|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
Drumuri minime in grafuri
Acest capitol trateaza in detaliu doua probleme: drumuri de lungime minima intr-un graf neponderat si drumuri de cost minim intr-un graf ponderat.
Pentru fiecare din aceste probleme sint prezentati algoritmii cei mai eficienti: algoritmul lui Lee pentru drumuri de lungime minima, respectiv algoritmul lui Dijkstra pentru drumuri de cost minim. Algoritmul lui Dijkstra este prezentat impreuna cu o structura de date (arbore de selectie) care contribuie la cresterea eficientei acestuia.
In literatura de specialitate sint prezentati si alti algoritmi care pot rezolva aceste probleme, dar din pacate acestia au un ordin de complexitate care ii face inutilizabili pentru volume mari de date. In capitolul urmator va fi prezentat algoritmul lui Bellman, care poate fi folosit (cel putin in scop didactic) pentru rezolvarea problemelor de drum maxim si minim.
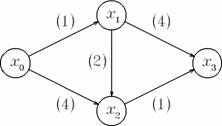
Figura 1. Drumuri minime intre x0 si x3:
de lungime minima: x0 - x1 - x3 si x0 - x2 - x3
de cost minim: x0 - x1 - x2 - x3
1. Drumuri de lungime minima
Problema. Fie un graf G = (X, G ); sa se determine un drum de lungime minima (numar minim de arce) intre doua virfuri s si t.
Aplicatii 1) X reprezinta o multime de statii CFR, si G reprezinta legaturile directe dintre statii: pentru fiecare statie, unde se poate ajunge direct, cu un singur tren. Sa se determine o ruta intre doua statii care necesita cit mai putine schimbari, daca intre cele doua statii nu exista o legatura directa.
2) X reprezinta o multime de camere dintr-un labirint, si G reprezinta relatiile de vecinatate: pentru fiecare camera, care sint camerele unde se poate ajunge direct. Sa se determine un drum cit mai scurt spre iesirea din labirint.
Exemplu. In figura 1, intre x0 si x3 avem doua drumuri de lungime minima: x0 - x1 - x3 si x0 - x2 - x3.
Pentru a rezolva aceasta problema folosim tehnica breadth first search. Deoarece aceasta tehnica proceseaza virfurile in ordinea distantei de la virful sursa, putem gasi astfel lungimea celui mai scurt drum intre doua virfuri date, concret numarul de arce ale acestuia.
Algoritm DrumLungMinim (Lee);
Intrare Un graf orientat (X, G ) si un virf s din X.
Iesire. Lungimile minime de la s la toate celelalte virfuri din X intr-un
masiv p. Informatiile necesare reconstituirii unui drum de lungime
minima de la s la orice alt virf x din X intr-un masiv P.
begin
for (each x I X) do begin
P[x] x; p[x]
end
Q[0] s; p[s] 0;
u 0; v 1;
while (u < v) do begin
x Q[u]; u u 1;
for (each y I G (x)) do
if (p[y] ) then begin
p[y] p[x] 1; P[y] x;
Q[v] y; v v 1;
end
end
end (algoritm).
In masivul P se memoreaza informatii necesare reconstituirii unui drum de lungime minima de la s la orice alt virf x din X. Initial fiecare element din masiv indica spre el insusi, marcind astfel faptul ca pentru nici un virf x din X inca nu a fost definit predecesorul. Fiecare element de indice x din P indica predecesorul virfului x pe un drum de lungime mai mica decit al unui drum gasit anterior. Reconstituirea unui drum de la s la t se face astfel:
begin
k 0; D[0] t; x t;
while (x s) do begin
x p[x];
k k 1; D[k] x;
end
end
In masivul D se obtine drumul cautat si virfurile apar in ordine inversa - de la t la s.
Daca se cere sa se determine un drum de lungime minima de la s la t, algoritmul se poate opri atunci cind se extrage din coada virful t:
x Q[u]; u u 1;
if (x t) then break;
Teorema 1. Un drum de lungime minima intre doua virfuri ale unui graf poate fi determinat intr-un timp de ordin O(n m
2. Drumuri de cost minim
Problema. Fie un graf ponderat G = (X, G, c). Sa se determine un drum de cost minim (suma costurilor arcelor) intre doua virfuri s si t.
Exemplu In figura 1, intre x0 si x3 avem un drum de cost minim: x0 - x1 - x2 - x3. Se observa ca acesta nu coincide cu nici unul din drumurile de lungime minima.
Algoritm DrumCostMinim (Dijkstra);
Intrare. Un graf orientat ponderat (X, G, c) si un virf s din X.
Iesire. Costurile minime de la s la toate celelalte virfuri din X intr-un
masiv p. Informatiile necesare reconstituirii unui drum de cost
minim de la s la orice alt virf x din X intr-un masiv P.
begin
for (each x I X) do begin
p[x] P[x] x;
end
S X; p[s] 0;
Actualizeaza reprezentarea cuplului (S, p
while (S ) do begin
x Min(S, p (extrage un virf x I S cu marca p minima)
for
(each y I G (x)![]() S) do begin
S) do begin
w p[x] c(x,y);
if p[y] > w) then begin
p[y] w; P[y] x;
Actualizeaza reprezentarea cuplului (S, p
end
end
end
end (algoritm).
Ideea acestui algoritm este urmatoarea. Pentru fiecare virf x se pastreaza o marca - un cost tentativa intre s si x; aceasta marca poate fi foarte mare, dar niciodata nu este mai mica decit costul real minim dintre s si x. Initial marca asociata virfului s este 0, si toate celelalte virfuri au marca . Marca fiecarui virf se memoreaza intr-un masiv p. Se pastreaza de asemenea o multime S de virfuri neexaminate, al caror cost real minim nu este inca cunoscut; daca un virf x nu se afla in S, costul real minim al acestuia coincide cu p[x]. Initial S coincide cu X; algoritmul se termina cind S (putem termina si mai repede in momentul in care se extrage din multimea S un virf t precizat dinainte).
Cautarea se face intr-un cerc cu centrul in jurul virfului s dupa cum urmeaza. Se extrage un virf x din S care are marca minima. Consideram fiecare succesor y al lui x (y I G (x)) si se compara marca p[y] cu valoarea w p[x] c(x, y). Daca p[y] > w atunci p[y] se corecteaza cu w si se inregistreaza faptul ca x este un predecesor al lui y pe un drum mai bun decit altul gasit anterior. Aceasta comparare se face numai pentru acei succesori ai lui x din S, deoarece ceilalti succesori nu mai au nevoie de corectie (marca asociata coincide cu costul real minim). De fiecare data procedura extrage un singur virf din S, astfel ca se executa exact n pasi.
Acest algoritm este evident unul de tip Greedy: de fiecare data se extrage virful care are marca minima si, deoarece acesta nu se mai afla in S, presupune ca marca asociata este costul real minim.
Complexitatea acestui algoritm va fi analizata dupa ce vor fi studiate mai multe posibilitati de reprezentare a cuplului (S, p). Tocmai din acest motiv am rezervat o procedura care actualizeaza aceasta reprezentare dupa fiecare corectare a costului unui virf.
3. Determinarea tuturor drumurilor minime
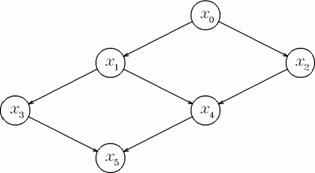
Figura 2. Intre x0 si x5 exista 3 drumuri.
In sectiunea 1 am prezentat o tehnica ce ne permite memorarea informatiilor necesare reconstituirii unui drum minim care pleaca dintr-un virf dat. Daca dorim sa determinam toate drumurile minime intre doua virfuri date (figura 2), trebuie sa folosim structuri de date mai complexe pentru a memora toti predecesorii unui virf. In descrierile care urmeaza utilizam un tip de date multime pentru a memora aceste informatii, P (o lista de multimi) fiind reprezentat ca o matrice care memoreaza listele predecesorilor. Ca si terminator de lista se poate folosi pentru fiecare linie o valoare speciala.
Initializarea listelor de predecesori
for (each x I X) do P[x]
Memorarea predecesorilor virfului y
w p[x] cost(x,y);
(daca se cer drumuri de lungime minima atunci cost(x,y) este 1)
if (p[y] > w) then begin
p[y] w; P[y]
end
if (p[y] w) then P[y] P[y]![]()
Toate drumurile minime intre doua virfuri date se determina cu ajutorul unui algoritm de tip back-tracking, pastrindu-se pentru fiecare virf din drum o informatie care sa indice urmatorul predecesor al acestuia care ar putea conduce la un alt drum minim.
Exemplu Sa se determine toate drumurile minime de la x0 la x5.
P[0] P[1] P[2]
P[3] P[4] P[5]
Primul drum: 5(1), 3(-), 1(-), 0(-)
virful 5 are inca un virf in lista de predecesori pe pozitia 1 (dupa virful 3 urmeaza virful 4); celelalte virfuri nu mai au predecesori in lista;
Al doilea drum: 5(-), 4(1), 1(-), 0(-)
virful 4 are inca un virf in lista de predecesori pe pozitia 1 (dupa virful 1 urmeaza virful 2);
Al treilea drum: 5(-), 4(-), 2(-), 0(-)
listele de predecesori ale tuturor virfurilor sint vide.
4. Arbori de selectie
Cea mai simpla modalitate de reprezentare a cuplului (S, p) consta in utilizarea a doua masive de cite n elemente, unul pentru lista S a virfurilor, celalalt pentru costuri. In acest caz, extragerea unui virf de cost minim presupune efectuarea a n verificari la prima iteratie,n-1 la a doua, o verificare la ultima. Rezulta in total un numar de operatii de ordin O(n2) doar pentru activitatea de extragere. Actualizarea costurilor necesita un numar de operatii proportional cu
|G (0)| G (1)| G (n-1)| m
Folosind o astfel de reprezentare, algoritmul lui Dijkstra are complexitate de ordin O(n2 m), ceea ce este inacceptabil pentru grafuri cu numar foarte mare de virfuri, de ordinul zecilor sau sutelor de mii. Deoarece majoritatea problemelor practice sint modelate cu ajutorul unor grafuri rare, unde numarul de arce nu depaseste cu mult numarul de virfuri, se recomanda in implementare utilizarea unei structuri de date de tip arbore de selectie.
O astfel de structura trebuie sa permita efectuarea urmatoarelor operatii intr-un timp cit mai scurt (Johnson):
- interogare: ce cost are virful x?
- extragerea unui virf de cost minim;
- micsorarea costului unui virf.
Cele doua operatii care modifica structura trebuie sa o reorganizeze, astfel incit fiecare operatie ulterioara sa poata fi efectuata intr-un timp cit mai scurt.
Reprezentarea cuplului (S, p) ca un arbore de selectie se face in modul urmator. Sa presupunem ca avem p (9, 8, 8, 2, 7, 11, 7), si lista S (0, 1, 2, 3, 4, 5, 6). In figura 3 avem o reprezentare grafica a unei posibile configuratii, care a rezultat in urma unor actualizari.
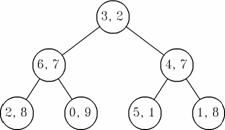
Figura 3. Arbore de selectie pentru memorarea cuplului (S,p
Explicatie. Virful x3 are costul 2 (minim), de aceea se afla in virful ierarhiei. Fiii sai in aceasta ierarhie sint x6 si x4, ambele virfuri avind costul 7. Relatia de ordine intre costuri se pastreaza doar pe verticala, de la radacina la oricare din frunze. Nu exista nici o relatie de ordine pe orizontala.
Masivul K memoreaza informatii cheie despre fiecare virf: c este costul virfului si a este pozitia acestuia in arbore. Masivul A indica ierarhia virfurilor in arborele de selectie. Pe prima pozitie (zero) se memoreaza radacina arborelui. Fiii unui virf aflat pe pozitia k se afla pe pozitiile 2k 1 si 2k 2.
K (9,4), (8,6), (8,3), (2,0), (7,2), (11,5), (7,1).
A (3, 6, 4, 2, 0, 5, 1).
Explicatie. Virful x1 cu costul 8 se afla in arborele de selectie pe pozitia 6; in mod corespunzator trebuie sa avem A[6] x 1.
Retinem ca o regula generala relatia dintre cele doua masive:
(K[x].a u) si (A[u] x)
Nu este necesar sa se memoreze informatii suplimentare de tipul x X deoarece acestea pot fi codificate astfel: daca un virf este extras din coada, in masivul K pozitia acestuia va fi o valoare negativa.
Initializarea structurii:
for (each x I X) do begin
K[x].c K[x].a x;
A[x] x; P[x] x;
end
na n; Modifica(s, 0);
na reprezinta numarul de elemente din arbore. Dupa corectarea costului virfului s (procedura Modifica), acesta trebuie sa urce in ierarhie, pentru a se restabili relatia de ordine specifica unui arbore de selectie.
Procedura Modifica(virf y, cost w) - cf Athanasiu et al;
begin
K[y].c w; u K[y].a;
while (u > 0) do begin
v (u-1) / 2;
if (K[A[v]].c w) then break;
A[u] A[v]; K[A[v]].a u; u v;
end
A[u] y; K[y].a u;
end (procedura);
Functia Extrage() - cf Athanasiu et al;
begin
x A[0]; K[x].a -1;
v 0; na na - 1;
A[0] A[na]; K[A[0]].a 0;
while (True) do begin
u 2 v 1;
if (u na) then break;
if (u 1 < na) then
if (K[A[u]].c > K[A[u 1]].c) then
u u 1;
if (K[A[na]].c K[A[u]].c) then break;
A[v] A[u]; K[A[u]].a v;
v u;
end
A[v] A[A[na]]; K[A[na]].a v;
return x;
end (functie);
Termenul arbori de selectie este preluat din lucrarea Tehnici de programare (Athanasiu et al).
Pentru extragere se retine care este virful aflat in ierarhie, si se marcheaza in masivul C faptul ca acest virf nu va mai face parte din lista. In continuare se aduce pe prima pozitie a masivului A (in radacina arborelui) virful aflat pe ultima pozitie. Se actualizeaza referinta acestui virf in masivul C.
De ce se aduce ultimul element din masivul A pe prima pozitie? Arborele de selectie trebuie sa aiba in acest masiv o reprezentare compacta.
In continuare elementul aflat in radacina arborelui ar putea avea un cost prea mare, si atunci trebuie restabilita relatia de ordine cu fiii sai. In acest scop virful trebuie sa coboare in ierarhie spre stinga sau spre dreapta.
De fiecare data cind se modifica ierarhia in arbore, la urcare sau la coborire, informatiile despre pozitie se actualizeaza si in masivul K.
Arborele are initial n elemente, si inaltimea acestuia este de ordin O(log n). Acesta este si ordinul de complexitate al celor doua functii, de modificare a costului unui virf si de extragere a elementului de cost minim. Algoritmul lui Dijkstra efectueaza cel mult m modificari de cost si cel mult n extrageri. Rezulta
Teorema 2. Algoritmul lui Dijkstra, bazat pe arbori de selectie, determina un drum de cost minim intre doua virfuri ale unui graf intr-un timp de ordin O((m n) log n).
Acest ordin de complexitate este estimat pentru cele mai defavorabile cazuri. In practica, unde se cere determinarea unui drum de cost minim intre doua virfuri, numarul de operatii pe arborele de selectie este dat de numarul de arce traversate pina ce se extrage din arbore virful final.
5. Algoritmul lui Dijkstra: revizuire
O imbunatatire a performantelor acestui algoritm se poate obtine astfel (Giumale, 73-76). Initial toate virfurile au costul , si lista S contine doar virful s. Pe parcurs se introduc in lista S doar acei succesori ai virfului extras care au costul , pentru celelalte virfuri se modifica doar costul. Virfurile extrase nu mai apar in lista S.
O implementare simpla va folosi pentru lista S un sir de maximum n indecsi corespunzatori virfurilor grafului. O implementare eficienta presupune adaptarea functiilor prezentate in sectiunea precedenta.
In continuare prezentam doar corpul algoritmului modificat in conformitate cu observatiile facute mai sus.
begin
for (each x I X) do begin
p[x] P[x] x;
end
S ; p[s] 0;
Actualizeaza reprezentarea cuplului (S, p
while (S ) do begin
x Min(S, p (extrage un virf x I S cu marca p minima)
for
(each y I G (x)![]() S) do begin
S) do begin
w p[x] c(x,y);
if p[y] > w) then begin
if (p[y] ) then S S ![]() ;
;
p[y] w; P[y] x;
Actualizeaza reprezentarea cuplului (S, p
end
end
end
end (algoritm).
In lucrarea Introducere in algoritmi (Cormen et al), sint descrisi in detaliu mai multi algoritmi care determina drumuri optime in grafuri. In conexiune cu algoritmul Dijkstra sint descrise doua structuri de date care pot fi folosite pentru accelerarea performantelor acestuia. Prima structura e deja cunoscuta: arbori de selectie, a doua se bazeaza pe arbori Fibonacci.
O implementare bazata pe arbori Fibonacci conduce in final la o complexitate amoritzata de ordin O(n log n m), fapt care o face atractiva pentru grafuri dense. Din pacate implementarea acestei structuri este dificila, astfel ca pentru probleme practice, unde intervin grafuri rare, cea mai buna solutie este utilizarea structurilor de tip arbore de selectie.
De altfel in prefata am precizat: nu am urmarit "perfectiunea" din punctul de vedere al complexitatii, am preferat algoritmi care au complexitate acceptabila, o descriere simpla si sint usor de urmarit.
6. Drumuri minime in grafuri foarte mari
In problemele de planificare a traseelor optime este foarte important sa utilizam algoritmi performanti care sa determine drumuri intre doua virfuri ale unui graf. Daca o aplicatie de transport gestioneaza un graf foarte mare, unde |X| este de ordinul sutelor de mii, si |U| de ordinul milioanelor, cum este cazul retelei complete de drumuri ale unei tari de marime mijlocie, atunci chiar si o implementare dupa algoritmul prezentat anterior are uneori un timp de raspuns care cu greu poate fi acceptat. Problema devine critica atunci cind aplicatia ruleaza pe un server si trebuie sa satisfaca cereri care pot veni de la mai multi utilizatori pe Internet.
Deoarece in asemenea cazuri determinarea unui drum de cost minim poate lua mult timp, este de preferat sa se determine un drum de cost apropiat celui optim, dar care poate fi gasit foarte repede. In multe probleme practice de aceasta natura avem informatii suplimentare despre virfuri si despre legaturi, cum ar fi:
(i) fiecare legatura poate fi o ruta importanta sau secundara;
(ii) rutele importante sint in numar redus in comparatie cu cele secundare (de exemplu 8-10%);
(iii) virfurile importante - aflate (numai) pe rute importante, sint de asemenea in numar redus in comparatie cu celelalte;
(iv) rutele importante sint repartizate aproape uniform printre cele secundare; aceeasi observatie este valabila si pentru virfuri.
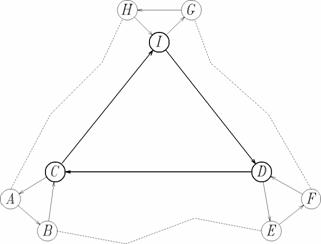
Figura Exemple de drumuri: (A, B, C), (C, I, D), (B, C, I, D, E, F).
Ideea pe care dorim sa o punem in practica este urmatoarea (figura 4) (Cozac). Fiind date doua virfuri s si t, ambele aflate doar pe rute secundare, determinam mai intii un drum de cost minim de la s la cel mai apropiat virf s1 aflat pe o ruta importanta. De asemenea determinam un drum de cost minim in sens invers de la t la cel mai apropiat virf t1 aflat pe o ruta importanta. In continuare determinam un drum de cost minim de la s1 la t1 luind in considerare numai rutele importnate. Solutia problemei se obtine reunind cele trei drumuri. Astfel gasirea unei solutii este mult accelerata deoarece:
- drumurile de la s la s1 si de la t la t1 se determina foarte repede - observatia (iv);
- drumul de la s1 la t1 se determina de asemenea foarte repede - observatiile (ii) si (iii).
Pentru a putea utiliza algoritmul schitat mai sus trebuie sa pregatim doua structuri suplimentare.
Se parcurge graful original pentru a marca toate virfurile care se afla pe o ruta importanta. Folosind aceste virfuri se determina un subgraf partial care are doar aceste virfuri si rutele importante. Fie acest subgraf partial Gs (Xs, Us). Se determina de asemenea siGi (X, Ui), graful invers corespunzator grafului original.
In continuare descriem algoritmul de determinare a unui drum de cost apropiat celui optim.
Algoritm DrumAproapeOptim;
Intrare. Graful original G, graful invers Gi, subgraful partial Gs;
doua virfuri distincte s si t.
Iesire. Un drum aproape optim de la s la t.
begin
* daca (s nu e pe o ruta importanta) atunci
determina in graful G, folosind algoritmul Dijkstra si arbori
de selectie, un drum de cost minim D1 de la s la cel mai
apropiat virf s1 aflat pe o ruta importanta;
daca virful t este depistat mai repede, stop:
am gasit drumul cautat;
altfel (s e pe o ruta importanta)
fie s1 s; D1
* daca (t nu e pe o ruta importanta) atunci
determina in graful Gi, folosind algoritmul Dijkstra si arbori
de selectie, un drum de cost minim D2 de la t la cel mai
apropiat virf t1 aflat pe o ruta importanta;
altfel (t e pe o ruta importanta)
fie t1 t; D2
* determina in graful Gs, folosind algoritmul Dijkstra si arbori
de selectie, un drum de cost minim D3 de la s1 la cel mai
apropiat virf t1 aflat pe o ruta importanta;
* reuneste cele trei drumuri: D D1![]() D2
D2![]() D3;
D3;
* raporteaza rezultatul: D;
end (algoritm).
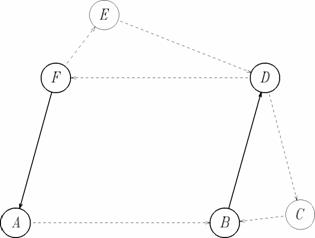
Figura 5. Exemplu de graf pentru care algoritmul
DrumAproapeOptim nu functioneaza corect:
nu gaseste nici un drum de la A la D sau de la A la E.
Putem folosi acest algoritm in orice conditii? Raspunsul la aceasta intrebare il da
Teorema 3. Algoritmul DrumAproapeOptim gaseste un drum intre oricare doua virfuri ale grafului G daca si numai daca grafurile G si Gs sint tare conexe.
Demonstratie. Conditiile sint evident suficiente, si este de asemenea evident ca graful G trebuie sa fie tare conex. Ramine sa demonstram ca si graful Gs trebuie sa fie tare conex. Intr-adevar, sa presupunem ca graful Gs nu este tare conex. Pot aparea urmatoarele situatii cind algoritmul raporteaza in mod eronat ca nu exista drum intre doua virfuri, chiar daca un astfel de drum exista - graful G este tare conex (a se vedea figura 5):
- putem gasi doua virfuri distincte x si y, ambele aflate pe rute importante, astfel incit sa nu existe drum de la x la y format numai din rute importante;
putem gasi doua virfuri distincte x si y, cel putin unul aflat pe o ruta secundara, astfel incit sa nu existe drum de la x la y format din rute secundare si importante. n
O tehnica eficienta de reprezentare
In loc sa se reprezinte un subgraf partial Gs separat, putem sa-l memoram intr-o singura structura impreuna cu graful original G. Sa presupunem ca trebuie sa reprezentam graful din figura 2.6; cele doua grafuri pot fi reprezentate astfel:
Hg 0 1 2 4 6 7 8 9 10
Lt 1 2 4 6 7 8 9 10 12
Lp 0 2 3 5 6 8 8 10 11
Ls B C I A C E F D H I D G
Pos 0 1 2 3 4 5 6 7 8 9 10 11
Aceste masive se citesc astfel:
- Ls este lista succesorilor virfurilor A, ., I;
- Hg este o tabela de dispersie pentru multimea Ls; de exemplu, succesorii virfului D sint memorati in tabloul Ls pe pozitiile 4, 5, .;
- Lt este un masiv care contine limitele superioare pentru intreaga lista a succesorilor fiecarui virf; de exemplu, succesorii virfului C sint memorati in masivul Ls pe pozitiile 2 si 3; se memoreaza pe primele pozitii succesorii care sint virfuri importante;
- Lp este un masiv care contine limitele superioare pentru lista succesorilor importanti ai fiecarui virf; de exemplu, singurul succesor important al virfului D este memorat in tabloul Ls pe pozitia
Pentru a usura citirea informatiilor, am indicat in lista Pos indecsii elementelor masivelor descrise mai sus.
Aceasta structura este o extensie a reprezentarii mentionate in sectiunea 2.2, si consuma minimum posibil de memorie. Pe de alta parte, aceasta poate fi folosita doar pentru grafuri statice.
Cum estimam uniformitatea?
Cum decidem daca drumurile importante sint uniform repartizate printre cele secundare?
In faza de preprocesare, dupa crearea tuturor structurilor de date necesare, putem folosi urmatorul algoritm. Parcurgem intreaga lista de virfuri secundare pentru a determina, pentru fiecare virf, citi pasi sint necesari pentru a atinge un virf important. Un pas se considera format din secventa de actualizare a marcajelor p si a cuplului (S,p) (a se vedea algoritmul Dijkstra). Daca numarul maxim de pasi nu depaseste o limita impusa apriori (de exemplu 8-10% din |U|), decidem ca graful G este uniform.
6. Drumuri minime in grafuri orar
Ce este un graf orar?
O retea de cale ferata este modelata cu ajutorul unui graf simetric ponderat. Acest articol descrie modul de rezolvare a urmatoarelor probleme:
- cum se introduc datele pentru un nou mers al trenurilor;
- cum se modeleaza acest mers cu ajutorul unui graf expandat;
- cum se determina drumuri optime (trasee avind timp minim de calatorie) intre doua statii.
Introducerea datelor
Fie un graf simetric ponderat G = (X, U, d) unde:
- X este o multime finita si nevida de noduri, asociata cu multimea statiilor CFR;
- U este o multime de arce care indica legaturi directe intre doua statii: daca (x,y) I U intre x si y nu exista alte statii;
- d este o functie distanta simetrica, d : U N*: d(x,y) = d(y,x) pentru orice (x,y) I U.
Prima problema care trebuie rezolvata este cea a introducerii cit mai comode a datelor despre un mers nou. Pentru fiecare tren se precizeaza: care este traseul acestuia, prin ce statii trece, ora sosirii si plecarii pentru fiecare statie.
Pentru un tren oarecare se introduc statia initiala de plecare si statia finala de sosire. In acest moment s-ar putea determina un drum de distanta minima intre cele doua statii. Dar nu intotdeauna un tren parcurge traseul de distanta minima dintre cele doua statii. Astfel ca, daca traseul trenului difera de cel avind distanta minima, trebuie sa precizam un nod intermediar, sau poate chiar doua. In continuare se determina un traseu de distanta minima care sa treaca prin toate nodurile in ordinea data. In acest scop poate fi folosit algoritmul Dijkstra, deja cunoscut.
Avind toate statiile de pe parcursul unui tren, se pot preciza pentru fiecare statie ora sosirii si ora plecarii. Statia initiala de plecare nu are asociata o ora de sosire, si statia finala de sosire nu are asociata o ora de plecare. De asemenea, este posibil ca o statie intermediara sa nu aiba asociata orele de sosire si plecare, daca trenul nu are oprire in statia respectiva.
Modelare cu ajutorul unui graf expandat
Exista modelari ale problemei mersului trenurilor disponibile pe Internet. Prezentam in continuare un astfel de model (cf Schultz et al), simplificat si completat pentru a modela cit mai bine unele particularitati ale retelei CFR.
Sa presupunem ca avem trei statii: Sa, Sb si Sc, si trei trenuri cu urmatorul program de circulatie:
- T1: (Sa, 8:00) - (Sb, 8:15, 8:20) - (Sc, 8:30);
- T2: (Sb, 12:00) - (Sc, 12:45, 12:50) - (Sa, 13:10);
- T3: (Sc, 14:00) - (Sa, 14:15, 14:20) - (Sb, 14:35).
Pentru fiecare statie, si pentru fiecare moment de sosire si plecare se defineste cite un nod in graful expandat. Astfel vom avea urmatoarele noduri:
- cele asociate statiei Sa: n1(T1,8:00), n2(T2,13:10), n3(T3,14:15), n4(T3,14:20);
- cele asociate statiei Sb: n5(T1,8:15), n6(T1,8:20), n7(T2,12:00), n8(T3, 14:35);
- cele asociate statiei Sc: - n9(T1,8:30), n10(T2,12:45), n11(T2,12:50), n12(T3,14:00).
Se definesc arce in graful expandat astfel:
- arce care indica momente succesive din ruta unui tren:
(n1,n5), (n5,n6), (n6,n9), (n7,n10), (n10,n11), (n11,n2), (n12,n3), (n3,n4), (n4,n8);
- arce care indica legaturi cu alte trenuri:
(n8,n7), (n8,n6), (n5,n7), (n2,n1), (n2,n3), (n4,n1), (n9,n11), (n9,n12), (n10,n12).
In a doua lista se includ arcele care se refera la aceeasi statie si unesc un virf de sosire corespunzind unui tren cu un virf de plecare corespunzind altui tren.
Uneori este necesar sa introducem legaturi suplimentare in graful expandat, pentru a indica faptul ca un tren de legatura trebuie luat dintr-o statie vecina. Exemple: (Ploiesti Vest, Ploiesti Sud), (Bucuresti Nord, Bucuresti Basarab).
In aceste situatii legaturile trebuie sa tina seama de timpul necesar pentru a ajunge dintr-o statie in cealalta cu un alt mijloc de transport (de exemplu autobuz). Aceste arce suplimentare vor fi definite astfel:
- nodul initial al arcului este asociat unui moment de sosire, si nodul final unui moment de plecare;
- se vor avea in vedere acele noduri care corespund unui interval de timp cel putin egal cu cel necesar pentru a parcurge distanta dintre cele doua statii.
Graful expandat G' = (X', U') asociat mersului trenurilor este un graf orientat unde:
- X' este multimea de noduri definite cum s-a aratat mai sus; un nod x' I X' este un triplet (a,b,h) cu semnificatia: a - statie, b - tren, h - ora plecarii sau sosirii;
- U' este multimea de arce definite cum s-a aratat mai sus.
Determinarea traseelor optime intre doua statii
Fiind date doua statii s si t, trebuie sa se determine cit mai multe trasee optime (ca si timp de calatorie) de la s la t. Trebuie sa precizam mai exact ce inseamna traseu optim. Considerind statia s si ora de plecare h, sa se determine un traseu care ne permite sa ajungem in cel mai scurt timp in statia t. Daca vom considera diferite ore de plecare, este posibil sa avem trasee diferite cu durate diferite de calatorie, toate fiind optime conform precizarii de mai sus.
Criteriul de optim este relativ la momentul plecarii. Dar daca se identifica doua trasee diferite, cu momente diferite de plecare, si momentul sosirii coincide, va fi luat in considerare doar acel traseu care are timpul total de calatorie minim.
Pentru a determina traseul optim se utilizeaza algoritmul Dijkstra cu citeva modificari (cf Schultz et al).
Se determina o multime S' X' asociata statiei s care se refera doar la momente de plecare. Se determina de asemenea o multimeT' X' asociata statiei t care se refera doar la momente de sosire.
Pentru fiecare nod s' I S' se determina un traseu optim de la s' la primul nod t' care este depistat in T'. Pentru doua noduri consecutive n1(a1,b1,h1) si n2(a2,b2,h2) timpul se determina astfel:
(1440 h2-h1) mod 1440
daca momentele de timp sint date in minute in intervalul [0,1439].
Diferenta fata de modelul propus de Schultz et al este urmatoarea. Autorii citati propun ca in a doua lista de arce se includ acele arce care se refera la aceeasi statie, si care unesc doua momente consecutive de timp, indiferent de tipul acestora (plecare sau sosire), la care se adauga un arc care uneste ultimul moment de timp cu primul, pentru a da posibilitatea de a obtine legaturi la momentul trecerii de la o zi la alta.
Singurul avantaj
Copyright © 2024 - Toate drepturile rezervate