati ale utilizarii variabilelor calitative intr-un model econometric
Intr-un model econometric, de regula, atat variabilele endogene, cat si variabilele exogene sunt variabile economice cuantificabile, exprimate in unitati de masura specifice naturii lor.
Dar, in anumite situatii, ambele grupe de variabile, endogene si exogene, pot fi de natura calitativa (nenumerice), variantele lor prezentandu-se prin cuvinte si nu prin numere.
Variabilele calitative sau variabilele dummy se refera deci la insusiri, calitati, categorii etc. a caror dimensiune este exprimata prin atribute sau denumiri. Aceste variabile, denumite si variabile atributive, se impart in doua categorii: variabile dihotomice (binare sau alternative) si variabile polihotomice (nealternative).
De exemplu, referindu-ne la consumul populatiei, acesta, ca variabila endogena, poate fi analizat atat ca variabila numerica: cheltuieli efectuate de o familie pentru consumarea sau procurarea unui anumit produs, sau nivelul/volumul consumului unui anumit produs pe familie sau pe membru de familie, dar si ca variabila calitativa alternativa, daca se cauta raspunsul la intrebari de genul: de la ce venit pe membru de familie sau pe familie, familiile consuma sau dispun de un anumit produs? De la ce venit pe membru de familie consumul familiilor este mai mare sau mai mic fata de media consumului pe familie ?
Se pot formula numeroase intrebari de genul celor de mai sus, stiind ca orice variabila cantitativa poate fi tranformata intr-o variabila alternativa prin raportarea variantelor ei la o anumita marime, care poate fi media ei sau o marime standard.
La randul lor, variabilele exogene pot fi atat cantitative, cat si calitative. In cazul consumului populatiei, factorii explicativi ai acestuia pot fi: venitul pe membru de familie sau pe familie, numarul membrilor de familie, pretul sau tariful bunurilor materiale sau al serviciilor, dar si sexul, mediul de provenienta, categoria socio-profesionala, nationalitatea (traditii) etc.
In cazul variabilelor exogene calitative se pot intalni doua situatii:
variabila prezinta numai doua variante, x1 sau x2, cum ar fi: sexul sau mediul de provenienta, denumite si variabile dihotomice sau binare;
variabila prezinta mai multe variante nenumerice, cum ar fi: categoria socio-profesionala sau nationalitatea.
Pe baza celor spuse mai sus, utilizarea variabilelor calitative intr-un model econometric poate fi sintetizata prin trei cazuri: variabila endogena Y este de natura calitativa binara; variabila exogena X este de natura calitativa alternativa (binara sau dihotomica) sau nealternativa (polihotomica).
Cazul 1: variabila endogena binara
Fie modelul econometric:
![]() (2.7.1)
(2.7.1)
unde:
![]() n numarul unitatilor statistice din
esantion, respectiv numarul familiilor,
n numarul unitatilor statistice din
esantion, respectiv numarul familiilor, ![]() ;
;

xi = variabila explicativa - venitul mediu al familiei i, pe membru de familie;
ui = variabila reziduala.
Spre deosebire de celelalte modele econometrice, in care variabila explicata este cantitativa, modelul (2.7.1) prezinta doua particularitati.
Prima se refera la natura variatiei variabilei reziduale ui. Din modelul (2.7.1) rezulta ca:
![]()
Stiind ca yi este
o variabila alternativa (binara) ce poate lua numai doua valori, ![]() , pentru orice valoare a variabilei explicative xi, perturbatia ui poate avea numai doua
valori distincte (-a - bxi) si (1 - a - bxi).
Deci variabila reziduala ui
nu este distribuita normal, ci are o distributie discreta, de forma:
, pentru orice valoare a variabilei explicative xi, perturbatia ui poate avea numai doua
valori distincte (-a - bxi) si (1 - a - bxi).
Deci variabila reziduala ui
nu este distribuita normal, ci are o distributie discreta, de forma:
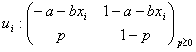 ;
;
cu media: ![]() ;
;
si dispersia: ![]() (2.7.2)
(2.7.2)
Relatia (2.7.2) evidentiaza faptul ca perturbatiile reziduale nu mai sunt homoscedastice, ci heteroscedastice (vezi subcapitolul 2.3). Din acest motiv, parametrii modelului (2.7.1) trebuie estimati cu ajutorul metodei celor mai mici patrate generalizata sau cu metoda regresiei ponderate, deoarece metoda celor mai mici patrate obisnuita nu conduce la obtinerea de estimatii eficiente in cazul existentei fenomenului de heteroscedasticitate.
A doua particularitate se refera la interpretarea previziunii efectuate cu modelul (2.7.1).
Admitand ca pentru momentul (n + v) se cunoaste distributia familiilor dupa marimea venitului mediu pe membru de familie si, in ipoteza "caeteris paribus", modelul (2.7.1) permite sa se cunoasca cate familii vor utiliza si cate nu vor utiliza produsul H in momentul (n+v).
Folosind
modelul (2.7.1) in acest scop,
utilizarea sau neutilizarea produsului H apare ca o probabilitate de insusire
(de posedare) a produsului respectiv, previziunile ![]() fiind interpretate in
functie de valorile pe care le va avea
fiind interpretate in
functie de valorile pe care le va avea ![]() in raport cu
intervalul [0,1].
in raport cu
intervalul [0,1].
Deoarece
predictiile ![]() sunt coliniare, ele
vor putea lua valori si in afara intervalului [0,1]. Exista mai multe procedee
de a evita acest inconvenient, cel mai simplu, practic, fiind acela de a lucra
cu estimatiile
sunt coliniare, ele
vor putea lua valori si in afara intervalului [0,1]. Exista mai multe procedee
de a evita acest inconvenient, cel mai simplu, practic, fiind acela de a lucra
cu estimatiile ![]() si
si ![]() si de a calcula valorile
si de a calcula valorile
![]() in functie de o
valoare luata de variabila explicativa
in functie de o
valoare luata de variabila explicativa ![]() . Acestea sunt definite dupa cum urmeaza:
. Acestea sunt definite dupa cum urmeaza:
![]() - daca
- daca ![]() ; adica, in caz concret, familia "i", avand venitul
; adica, in caz concret, familia "i", avand venitul ![]() are probabilitatea
are probabilitatea
![]() de a poseda (a
consuma) produsul H.
de a poseda (a
consuma) produsul H.
![]() - daca
- daca ![]() , deci familia "i",
avand venitul
, deci familia "i",
avand venitul ![]() , poseda produsul H;
, poseda produsul H;
![]() - daca
- daca ![]() familia "i", avand venitul
familia "i", avand venitul ![]() nu poseda produsul H.
nu poseda produsul H.
Mentionam ca problemele expuse in acest caz pot fi rezolvate si pe baza distributiei empirice a variabilei dependente Y, conditionata de variabila exogena X, folosind in acest scop tabelul de corelatie sau tabelul de asociere.
Modelul (2.7.1) prezinta avantajul ca poate fi folosit ca model de simulare - in cazul consumului populatiei este utilizat in vederea estimarii venitului minim pe membru de familie, pentru a consuma (a poseda) un anumit produs sau a utiliza un anumit serviciu. In plus, acest model poate fi generalizat si pentru o dependenta multifactoriala a variabilei endogene binare Y.
- Cazul 2: variabila exogena binara
Referindu-ne la consumul populatiei, mediul de provenienta - rural, urban, sexul etc., acestea reprezinta variabile exogene calitative, care nu pot avea decat doua variante.
Fie:
n numarul familiilor din esantion, ![]() ;
;
![]()
n1 = numarul familiilor ce poseda varianta A;
n2 = numarul familiilor ce poseda varianta B;, evident ca n1 + n2= n;
yi = consumul familiei i.
Admitand
ca variabila endogena Y (consumul
populatiei, de exemplu) urmeaza o distributie normala, de abatere standard ![]() si cu media egala cu:
si cu media egala cu:
![]() - consumul mediu al
familiilor ce poseda varianta A;
- consumul mediu al
familiilor ce poseda varianta A;
![]() - consumul mediu al
familiilor ce poseda varianta B;
- consumul mediu al
familiilor ce poseda varianta B;
atunci modelul econometric al variabilei dependente Y in functie de variabila exogena binara X este de forma:
![]() (2.7.3)
(2.7.3)
unde:
yi = consumul familiei i;
xi = variabila binara:
xi = 0 - daca familia poseda varianta A;
xi = 1 - daca familia poseda varianta B;
ui = variabila reziduala care satisface toate ipotezele de fundamentare ale unui model econometric - vezi capitolul 2.3.
Valorile medii ale variabilei y conditionate de variabila x rezultate din modelul econometric (2.7.3) sunt:
![]()
Observatie: ![]() , conform ipotezei Ii.
, conform ipotezei Ii.
![]()
Rezulta deci ca:
![]()
![]()
adica termenul liber al modelului (2.7.3) - punctul in care dreapta intersecteaza axa Oy - masoara nivelul mediu al caracteristicii y pentru unitatile statistice (familiile) care poseda varianta A, iar coeficientul unghiular al dreptei (b) masoara diferenta dintre nivelul mediu al caracteristicii y pentru unitatile statistice care poseda varianta B si nivelul mediu al lui y pentru unitatile ce poseda varianta A.
Estimatorii modelului (2.7.3) se obtin prin aplicarea M.C.M.M..P. - in conditiile aceptarii ipotezelor de fundamentare a modelului econometric - cu ajutorul urmatoarelor formule:
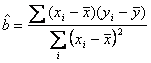
![]()
Stiind ca:
![]() ;
; ![]()
![]() ;
; ![]()
iar:
![]()
![]()
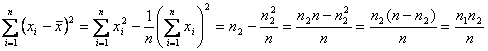
Rezulta ca:
![]() ;
;
![]()
![]() ;
;
adica estimatia
termenului liber, a, este egala cu
estimatia lui m1, iar
estimatia coeficientului de regresie este egala cu distanta dintre estimatiile ![]() a celor medii partiale
(m2 si m1) obtinute pe baza
esantionului de n unitati statistice.
a celor medii partiale
(m2 si m1) obtinute pe baza
esantionului de n unitati statistice.
In
mod corespunzator - vezi capitolul (2.3), relatiile (2.3.8) si (2.3.9) - se vor
calcula estimatiile dispersiilor celor doi estimatori ai parametrilor a si b,
![]() respectiv
respectiv ![]() .
.
Pentru
a verifica daca variabila alternativa exercita o influenta sistematica asupra
variabilei explicate y - in cazul
nostru, y este consumul familiilor -
se testeaza semnificatia coeficientului de regresie ![]() [1].
Daca:
[1].
Daca:
- 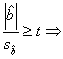 variabila calitativa
alternativa (x) influenteaza in mod
sistematic caracteristica dependenta (y)
si, deci, va trebui inclusa in pachetul de variabile exogene ale variabilei
endogene Y
variabila calitativa
alternativa (x) influenteaza in mod
sistematic caracteristica dependenta (y)
si, deci, va trebui inclusa in pachetul de variabile exogene ale variabilei
endogene Y
- 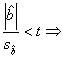 variabila calitativa
alternativa (x) nu influenteaza in
mod semnificativ caracteristica dependenta (y)
si, ca atare, nu trebuie inclusa in pachetul de variabile explicative ale
variabilei explicate (y).
variabila calitativa
alternativa (x) nu influenteaza in
mod semnificativ caracteristica dependenta (y)
si, ca atare, nu trebuie inclusa in pachetul de variabile explicative ale
variabilei explicate (y).
Cazul 3: Variabila exogena calitativa nealternativa (polihotomica)
Uneori, anumiti factori semnificativi ai unei variabile endogene Y sunt necuantificabili, avand un anumit numar de variante nenumerice. In domeniul consumului populatiei, acesti factori se refera la categoria socio-profesionala, zona geografica, traditiile generate de nationalitate etc.
O maniera de cuantificare a unor astfel de variabile exogene consta in a codifica variantele lor cu numerele: x1 = 0, x2 = 1, x3 = 2, .., xk = k - 1.
Modelul econometric constituit in aceasta ipoteza este:
![]() (2.7.4)
(2.7.4)
unde:
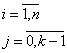
![]() consumul familiei i;
consumul familiei i;

In acest caz, mediile variabilei endogene Y, conditionate de variabila explicativa (x), calculate pe baza modelului (2.7.4) sunt:
![]()
![]()
![]()
![]()
![]()
Din relatiile de mai sus rezulta ca nivelul mediu al consumului unei familii creste in mod constant cu marimea b, pe masura ce se trece de la o categorie social-economica la alta, sau ca diferenta dintre consumul mediu a doua familii ce fac parte din doua categorii social-economice succesive este constanta si egala cu coeficientul de regresie b:
![]()
Acordarea de valori echidistante variantelor unei variabile exogene calitative nealternative nu poate fi folosita decat intr-un caz particular, atunci cand si mediile conditionate ale variabilei exogene sunt echidistante.
Pentru a evita aceasta restrictie intr-un model econometric, variabila explicativa calitativa nealternativa se introduce prin (k-1) variabile binare, daca ea prezinta k variante relative.
Astfel, daca o variabila explicativa prezinta trei variante calitative (A, B, C), modelul econometric va fi de forma:
![]() ; (2.7.5)
; (2.7.5)
unde:
yi = consumul familiei i;
![]()
![]()
De retinut ca, daca:
x1 Þ x2 = 0
x2 Þ x1 = 0
x1 = x2= 0 Þ familia i poseda varianta A.
In acest caz, modelul (2.7.5) devine echivalent cu modelul (2.7.3):
![]()
![]()
![]()
Rezulta ca parametrii modelului sunt egali cu:
![]()
![]()
![]()
unde:![]() ,
, ![]() si
si ![]() reprezinta nivelul mediu al consumului pentru
familiile care poseda varianta A, respectiv B, respectiv C.
reprezinta nivelul mediu al consumului pentru
familiile care poseda varianta A, respectiv B, respectiv C.
Din acest punct de vedere, modelul urmeaza sa fie discutat si intrepretat pe baza criteriilor expuse in subcapitolele 2.3 si 2.4.
Modelele PROBIT, LOGIT, TOBIT sunt modele care contin variabile calitative (nenumerice), ale caror variante sunt exprimate prin cuvinte.
Tobin a elaborat in 1958 un model privind cererea de autoturisme utilizand date dezagregate. Ideea de baza a modelului este aceea ca: cheltuielile in vederea achizitionarii unui autoturism depind de venitul individual. Apare insa o problema si anume faptul ca anumite persoane prefera sa nu cumpere deloc o masina si astfel indivizii se impart in doua grupuri, G1, cei care au cumparat o masina si G2, cei care n-au cumparat. Daca s-ar elimina grupul G2 din esantion s-ar obtine o estimatie deplasata a elasticitatii ventului. In aceasta situatie, se va alege cel de-al doilea caz, in cadrul caruia se utilizeaza o variabila calitativa binara (care este non-continua), cu doua variante: 1 sau 0.
O abordare generala a acestui tip de problema se bazeaza pe utilizarea unui model de regresie liniar :
Yt = b X t + u t 2.7.6)
Yt poate fi observat numai in situatia in care Yt > 0, si astfel modelul devine:
Yt = b X t + u t daca b X t + u t > 0 (2.7.7)
Yt = in caz contrar (2.7.8)
Daca se incearca sa se estimeze aceasta ecuatie cu ajutorul M.C.M.M.P. utilizand doar observatiile din grupul G1, respectiv in cazul in care Yt > 0, estimatiile obtinute vor fi deplasate si inconsistente, deoarece nu se poate presupune ca M (u t ) = 0 pentru toti t. In vederea rezolvarii acestei situatii se defineste functia de verosimilitate corespunzatoare modelului pe baza ipotezei ca variabila reziduala (aleatoare) u t urmeaza o anumita distributie. Presupunerea facuta de Tobin (1958) a fost ca u t urmeaza o distributie normala de medie zero si dispersie s , astfel luand nastere modelul TOBIT(sau modelul PROBIT elaborat de Tobin).
Astfel,functia de verosimilitate L corespunzatoare modelului prezentat mai sus este de forma:
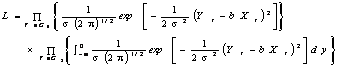 (2.7.9)
(2.7.9)
Aceasta trebuie maximizata in vederea estimarii parametrilor b si a abaterii medii patratice s
Obtinerea de variante ale acestui model implica utilizarea unor ipoteze alternative cu privire la distributia valorilor variabilei reziduale. In acest scop va fi definita functia de verosimilitate intr-o forma compacta, notand cu f (.) functia de densitate si cu F (.) functia de densitate cumulata. Pe baza acestor notatii functia de verosimilitate va fi exprimata astfel:
![]() (2.7.10)
(2.7.10)
Daca functia densitatii cumulate F (.) este definita sub forma functiei logistice va rezulta un alt tip de model cu variabile calitative:
![]() (2.7.11)
(2.7.11)
Acest model este cunoscut sub numele de model LOGIT. Principalul avantaj al acestui model, comparativ cu modelul TOBIT, consta in usurinta cu care se efectueaza calculele numerice, deoarece functia logistica se calculeaza mai usor decat functia normala cumulata.
In cazul in care variabila dependenta (endogena) ia doar doua valori, atunci functia de verosimilitate este o simplificare a modelului econometric cu variabile calitative general. De exemplu, se presupune ca Y = 1, in cazul in care guvernul aplica o anumita politica in domeniul consumului si Y = 0 daca politica este inoperativa. Daca G1 reprezinta grupul pentru care Y = 0 atunci functia de verosimilitate include doar functia densitatii cumulate si are urmatoarea forma:
![]() (2.7.12)
(2.7.12)
Functia de verosimilitate va reprezenta un model PROBIT atunci cand F (.) este definita sub forma functiei de densitate normala cumulata si un model LOGIT atunci cand este definita sub forma functiei logistice.
Aceste categorii de modele pot fi utilizate in vederea efectuarii de prognoze si simulari in domeniul consumului.
Testarea semnificatiei coeficientului de regresie ![]() este echivalenta cu
testarea ipotezei ca cele doua medii, m1
si m2, provin sau nu din aceeasi populatie.
este echivalenta cu
testarea ipotezei ca cele doua medii, m1
si m2, provin sau nu din aceeasi populatie.
Un alt mod de rezolvare a problemei consta in a nu introduce variabila calitativa in pachetul de variabile explicative cantitative ale caracteristicii y, ci de a construi doua modele de corelatie distincte: unul pentru unitatile statistice ce poseda varianta A (familii din mediul rural), iar altul pentru unitatile ce poseda varianta B (familii din mediul urban).
Copyright © 2025 - Toate drepturile rezervate