|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
Aplicatii ale retelelor neuronale in diagnosticul medical
Introducere
In domeniul medical, printre cele mai importante aspecte sunt considerate interpretarile bune de date si stabilirea de diagnostice. Dar luarea deciziilor medicale devine dificila chiar pentru expertii umani care intampina dificultati in cazul cantitatilor mari de date. Deci ar putea beneficia de pe urma unor instrumente care sa-i ajute sa ia decizii bune. Optiunile care se pot folosi sunt fie sistemele expert, fie retelele neuronale artificiale, ambele facand parte din domeniul inteligentei artificiale.
Retelele neuronale artificiale sunt proiectate pentru a simula comportamentul retelelor neuronale biologice din mai multe motive. Conform D Klerfors (1998), retelele neuronale sunt sisteme modelate in parte dupa creierul uman. E o incercare de a simula cu ajutorul hardware si software, nivelurile multiple ale procesarii elementelor numite neuroni. Fiecare neuron e legat la un anumit numar din vecinii sai avand coeficienti variati de conectivitate, care reprezinta puterea conexiunilor. Invatarea este realizata prin ajustarea ponderilor pentru a cauza intreaga retea sa aiba ca iesire rezultatul bun.
Retelele neuronale, cu abilitatea lor remarcabila de a deriva intelesul din date complicate sau imprecise pot fi folosite la extragerea pattern-urilor si la detectarea tendintelor care sunt prea complexe pentru a fi observate fie de oameni fie de alte tehnici computerizate.
Dupa ce Rosenblatt a dezvoltat regula de invatare de baza pentru perceptronul cu un singur nivel in 1962, Minsky si Papert au demonstrat ca aceasta regula nu poate rezolva problemele nonlineare. Putini cercetatori stiintifici si-au mai continuat cercetarile pana in 1982 cand Hopfield a impulsionat din nou dezvoltarea acestui domeniu contribuind cu munca sa in cadrul retelelor neuronale asociative si mai ales la publicarea regulii backpropagation pentru retele feedforward. Aceasta regula si variantele sale au inlesnit utilizarea retelelor in probleme dificile de diagnostic medical.
In cazul retelelor probabilistice, baza teoretica pentru aplicatiile clasificatorului Bayesian (naive Bayes) a fost pusa de Good. Mai tarziu au fost dezvoltate diferite variante si extensii ale acestui clasificator. Cestnik a dezvoltat o m-estimare a probabilitatilor care a imbunatatit semnificativ performanta. Kohonenko a dezvoltat "seminaive Bayes" care detecteaza dependentele dintre atribute. Langelz a dezvoltat un sistem care utilizeaza naive Bayes in nodurile unui arbore de decizie. Pazzani a dezvoltat alta metoda pentru a cauta dependente intre atribute.
Problema majora in domeniul medical este stabilirea si diagnosticarea bolilor. Fiintele umane comit intotdeauna greseli datorita limitarilor lor, diagnosticarea este una dintre cele mai serioase dificultati a expertizei umane. Una din cele mai importante probleme care apare este subiectivitatea specialistului. Poate fi notat ca, in particular, in cadrul activitatilor de recunoastere a pattern-urilor, experienta profesionala este strans legata de diagnosticul final. Aceasta se datoreaza faptului ca rezultatul nu depinde de o solutie sistematizata, ci de interpretarea semnalelor pacientului. (Lanzarini and Giusti, 1999).
Brause spunea ca aproape toti medicii se confrunta in formarea lor de etapa invatarii stabilirii unui diagnostic. Astfel trebuie sa rezolve problema deducerii anumitor boli sau formularii unui tratament bazat pe observatii si cunostinte mai mult sau mai putin specifice. Pentru asta trebuie luate in considerare anumite dificultati. Baza unui diagnostic valid, presupune existenta unui numar suficient de mare de cazuri de experienta, atins doar la mijlocul carierei unui medic, experienta evident neexistenta la momentul terminarii formarii medicale academice. Aceasta lipsa de experienta ridica dificultati si medicilori experimentati in cazul bolilor rare sau noi.
In principiu, sistemul de decizie la oameni nu se aseamana sistemele statistice, ci cu sistemele de recunoastere a pattern-urilor. Oamenii pot recunoaste pattern-uri sau obiecte foarte usor, dar esueaza atunci cand observatiilor le sunt asociate probabilitati.
Brause a oferit spre exemplificarea acestui lucru un studiu din vara anului 1971, care evidentiaza limitarile umane in domeniul diagnosticului. Rezultatul experimentului a fost urmatorul:
Cel mai bun dioagnostic uman (cel mai experimentat fizician)
Calculator cu baza de date expert: 82.2%
Calculator cu date despre 600 de pacienti: 91.1%
Din acest rezultat se poate deduce ca oamenii nu pot analiza ad hoc date complexe fara a comite erori.
O clasa majora in domeniul medical implica diagnosticarea bolilor, bazata pe diferite teste aplicate unui pacient. Atunci cand sunt implicate mai multe teste, diagnosticul final poate fi dificil de obtinut, chiar pentru un medic expert. Asta a dus in ultimele decade la instrumente computerizate de diagnosticare, intentionate pentru ajutarea medicilor la intelegerea datelor complexe. (Kiyan and Yildirim, 2003).
Retelele neuronale sunt extrem de folositoare, deoarece nu numai ca sunt capabile sa recunoasca pattern-uri cu ajutorul unui expert, ci pot de asemenea sa generalizeze informatiile continute in datele de intrare. Pot fi folosite la recunoasterea pattern-urilor datorita abilitatii de a invata si stoca cunostinte. Datorita naturii lor "paralele" ele pot atinge nivele inalte computationale, lucru vital in aplicatiile medicale.
Retelele neuronale si-au dovedit capabilitatile in multe domenii, ele au abilitatea de a invata din exemple, ceea ce le face foarte flexibile si stabile in diagnosticarea medicala.
Retelele neuronale ar putea fi folosite in fiecare situatie in care exista o relatie intre anumite variabile ce pot fi considerate intrari si alte variabile ce pot fi prezise (rezultatele). Cel mai important avantaj in folosirea retelelor neuronale este ca acest tip de sistem rezolva probleme care sunt prea complexe pentru tehnologiile conventionale, ne-avand o solutie algoritmica, sau solutia este prea complexa pentru a fi folosita.
Tehnicile de recunoastere a pattern-urilor sunt deja aplicate in diverse arii ale medicinei, cum ar fi sistemele de diagnosticare, analizele biochimice, analiza imaginilor, dezvoltarea de noi medicamente, analiza electroencefalogramei.
Sistemele de diagnosticare - sunt folosite in mod normal pentru detectarea cancerului si problemelor cardiovasculare.
Analiza biochimica - analiza sangelui, urinei, urmarirea nivelului glucozei la diabetici, detectarea conditiilor patologice - de exemplu tuberculoza.
Analiza imaginilor - aplicatiile din aceasta arie includ detectarea tumorilor in ultra-sonograme, clasificarea radiografiilor pulmonare, clasificarea tesuturilor si vaselor sangvine in imaginile obtinute prin rezonanta magnetica (MRI)
Dezvoltarea de medicamente - aplicatii dezvoltate pentru identificarea de substante ce ar putea trata cancerul sau sida.
Lucrarea de fata trateaza doua tipuri de retele neuronale folosite in invatarea automata pentru rezolvarea problemelor de clasificare (in special pentru diagnosticare) in domeniul medical. Am descris atat partea de preprocesare a datele, formatele standard folosite dar si construirea retelelor si evaluarea performantelor acestora.
In Capitolul 1 se discuta despre tipurile de retele neuronale abordate - feedforward si probabilistice. Capitolul 2 ofera o perspectiva asupra diferitelor metode de preprocesare a datelor de intrare si asupra posibilelor metode de evaluare a performantelor modelelor de retele construite. Pentru ilustrarea acestor idei a fost dezvoltata o aplicatie software, scrisa in limbajul C#. Aplicatia este prezentata in capitolul 3. Ea reprezinta o implementare a celor doua tipuri de retele pentru utilizarea lor pe diferite seturi de date din domeniul mediacal.
Cap 1. Retele neuronale
1.1 Generalitati
RNA (Retele neuronale artificiale) pot fi descrise ca niste modele computationale cu proprietati particulare ca : adaptabilitatea, capacitatea de a invata , de a generaliza sau de a clasifica informatii, aceste operatii fiind bazate pe procesare paralela.
Din punct de vedere functional o retea neuronala este un sistem ce primeste date de intrare (corespunzator datelor initiale ale unei probleme) si produce date de iesire (ce pot fi interpretate ca raspunsuri ale problemei analizate). O caracteristica esentiala a retelelor neuronale este capacitatea de a se adapta la mediul informational corespunzator unei probleme concrete printr-un process de invatare. In felul acesta reteaua extrage modelul problemei pornind de la exemple. Se poate spune ca o retea neuronala construieste singura algoritmul pentru rezolvarea unei probleme, daca ii furnizam o multime reprezentativa de cazuri particulare (exemple de instruire).
Din punct de vedere structural o retea neuronala este un ansamblu de unitati interconectate, fiecare fiind caracterizata de o functionare simpla. Functionarea unitatilor este influentata de o serie de parametri adaptabili. Astfel o retea neuronala este un sistem extrem de flexibil. Structura unitatilor functionale, prezenta conexiunilor si a parametrilor adaptivi precum si modul de functionare sunt inspirate de creierul uman. Fiecare unitate functionala primeste cateva semnale de intrare pe care le prelucreaza si produce un semnal de iesire
Un astfel de sistem invata prin modificarea intensitatii de conexiune dintre elemente, adica schimband ponderile asociate acestor conexiuni. Cunoasterea initiala ce este furnizata sistemului este reprezentata de caracteristicile obiectelor considerate si de o configuratie initiala a retelei.Sistemul invata construind o reprezentare simbolica a unei multimi date de concepte prin analiza conceptelor si contraexemplelor acestor concepte.
O retea neuronala artificiala este un ansamblu de unitati functionale amplasate in nodurile unui graf orientat si intre care circula semnale de-a lungul arcelor grafului. Retelele neuronale artificiale sunt retele de modele de neuroni conectati prin intermediul unor sinapse ajustabile. Toate modelele de retele neuronale se bazeaza pe interconectarea unor elemente simple de calcul dintr-o retea densa de conexiuni.
Elementele definitorii ale unei retele neuronale sunt :
Invatarea supervizata este un tip de invatare inductiva ce pleaca de la un set de exemple de instante ale problemei si formeaza o functie de evaluare (sablon) care sa permita clasificarea (rezolvarea) unor instante noi. Invatarea este supervizata in sensul ca setul de exemple este dat impreuna cu clasificarea lor corecta. Aceste instante rezolvate se numesc instante de antrenament. Formal, setul de instante de antrenament este o multime de perechi atribut-valoare (x,f(x)), unde x este instanta iar f(x) clasa careia ii apartine instanta respectiva. Scopul invatarii este construirea unei functii-sablon care sa clasifice corect instantele-exemplu, iar pentru un x pentru care nu se cunoaste f(x) sa propuna o aproximare cat mai corecta a valorii f(x).
Invatarea nesupervizata elimina complet necesitatea unor instante de antrenament, deci si problemele legate de acestea. Scopul invatarii nesupervizate nu este definit anterior ca un concept tinta, algoritmul fiind lasat singur sa identifice concepte posibile. In general, invatarea nesupervizata presupune existenta unor instante neclasificate, un set de reguli euristice pentru crearea de noi instante si evaluarea unor concepte deduse, eventual un model general al spatiului de cunostinte in care se gasesc aceste instante. Un algoritm de invatare nesupervizata construieste concepte pentru a clasifica instantele, le evalueaza si le dezvolta pe cele considerate interesante de regulile euristice. In general, concepte interesante sunt considerate cele care acopera o parte din instante, dar nu pe toate. Invatarea nesupervizata permite identificarea unor concepte complet noi plecand de la date cunoscute
1.1.1 Parti componente
1.1.2 Unitatile de procesare
primeste inputurile de la vecini sau din surse externe
foloseste acest input pentru a calcula un semnal de output
propaga acest semnal de output spre alte unitati
uneori ajusteaza ponderile
1.1.3 Conexiunile dintre unitati
In majoritatea cazutilor se presupune ca fiecare unitate aduce o contributie inputului unitatii cu care e conectata. Acest input al unitatii k este suma ponderala a outputurilor din toate celulele conectate plus un offset .
sk(t)= wjk(t)yj(t) + k(t).
Unitatile cu regula de propagare s.n. unitati sigma.
O regula diferita de propagare a fost introdusa de Feldman si Ballard (1982) - propagarea pentru unitatea sigma-pi :
sk(t) = wjk(t) yjm(t) + k(t).
Desi aceste unitati nu sunt frecvent folosite au valoare pentru implementarea tabelelor de look-up si gating al inputului.
1.1.4 Activarea si regulile de output
Este necesara o regula care da efectul a inputului total asupra unitatii de activare - Fk - functie care preia inputul total sk(t) si activarea curenta yk(t) si produce o noua valoare de activare a unitatii k:
yk(t+1)=Fk(yk(t), sk(t)).
De obicei functia de activare este o functie nedescrescatoare a totalului inputului unei unitati.
yk(t+1)=Fk(sk(t))=Fk( wjk(t)yj(t)+ k(t)).
Cu toate ca functiile de activare nu sunt restrictionate la funtii nedescrescatoare. In general un fel de functie de prag este folosita: o functie de prag puternic limitatoare (o functie sgn - signum) sau o functie liniara sau semiliniara, sau o functie de prag usor limitatoare - functii sigmoide.
Ex . yk=F(sk)=1/(1+e-sk) (functie sigmoidala)
Functii hiperboidale tangente cu valori intre [-1,1].
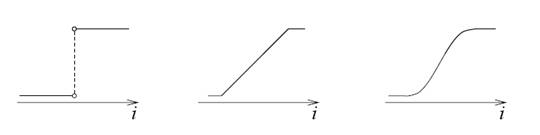
a) functia sgn b) functia semi-lineara c) functia sigmoida
Fig. 1.1 Diferite functii de activare pentru o unitate
In anumite cazuri output-ul unei unitati poate fi o functie stohastica a totalului inputului corespunzator unitatii. In acest caz activarea nu e de determinata deterministic de neuronul de input, ci neuronul de input determina probabilitatea p a a unui neuron de a primi o valoare mare de activare:
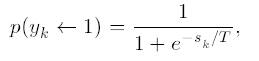
in care T este parametrul care determina curba functiei de probabilitate.
In acest capitol voi prezentata doua arhitecturi de retele neuronale, retelele feedforward si retelele probabiliste.
1.2 Retele Feedforward
1.2.1 Retele neuronale feedforward uninivel
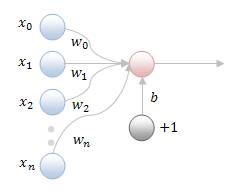
Fig.1.1 Diagrama schematica a unei retele neuronale feedforward uninivel, x-valorile de intrare, w-ponderile si unitatea fictiva
Aceste retele realizeaza o propagare inainte a intrarilor, intr-un singur pas. Unitatile de prelucrare din cadrul unei retele feedforward uninivel sunt in general neuroni treapta, cu domeniu real al valorilor de intrare si cu domeniu binar (0,1) sau bipolar (-1,1) al valorilor de output.
Conditia de activare a unei unitati de output Uj (de fixare a unitatii Uj pe valoarea 1) este:
![]() ,
unde i desemneaza o unitate de input
,
unde i desemneaza o unitate de input
Valoarea de activare 1 a unei unitati de output Uj poate primi semnificatia incadrarii vectorului de intrare intr-o clasa, sa spunem A, in timp ce valoarea de activare -1/0 poate avea semnificatia clasificarii vectorului de intrare intr-o alta clasa, sa spunem B.
Ecuatia:![]() formeaza un hiperplan in spatiul
n-dimensional, ce separa acest spatiu in doua regiuni. Cand spatiul este
bidimensional, hiperplanul devine o linie.
formeaza un hiperplan in spatiul
n-dimensional, ce separa acest spatiu in doua regiuni. Cand spatiul este
bidimensional, hiperplanul devine o linie.
Datorita restrictiilor de configuratie, retelele feedforward uninivel nu sunt capabile sa realizeze decat o clasificare pe clase liniar separabile. Separabilitatea liniara se refera la existenta unui hiperplan liniar, ce permite izolarea instantelor unei clase intr-o regiune distincta de cea in care sunt plasate instantele celeilalte clase.
1.2.1.1 Algoritmi de instruire a retelelor feedforward uninivel
Se cunosc mai multi algoritmi de instruire a retelelor feedforward uninivel. Cel mai cunoscut este algoritmul perceptronului. Pentru simplificarea algoritmilor de instruire a retelelor uninivel, biasul unitatilor din retea se exprima ca intensitati ale unor conexiuni din retea. Practic, biasul unei unitati Uj se rescrie, sub forma negativului intensitatii unei conexiuni ce leaga unitatea respectiva de o unitate de input fictiva,UF ce livreaza unitatii Uj input 1 (xF=1).
![]()
Acest
lucru permite simplificarea scrierii conditiei de activare a unei unitati Uj, sub forma:![]() , unde i desemneaza o unitate de input,
inclusiv UF. In acest fel, parametrii ajustabili ai retelei pot fi
considerati ca reprezentand numai intensitati ale conexiunilor din
retea.
, unde i desemneaza o unitate de input,
inclusiv UF. In acest fel, parametrii ajustabili ai retelei pot fi
considerati ca reprezentand numai intensitati ale conexiunilor din
retea.
Algoritmul perceptronului presupune parcurgerea urmatoarelor etape :
1. Initializarea intensitatilor conexiunilor din retea (in general, ca numere aleatoare mici)
2. Pentru fiecare exemplu de instruire sau epoca de instruire, pana la scaderea sumei patratelor erorilor sub o limita considerata ca acceptabila:
2.1. Calculul activarilor pentru toate unitatile din retea.
2.2. Ajustarea intensitatilor conexiunilor, conform relatiei:
![]() , unde t semnifica pasul de timp
, unde t semnifica pasul de timp
Marimea modificarii intensitatii conexiunii se poate calcula dupa mai multe reguli si anume:
- regula percepronului:
![]()
unde dj, denumit termen eroare se calculeaza dupa relatia:
dj=tj-Oj, tj reprezintand outputul dorit pentru unitatea Uj
- regula delta:
![]() , unde h reprezinta o valoare pozitiva,
, unde h reprezinta o valoare pozitiva,
subunitara, denumita rata de instruire.
1.2.1.2 Teorema de convergenta a perceptronului
Daca datele care trebuie clasificate sunt liniar separabile, regula de instruire a perceptronului va converge la solutie (valorile parametrilor care asigura o clasificare corecta a datelor) intr-un numar finit de pasi, indiferent de alegerea initiala a valorilor parametrilor.
1.2.2 Retele feedforward multinivel
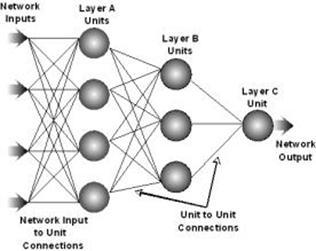
Fig. 1.2 Arhitectura unei retele feedforward multinivel
Retelele multinivel reprezinta retele neuronale feedforward cu cel putin un nivel intermediar. Aceste retele pot trata probleme de clasificare neliniare, deoarece determina formarea unor regiuni de decizie mai complexe decat hiperplanul. Fiecare nod de pe primul nivel ascuns determina crearea unui hiperplan. Fiecare nod de pe al doilea nivel ascuns combina hiperplanele pentru a crea regiuni de decizie convexe, in timp ce fiecare nod din al treilea nivel ascuns combina regiunile convexe pentru a forma regiuni concave. Prin utilizarea unui numar suficient de mare de niveluri si de unitati pe fiecare nivel este posibil sa se formeze orice regiune de decizie. O problema importanta in utilizarea retelelor feedforward este determinarea numarului de neuroni ascunsi necesar pentru realizarea clasificarii. Acest numar nu se poate determina decat experimental.
1.2.2.1 Instruirea retelelor feedforward multinivel
Retelele feedforward multinivel sunt instruite prin metode supervizate, care presupun utilizarea unor instante de instruire de forma:
(Xp, tp),
unde:
![]() reprezinta vectorul intrarilor
pentru instanta
de instruire p;
reprezinta vectorul intrarilor
pentru instanta
de instruire p;
![]() este vectorul outputurilor dorite pentru
instanta
p;
este vectorul outputurilor dorite pentru
instanta
p;
N este numarul unitatilor de intrare din cadrul retelei;
M este numarul unitatilor de iesire.
Considerand F(X) functia de prelucrare asociata problemei, functie de calcul a rezultatelor pe baza datelor de intrare,X, atunci:
![]()
Outputul obtinut prin prelucrarea datelor de intrare cu ajutorul retelei neuronale este notat cu:
![]()
Op poate fi considerat drept rezultatul prelucrarii datelor de intrare, Xp, cu ajutorul functiei Fw(w;Xp), functie implementata prin retea, ca o aproximare a lui F(X). Prin urmare:
![]()
Eroarea
inregistrata
la prelucrarea prin retea a vectorului de intrare Xp ,
eroare masurata
la nivelul unei unitati de output ![]() si notata
cu
si notata
cu ![]() ,
se exprima
ca diferenta
intre
outputul dorit si
cel efectiv obtinut,
respectiv:
,
se exprima
ca diferenta
intre
outputul dorit si
cel efectiv obtinut,
respectiv:
![]()
Eroarea
Ep, inregistrata
la prelucrarea prin retea a vectorului de intrare Xp si
stabilita
la nivelul intregii
retele
neuronale, se obtine
prin combinarea erorilor ![]() , pe baza unei relatii
de forma:
, pe baza unei relatii
de forma:
![]()
Pentru calculul erorii Ep pot fi utilizate diferite functii eroare, f, dintre care se pot aminti:
a) norma-L1:
![]()
b) norma-L2:
![]()
c) functie logistica de forma:
![]() , cu b > 0
, cu b > 0
d) functia Huber nesaturata:
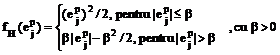
e) functia Huber saturata (functia Talvar):
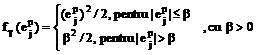
f) functia Hampel:
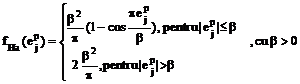
Functiile a) si b) dau masuri euclidiene ale erorii, in timp ce functiile c)-f) permit obtinerea unor masuri neeuclidiene, care se recomanda a fi utilizate in cazul existentei unui zgomot negaussian in datele de intrare.
Instruirea retelelor neuronale feedforward multinivel urmareste minimizarea erorii in functionarea retelei, eroare notata cu E si calculata la nivelul unui ansamblu de instante de instruire dupa relatia:
![]()
Instruirea retelelor neuronale feedforward multinivel urmareste minimizarea erorii E, de functionare a retelei, in raport de parametrii W. Minimizarea erorii se poate realiza prin:
metode deterministe (de ordinul intai, cum ar fi metoda coborarii gradientului functiei eroare sau metode de ordinul doi, precum: metoda gradientului conjugat, metoda Newton, metoda cvasi-Newton, metoda pseudo-Newton);
metode nedeterministe.
In cele ce urmeaza se va prezenta modul de aplicare a metodei coborarii gradientului pentru minimizarea, in raport de W, a unei functii eroare de forma:
![]()
Aceasta metoda de minimizare a unei functii eroare, de forma celei mentionate anterior, sta la baza celui mai cunoscut algoritm de instruire a retelelor feedforward multinivel, algoritm cunoscut sub numele de algoritmul backpropagation standard. Aplicarea metodei coborarii gradientului pentru minimizarea unei functii eroare de tip neeuclidian este realizata prin algoritmi backpropagation nestandard.
1.2.3 Regula de ajustare a parametrilor W pentru algoritmul backpropagation standard
O functie J(V) este minimizata in raport de V prin metoda coborarii gradientului astfel:
se initializeaza solutia (valoarea lui V care minimizeaza J) cu V0 (de regula, V0 se stabileste arbitrar);
se ajusteaza solutia, prin coborarea gradientului functiei J, conform relatiei:
V= -J(V)
unde: J reprezinta gradientul functiei J, iar reprezinta pasul de deplasare pe directia de gradient. Altfel spus, considerand k drept iteratia curenta, ajustarea solutiei se realizeaza dupa formula:
Vk+1=Vk - kJ(Vk)
In procesul de instruire a retelelor feedforward multinivel, functia care trebuie minimizata este functia eroare, Ep, iar minimizarea se realizeaza in raport de parametrii wji ai retelei. Deci:
![]()
E este functie de t si O. O la randul sau este functie de wji. E este deci o functie compusa de mai multe variabile, iar calculul derivatei partiale a lui E in raport de wji se poate realiza conform formulei:
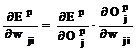
In cazul in care Uj este unitate de output, atunci:
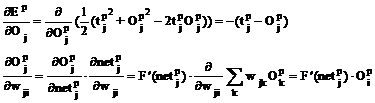
Deci:
![]()
Notand cu:
![]()
atunci:
![]()
Prin urmare, regula de ajustare a parametrilor wji ca urmare a prelucrarii instantei de instruire p poate fi exprimata sub forma:
![]()
In cazul in care Uj reprezinta o unitate ascunsa atunci:
![]()
Uk reprezentand unitatile ce beneficiaza de outputul lui Uj.
Consideram unitatea Uj drept o unitate ascunsa situata pe stratul de output aflat imediat inaintea stratului de output. In acest caz, unitatile Uk care beneficiaza de outputul unitatii Uj sunt unitati de output. Prin urmare:
![]()
Totodata:
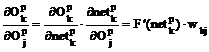
Deci:
![]()
Notand cu:
![]()
se obtine:
![]()
Totodata:
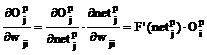
Rezulta ca:
![]()
Notand cu:
![]()
se obtine:
![]()
Prin urmare si in acest caz regula de ajustare a parametrilor wji se poate scrie tot sub forma:
![]()
Considerand unitatea Uj drept o unitate ascunsa situata pe un strat de output care nu se afla imediat inaintea stratului de output se va proceda similar, obtinandu-se aceeasi forma pentru regula de ajustare a parametrilor wji.
Observatii
a) Forma regulii de ajustare a parametrilor wji nu se modifica in cazul in care Uj reprezinta o unitate plasata pe un strat ascuns ce nu precede imediat stratul de output.
b) Regula de ajustare a parametrilor wji din cadrul algoritmului backpropagation standard este cunoscuta si sub numele de regula delta generalizata.
c)
Calcularea lui ![]() impune determinarea derivatei de ordinul intai
a functiei
de activare a unitatii Uj. Considerand, de exemplu,
o functie
de activare logistica sigmoida, de forma:
impune determinarea derivatei de ordinul intai
a functiei
de activare a unitatii Uj. Considerand, de exemplu,
o functie
de activare logistica sigmoida, de forma:
![]()
atunci:
![]()
Deoarece x reprezinta inputul net, iar F(X) este nivelul de activare al unitatii, se poate scrie in acest caz ca:
![]()
1.3 Retele neuronale probabilistice
Retelele neuronale probabiliste au fost introduse in 1990 de Specht. Au castigat interes pentru ca ofera un mod de a interpreta structura retelei sub forma unei functii de densitate de probabilitate si performanta lor este in cele mai multe cazuri superioara performantei altor retele de clasificare.
Acest tip de retele ofera o solutie generala problemelor de clasificare a pattern-urilor, urmand o abordare dezvoltata in statistica, numita clasificatori Bayesiani. Teoria Bayes, dezvoltata in anii 1950, ia in considerare posibilitatea relativa de producere a evenimentelor si foloseste informatie a priori pentru imbunatatirea predictiei. Paradigma retelei foloseste de asemenea estimatori Parzen care au fost dezvoltati pentru a construi densitatea probabilitatii functiilor necesare teoriei Bayes.
Modelarea retelelor neuronale cu ajutorul teoriei probabilitatilor sau a teoriilor de incertitudine aduce o serie de avantaje fata de abordarile strict deterministe. Acestea sunt:
reprezentarea mai veridica a modului de functionare a retelelor neuronale biologice, in care semnalele se transmit mai ales ca impulsuri;
eficienta de calcul mult superioara celei din cadrul retelelor neuronale Back-Propagation;
implementare hardware simpla pentru structuri paralele;
instruire usoara si cvasiinstantanee, rezultand posibilitatea folosirii acestor retele neuronale in timp real;
forma suprafetelor de decizie poate fi oricat de complexa prin modificarea unui singur parametru (de netezire), aceste suprafete putand aproxima optim suprafetele Bayes;
pentru statistici variabile in timp, noile forme pot fi suprapuse simplu peste cele vechi;
comportare buna la forme de intrare cu zgomot sau incomplete.
Retelele neuronale probabiliste reprezinta un caz particular de retele RBF pentru care numarul de unitati ascunse coincide cu numarul de exemple din setul de antrenare iar centrii (vectorii cu ponderile corespunzatoare unitatilor ascunse) coincid cu vectorii de intrare din setul de antrenare. Diferenta principala dintre retelele clasice RBF si PNN este urmatoarea: intre nivelul ascuns si cel de iesire exista o conexiune partiala, reteaua avand k(numarul de clase) iesiri ce sunt calculate ca fiind probabilitatea conditionala pentru fiecare clasa. Spre deosebire de retelele RBF clasice, PNN sunt folosite doar pentru clasificare.
Comparatia intre celelalte retelele neuronale si retelele probabilistice poate fi facuta la nivelul reprezentarii si a sistemului de invatare.
La nivelul reprezentarii, ambele tipuri de retele se bazeaza pe atributele instantelor. Ambele pot lucra cu intrare discreta sau continua. Diferenta principala este aceea ca in retelele probabilistice reprezentarea unui sablon este localizata, in timp ce in retelele neuronale reprezentarea este distribuita in toata reteaua.
Dezvoltarea retelelor probabiliste porneste de la clasificatorul Parzen Windows. Metoda Parzen Windows este o procedura non-parametrica care estimeaza o functie de densitate de probabilitate(pdf), decizia clasificarii fiind luata dupa calcularea pdf-ului pentru fiecare clasa folosindu-se intregul set de antrenare.
Calculul lui pdf se face cu urmatorul algoritm: se aduna toate valorile gaussiene evaluate pentru fiecare exemplu de antrenare, iar aceasta suma este scalata pentru a produce probabilitatea estimata:
fk( x ) = ( 1/( 2p )d/2 sd) ( 1/N ) Si=1Nk exp[ - ( x-xki )T ( x-xki ) / ( 2s
unde xki este al i-lea exemplu din clasa k.
Decizia clasificarii este luata in acord cu inegalitatea:
S i=1Nk exp[ - ( x-xki)T ( x-xki ) / ( 2s )] >= S i=1Nj exp[ - ( x-xji)T ( x-xji ) / ( 2s ) ], j=1,, K (numarul claselor).
unde N este numarul de exemple din setul de antrenare iar Nk numarul de exemple din clasa k.
Volumul de calcule efectuate este proportional cu dimensiunea setului de antrenare.
Retelele neuronale probabiliste invata sa aproximeze pdf-ul pentru fiecare exemplu. O astfel de retea este alcatuita din noduri alocate pe trei nivele:
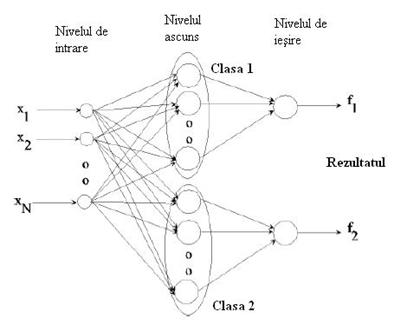
Figura 1.2 Arhitectura unei retele neuronale probabilistice
Figura 1.2 descrie arhitectura pentru o retea probabilista care recunoaste k = 2 clase, dar poate fi extinsa la oricate k clase. Nivelul de intrare, cel din stanga contine N noduri: cate unul pentru fiecare element al vectorului de intrare x. Fiecare nod din nivelul de intrare este conectat cu toate nodurile din nivelul ascuns, astfel incat fiecare nod ascuns primeste intregul vector de caracteristici x. Nodurile din nivelul ascuns sunt grupate: cate un grup pentru fiecare din cele k clase. Fiecare nod ascuns din clasa k corespunde unei functii gaussiene centrata pe vectorii de intrare din clasa k. La iesirea pentru fiecare clasa k toate valorile functiei gaussiene pentru clasa k sunt adunate, iar suma este scalata.
1.3.1 Arhitectura unei retele PNN
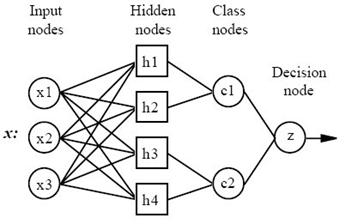
Figura 1.3 Arhitectura unei retele neuronale probabilistice cu 4 nivele
Un alt tip de arhitectura presupune existenta a 4 nivele:
Nivelul de Intrare: - exista un neuron in nivelul de intrare pentru fiecare variabila predictor. In cazul variabilelor ce tin de o categorie, sunt folositi N-1 neuroni, unde N este numarul de categorii. Neuronii de intrare (sau preprocesarea) standardizeaza raza valorilor scazand mediana si divizand prin intercuartila. Neuronii de input predau mai departe valorile fiecarui neuron de pe nivelul ascuns.
Nivelul ascuns: - Acest nivel are un neuron pentru fiecare caz din setul de antrenare. El stoceaza valorile variabilei predictor pentru cazuri, si valoarea target. Pentru un vector x de intrare, neuronul de pe nivelul ascuns calculeaza distanta euclidiana a cazului test de la centrul neuronului iar apoi aplica functia nucleu a RBF, folosind valoarea sigma. Rezultatul obtinut este pasat nerunilor din nivelul de pattern.
Nivelul de pattern (nivelul de sumatie): - Pe acest nivel exista un neuron de pattern pentru fiecare categorie. Valoarea ponderilor ce iese dintr-un neuron de pe nivelul ascuns este pasata doar neuronului de pattern care corespunde cu categoria neuronului de pe nivelul ascuns. Neuronul de pattern aduna valorile pentru clasa pe care o reprezinta.
Nivelul de decizie: - Nivelul de decizie compara ponderile pentru fiecare categorie acumulate pe nivelul de pattern, si foloseste votul cel mai larg pentru a prezice categoria target.
Pe nivelul ascuns exista un element de procesare pentru fiecare vector de input din setul de antrenare. In mod normal trebuie sa existe un numar egale de elemente de procesare pentru fiecare clasa, altfel una sau mai multe clase pot fi denaturate, reteaua generand rezultate proaste. Fiecare element de procesare de pe nivelul ascuns e antrenat o data. Un element e antrenat pentru a genera o valoare inalta de output atunci cand un vector de input se potriveste cu un vector de antrenare. Functia de antrenare poate include un factor global de netezire pentru a generaliza mai bine rezlutatele clasificarii. In orice caz, vectorii de antrenare nu trebuie sa fie in vreo ordine speciala in setul de antrenare. Functia de invatare selecteaza pur si simplu primul element de procesare neantrenat din clasa corecta de output, si ii modifica ponderile pentru a se potrivi cu vectorul de antrenare.
Nivelul de pattern opereaza competitiv, doar cea mai buna potrivire cu un vector de input castiga si genereaza un output. In felul acesta, doar o categorie de clasificare este generata pentru un vector de input dat. Daca inputul nu se potriveste cu nici un pattern programat pe nivelul ascuns, nu este generat nici un output.
Vectorul ce va fi folosit ca intrare necesita aplicarea procesului de normalizare pentru a oferi o separare buna a obiectelor din pattern.
Retelele probabilistice folosesc un set de antrenare supervizata pentru a dezvolta functiile de distributie din cadrul unui nivel de pattern. Aceste functii sunt folosite la estimarea probabilitatii unui input de a fi parte dintr-o categorie sau clasa invatata. Pattern-urile invatate pot fi de asemenea combinate, sau masurate, prin probabilitatea a priori - denumita si frecventa relativa - a fiecarei categorii pentru a determina cea mai probabila clasa pentru un anumit vector de input. Daca frecventa relativa a categoriilor este necunoscuta, atunci se poate presupune ca toate categoriile au probabilitati egale, iar determinarea categoriilor e bazata doar pe apropierea vectorului de input de functia de distributie a unei clase.
Antrenarea retelelor probabilistice e mult mai simpla decat a retelelor cu back-propagation. Totusi nivelul ascuns poate deveni destul de extins daca distinctia dintre categorii este variata si in acelasi timp destul de similara in anumite arii. Exista multe propuneri pentru acest tip de retele, avand in vedere ca baza optimizarilor vine din matematica.
|
Unul din dezavantajele modelelor PNN este marimea lor, datorate faptului ca exista un neuron pentru fiecare rand de antrenare. Acesta determina ca modelul sa functioneze mai incet ca perceptronul multinivel cand se foloseste scorarea pentru prezicerea valorilor pentru noile randuri. 1.3.2 Eliminarea neuronilor inutili Eliminarea neuronilor inutili are trei beneficii: Marimea modelului stocat este redusa Timpul necesar aplicarii modelului este redus Scoaterea neuronilor imbunatateste adesea acuratetea modelului Procesul eliminarii neuronilor inutili este un proces iterativ. Validarea "leave-one-out" este folosita pentru masurarea erorii modelului pentru fiecare neuron eliminat. Neuronul care produce cea mai mica crestere a erorii (sau eventual ce mai mare reducere a erorii) este scos din model. Procesul este repetat cu neuronii ramasi pana cand criteriul de oprire este satisfacut. Exista trei criterii care pot fi selectate pentru a ghida eliminarea neuronilor: Minimizarea erorii - daca aceasta optiune este selectata, algoritmul va elimina neuronii atata timp cat eroarea pentru "leave-one-out" ramane constanta sau scade. Se opreste cand detecteaza un neuron a carui eliminare ar putea cauza cresterea erorii. Minimizarea neuronilor - daca aceasta optiune este selectata, algoritmul elimina neuroni pana cand eroarea la "leave-one-out" depaseste eroare din modelul ce cuprinde toti neuronii. Numarul neuronilor - daca aceasta optiune este selectata algoritmul elimina cel mai semnificant neuron pana ce ramane numarul specificat de neuroni. 1.3.3 Comparatie intre retelele PNN si retelele Feedforward |
Avantajele retelei PNN:
Antrenarea e mai rapida
Rezultatele sunt mai precise
Sunt mai putin senzitive la outliers (puncte wild)
Retelele PNN genereaza scoruri de probabilitate target prezise precis
Dezavantajele retelei PNN:
Retelel PNN sunt mai incete la clasificarea de noi cazuri
Au nevoie de mai mult spatiu de memori pentru a stoca modelul
Cap 2. Preprocesarea datelor medicale si evaluarea rezultatelor
2.1 Recunoasterea pattern-urilor - Data mining
Una dintre cele mai mari provocari ale erei informatice este gasirea de pattern-uri, tendinte si anomalii in seturile de date ce devin din ce in ce mai mari si consistente.
In cazul oamenilor in spatele unui proces de identificare considerat obisnuit, cum ar fi recunoasterea unei fete sau citirea caracterelor scrise de mana, sau identificarea prin simt a unor obiecte, etc. , se ascunde de fapt un proces complex. Aceste activitati apartin vietii de zi cu zi, fiind necesare in interactiunea cu mediul. Eficienta cu care oamenii desfasoara aceasta activitate este remarcabila.
O provocare continua pentru sistemle automate inteligente o reprezinta dezvoltarea metodelor capabile de a simula cele mai variate forme ale recunoasterii obiectelor. In aceste sisteme obiectele sunt reprezentate intr-un mod convenabil pentru tipul de procesare pentru care sunt destinate. Aceste reprezentari se numesc pattern-uri.
Recunoasterea pattern-urilor poate fi definita ca asignarea unui obiect fizic sau unui eveniment unei categorii prespecificate. Aceasta presupune implementarea de metode atat pentru descrierea obiecteleor cat si pentru clasificarea lor. Urmareste proiectarea si implementarea algoritmilor care sa simuleze abilitatea umana de a descrie si clasifica obiecte. Este un domeniu de cercetare care are multiple legaturi cu alte discipline.
In medicina, in mod caracteristic avem de a face cu cantitati enorme de date, fie ele sub forma de imagini, numerice sau nominale.
Recunoasterea pattern-urilor depinde de perceperea inter-relatiilor dintre observatii separate. Ea are un rol central in stiinta medicala. Exista tehnici statistice ce pot defini pattern-urile structurale din cadrul unui set de observatii, si pot asigna ponderile potrivite importantei contributiei fiecarei variabile la pattern.
In ceea ce priveste data mining, acest proces presupune extragerea din date a informatiei in prealabil necunoscuta si potentia folositoare.
Ideea centrala in data mining este construirea de programe care analizeaza baze de date in mod automat, cautand regularitati sau pattern-uri. Pattern-urile "puternice" identificate vor fi folosite pentru predictii precise asupra unor date viitoare.
Problemele potentiale care pot aparea sunt datorate existentei de pattern-urilor superficiale, a coincidentelor accidentale din setul de date, denaturarea datelor disponibile (date inexacte, date lipsa, etc). Algoritmii folositi trebuie sa fie destul de stabili pentru a depasi si trata seturile de date imperfecte, si a fi capabili de a extrage pattern-uri folositoare.
Procesul de data mining automatizeaza descoperirea unor relatii si combinatii in cadrul datelor brute, rezultatele obtinute putand fi mai apoi incadrate intr-un sistem automat de suport a deciziei.
Fundamentul tehnic al procesului de data mining este invatarea automata. Prin invatare automata se presupune achizitionarea de descrieri structurale din exemple. Rezultatele invatarii poti fi folosite fie pentru predictii (asupra ce se va intampla in situatii noi pornind de la exemple ce descriu situatii din trecut) sau acestea pot construi o descriere actuala a unei structuri ce poate fi folosita pentru clasificarea altor exemple decat cele folosite in procesul invatarii.
In cadrul domeniului medical data miningul este util la prelucrarea bazelor de date ce contin dosarele computerizate ale pacientilor, sau la prezicerea evolutiei unei boli, la definirea modelelor de comportare ale pacientilor de risc,etc.
Metodele data mining provin din calculul statistic clasic, din administrarea bazelor de date si din inteligenta artificiala. Ele nu inlocuiesc metodele traditionale ale statisticii, ci sunt considerate a fi extinderi ale tehnicilor grafice si statistice. Deoarece softului ii lipseste intuitia umana (pentru a face recunoasterea a ceea ce este relevant de ceea ce nu este), rezultatele metodelor data mining vor trebui supuse in mod sistematic unei supravegheri umane.
Structura tipica de date potrivita pentru data mining contine observatiile (cazurile, de exemplu referitoare la pacienti) plasate pe linii iar variabilele plasate pe coloane.
Modelele identificate de o metoda de data mining vor putea fi transformate in cunostinte doar dupa o validare corespunzatoare.
2.2 Preprocesarea datelor
Preprocesarea datelor reprezinta un pas fundamental in proiectarea aplicatiilor de identificare si manipulare a pattern-urilor. O preprocesoare riguroasa si bine structurata asigura o acuratete mai buna a rezultatelor oferite de aplicatii.
Pregatirea datelor pentru aplicatii urmeaza urmatorii pasi:
Preprocesare - eliminarea datelor care nu sunt necesare:
o verificarea consistentei
o detectarea datelor eronate si eliminarea lor
o eliminarea valorilor extreme (outliers)
Transformarea variabilelor - prin standardizare;
Separarea bazei de date in trei categorii distincte de date:
o Categoria pentru antrenament
o Categoria pentru validare
o Categoria pentru testare
Folosirea statisticilor descriptive clasice simple: media, mediana, amplitudinea,
abaterea standard, cuartilele
Folosirea diagramelor simple
o histograme ale frecventelor - distributia valorilor variabilelor continue
o box plot-uri - sumarizeaza (vizual) mai multe aspecte importante ale unei variabile continue (mediana, cuartilele, extremele)
o diagrame cu bare - prezinta diferentele intre diversele grupuri, pentru variabile categoriale, calitative
o diagrame radiale - compara intre ele nivelurile claselor unei variabile calitative
In continuare se vor parcurge diferitele forme in care se prezinta datele de intrare.
Intrarea se defineste in termeni de concepte, instante si atribute.
1. Conceptul
Ideea de concept este greu de definit foarte precis. Intr-un anume sens, ceea ce dorim sa aflam - rezultatul procesului de invatare - este o descriere a conceptului. Tinand cont de tipul de invatare implicat, numim ceea ce se invata concept si output-ul produs de schema de invatare descrierea conceptului.
2. Instantele
Datele de intrare reprezinta un set de instante. Desi ele se numesc exemple termenul de instata este mai specific. Fiecare instanta este un exemplu individual, independent al conceptului care se vrea invatat. Fiecare instanta este caracterizata prin valorile unui set de atribute determinate. Set de date poate fi reprezentat ca o matrice de instante versus atribute.
3. Atributul
Fiecare instanta individuala, independenta este caracterizata prin valorile unui set predefinit de trasaturi sau atribute.
Valoarea unui atribut este o masura pentru ceea ce face referire atributul. In general exista doua categorii de atribute - nominale si numerice. Atributele numerice numite uneori si atribute continue masoara numere - atat valori reale cat si intregi. Atributele nominale iau o valoare dintr-un set finit (si predefinit) de posibilitati specificate si sunt numite uneori categoriale.
2.2.1 Pregatirea inputului
Uneori etapa de preprocesare a datelor ocupa pana la 50% din procesul de data mining. Este necesara asamblarea datelor intr-un set de instante.
Exista anumite criterii ajutatoare la selectia datelor necesare:
determinarea atributelor necesare pentru un anumit obiectiv
determinarea numarului de atribute ce pot fi prelucrate cu tehnicile alese
determinarea fisierelor si tabelelor ce prezinta interes pentru prelucrare, si a datelor din aceste fisiere si tabele care sunt relevante.
Principalul criteriu pentru asigurarea calitatii rezultatelor este asigurarea calitatii datelor
Majoritatea seturilor de date nu sunt corecte sau complete. Ele se confrunta cu urmatoarele probleme:
date inconsistente - pot aparea in special in cazul in care datele au fost integrate din mai multe surse de date. Aceste inconsistente trebuiesc eliminate inaintea inceperii prelucrarii datelor. Neeliminarea lor duce la aparitia unor valori in plus, incorecte.
date lipsa - cele mai multe seturi de date intalnite in practica contin valori lipsa. Acestea sunt frecvent indicate printr-o intrare care fie depaseste limitele domeniului de definitie, fie constituie o exceptie de la tipul de date asteptat. Problema ce se ridica este ca procentul de date lipsa sa fie acceptabil pentru a nu produce perturbatii in cadrul prelucrarilor.
o Tratarea datelor lipsa se poate face prin diferite metode:
inlaturarea in intregime a unei inregistrari cu date lipsa. Optiune este utila doar in cazul in care numarul de linii cu inregistrari lipsa este mic. Se opteaza pentru acest mod de tratare in special cand exista mai multe atribute lipsa pentru aceasi inregistrare.
inlaturarea in intregime a atributului. Este o optiune viabila doar daca atributul respectiv nu este relevant pentru prelucrari.
pastrarea inregistrarii cu date lipsa. Poate fi aplicata doar in cazul in care algoritmii ce vor fi folositi in prelucrare pot trata date lipsa. Ele vor fi inlocuite intr-un mod compatibil prelucrarilor ce vor urma (pentru fisier ARFF se foloseste "?"). Trebuie analizat modul in care existenta datelor lipsa va afecta prelucrarile ca ansamblu;
completarea datelor lipsa pentru valori numerice:
Inlocuirea valorii lipsa cu mediana
Inlocuirea valorii lipsa cu media
Inlocuirea valorii lipsa cu o alta marime aleasa de analist
completarea datelor lipsa pentru valori nominale:
Inlocuirea valorii lipsa cu mediana
Crearea unei categorii noi ("null")
date cu deviatie mare - valori inexacte sau in afara campului permis, pot fi depistate trasand graficul pentru fiecare variabila in parte. O valoare necorespunzatoare va prezenta o deviatie mare de la patternul format de celelalte variabile.
date aberante - presupun existenta unei erori mai mari ca in cazul datelor cu deviatie mare, desi in unele cazuri se pot trata similar. Exemplu: data aberanta pentru varsta ar fi 200 (in timp ce data cu deviatie mare poate fi doar 95).
date cu zgomot - "zgomotul" poate fi un element perturbator in datele prelucrate, sau poate fi un fenomen neprevazut in setul de date.
Rezultatul etapei de preprocesare trebuie sa fie un fisier / baza de date compatibil cu softul care va fi folosit pentru prelucrari.
Pentru aplicatie se va folosi reprezentarea standard a seturilor de date - fisiere ARFF (Attribute-Relation File Format
2.2.2 Fisierele ARFF
Fisierele ARFF sunt fisiere text ASCII, ce descriu o lista de instante ce au in comun un set de atribute.
Au fost dezvoltate in cadrul Departamentului de Informatica al Universitatii din Waikato pentru a fi utilizate de Weka, o aplicatie software scrisa in Java ce implementeaza o colectie de algoritmi pentru sarcinile de data mining. Weka contine tool-uri petru preprocesarea datelor, clasificare, regresie, clustering, reguli de asociere si de asemenea pentru vizualizarea rezultatelor.
2.2.2.1 Structura fisierelor ARFF
Un fisier ARFF are doua sectiuni distincte.
Prima contine header-ul sau antet-ul specific. In acesta apar numele relatiei, o lista de atribute (sub forma de coloane) si a tipurilor acestora.
o Un exemplu de header arata astfel:
o

cuvintele cheie ce apar in aceasta
sectiune sunt:
@relation <numele fisierului> - este definita in primul rand al fisierului
<numele fisierului> este de tipul string, si trebuie pus intre ghilimele in cazul in care contine spatii
@attribute <numele atributului> <tipul atributului>
A doua contine datele propriu-zise:
o

Arata astfel
o Cuvant cheie ce marcheaza inceputul setului de date: @data
o Fiecare instanta este reprezentata pe o singura linie
o Valorile atributelor pentru fiecare instanta sunt delimitate prin virgula si trebuie sa apara in ordinea in care au fost declarate in sectiunea header.
o Valorile lipsa se marcheaza prin "?"
Observatii:
Caracterul "%" reprezinta delimitatorul pentru comentariu, si este prezent la inceputul liniilor
Declaratiile @RELATION, @ATTRIBUTE and @DATA sunt case insensitive.
In cadrul unui fisier ARFF % reprezinta delimitator pentru comentariu.
Declaratiile atributelor trebuie sa tina cont de urmatoarele:
o Acestea iau forma de secvente ordonate de afirmatii de tipul "@ATTRIBUTE"
o Fiecare atribut din setul de date are declaratia lui separata, care definieste in mod unic numele atributului si tipul acestuia.
o Ordinea atributelor declarate indica pozitia coloanelor din setul de date
o <numele atributului> trebuie sa inceapa cu un caracter alfabetic, iar daca contine spatii atunci va fi pus intre ghilimele
o <tipul atributului> poate face parte din oricare din cele 4 tipuri de atribute suportate momentan:
Numerice: @ATTRIBUTE varsta integer
Pot fi de tipul real sau intreg
Nominale: @ATTRIBUTE sex
Sunt definite prin specificarea valorilor posibile, incadrate intre caracterele
String: @ATTRIBUTE nume string
Permit crearea de atribute ce contin valori textuale arbitrare
Data: @ATTRIBUTE anul [<formatul datei>]
Exemplu de fisier ARFF utilizat in aplicatie:
@relation contact-lenses
@attribute age
@attribute spectacle-prescrip
@attribute astigmatism
@attribute tear-prod-rate
@attribute contact-lenses
@data
young,myope,no,reduced,none
young,myope,no,normal,soft
young,myope,yes,reduced,none
young,myope,yes,normal,hard
young,hypermetrope,no,reduced,none
young,hypermetrope,no,normal,soft
young,hypermetrope,yes,reduced,none
young,hypermetrope,yes,normal,hard
pre-presbyopic,myope,no,reduced,none
pre-presbyopic,myope,no,normal,soft
pre-presbyopic,myope,yes,reduced,none
pre-presbyopic,myope,yes,normal,hard
pre-presbyopic,hypermetrope,no,reduced,none
pre-presbyopic,hypermetrope,no,normal,soft
pre-presbyopic,hypermetrope,yes,reduced,none
pre-presbyopic,hypermetrope,yes,normal,none
presbyopic,myope,no,reduced,none
presbyopic,myope,no,normal,none
presbyopic,myope,yes,reduced,none
presbyopic,myope,yes,normal,hard
presbyopic,hypermetrope,no,reduced,none
presbyopic,hypermetrope,no,normal,soft
presbyopic,hypermetrope,yes,reduced,none
presbyopic,hypermetrope,yes,normal,none
2.3 Evaluarea rezultatului invatarii
Pentru determinarea celei mai bune metode de clasificare pentru o problema particulara se impune folosirea unei strategii sistematice de evaluare a functionarii diferitelor metode.
Dupa antrenarea retelei cu setul de date de antrenare nu se poate spune concret cat de bine lucreaza metodele, datorita faptului ca performanta pe setul de antrenare nu constituie un indicator pentru performanta acelei retele pe un set de date de testare independent.
Metoda validarii incrucisate este deseori aleasa ca metoda de evaluare in situatiile practice.
In mod obisnuit performanta clasificatorului se masoara in termeni de rata erorii. Rata erorii este calculata pe intregul set de instante, masurand performanta generala a clasificatorului. Un rezultat eronat apare in cazul in care clasificatorul nu identifica bine clasa unei instante.
Rata erorii pentru datele de antrenare se numeste rata de distributie, fiind calculata distribuind instantele in clasificatorul care s-a construit pe baza lor. Aceasta nu constituie un predictor viabil a ratei erorii pentru date noi, in schimb cunoasterea ei este utila.
Pentru prezicerea performantei clasificatorului asupra unor date noi va trebui evaluata rata erorii pentru un set de date ce nu a facut parte din setul de antrenare a clasificatorului. Setul acesta independent de date se numeste setul de test.
Se va presupune ca setul de antrenare si de test sunt esantionate reprezentativ pentru problema considerata.
Mai exista un al treilea set de date, numit set de validare, folosit in anumite tipuri de clasificator. Acest set este folosit imediat dupa setul de antrenare pentru optimizarea parametrilor clasificatorului.
Toate aceste trei seturi de date trebuie sa fie distincte.
Daca exista o cantitate suficienta de date se vor construi esantioane separate si independente pentru antrenare, validare si testare. Daca aceste seturi sunt reprezentative atunci rata erorii pentru setul de test este un indiciu viabil al performantei viitoare. In general cu cat clasificatorul este mai bun, si cu cat setul de test este mai mare, estimarea erorii este mai corecta.
2.3.1 Validarea incrucisata (cross validation)
In cazurile in care exista doar o cantitate limitata de date pentru antrenare si testare, se obisnuieste sa se pastreze o treime pentru testare. Setul folosit pentru antrenare sau testare risca in acest caz sa nu fie reprezentativ. In general este dificil de precizat daca un esantion este sau nu reprezentativ. Verificarea care se poate face este ca fiecare clasa din intregul set de antrenare sa fi reprezentata in proportie egala in setul de antrenare si testare. Daca din setul de antrenare lipsesc exemple dintr-o anume clasa, este aproape evident ca clasificatorul probabil nu a invatat sa clasifice bine exemple din acea clasa, lucru relevat imediat daca in setul de testare exista exemple din clasa respectiva.
Selectia trebuie facuta astfel incat fiecare clasa sa fie reprezentata prin exemple atat in setul de antrenare cat si in cel de clasificare. Aceasta procedura se numeste stratificare.
O tehnica mai generala pentru inlaturarea prejudecatilor cauzate de o alegere particulara este de a repeta intregul proces, antrenare si testare, de cateva ori cu diferite esantioane aleatoare. In fiecare iteratie o anumita proportie - sa zicem doua proportii - din date este selectata aleator pentru antrenare si restul ce ramane pentru testare. Ratele erorii din diferite iteratii sunt adunate pentru a produce o rata globala. Aceasta este o metoda holdout repetata de estimare a ratei erorii. Intr-o procedura holdout unica, putem schimba rolurile intre setul de antrenare si setul de testare. Aceasta inseamna ca antrenam sistemul cu datele de test si apoi il testam pe datele de antrenare. Din nefericire, in mod real proportia 50% date de antrenare nu este ideala - este mai bine sa folosim mai mult din jumatate de date pentru antrenare.
Validarea incrucisata presupune prestabilirea unui numar fix de felii (partitii) de date. Daca presupunem ca avem trei datele vor fi impartite in trei parti aproximativ egale, fiecare urmand sa fie utilizata pentru testare iar ce ramane pentru antrenare. Folosim doua treimi pentru antrenare si o treime pentru testare si repetam procedura de trei ori in asa fel incat la final fiecare instanta a fost utilizata exact o data pentru testare. Aceasta se numeste validare incrucisata cu trei felii - threefold cross validation.
Validarea incrucisata cu 10 felii este metoda standard de masurare a ratei erorii a unei scheme de invatare pe un set de date particular.
In acest caz datele sunt impartite aleator in 10 parti in care clasele sunt reprezentate in aproximativ aceasi proportie ca in setul intreg. Fiecare parte este pastrata pentru test si clasificatorul este antrenat pe cele noua ramase. Procedura de invatare este executata de 10 ori pe seturi diferite de date. In final cele 10 erori estimate sunt adunate pentru a produce o estimare globala a erorii.
Testele vaste pe numeroase seturi de date, cu diferite tehnici de invatare au aratat ca 10 este aproape cel mai bun numar de felii pentru a obtine cea mai buna estimare a erorii , si exista si cateva dovezi teoretice. Desi aceste argumente nu sunt inca decisive, validarea incrucisata cu 10 felii a devenit metoda standard in termeni practici.
Totusi, nici divizarea in 10 seturi de date nu este exacta: dar este suficient sa impartim datele in 10 seturi aproximativ egale in care clasele sunt reprezentate aproximativ in proportii egale.
O alta metoda utilizata este "Leave-one-out"
Aceasta metoda presupune o simpla validare incrucisata cu n felii, unde n este numarul instantelor din setul de date. Fiecare instanta la randul ei este lasata deoparte si clasificatorul este antrenat cu toate celelalte instante. Metoda este evaluata dupa corectitudinea pentru instantele ramase - unu sau zero pentru succes sau respectiv esec. Rezultatele celor n aprecieri, cate una pentru fiecare instanta, sunt insumate iar suma reprezinta eroarea finala estimata.
Avantaje:
Pentru antrenare in fiecare caz este utilizata o mai mare cantitate de date care probabil creste sansa preciziei clasificatorului.
Procedura este determinista: nu implica nici un esantion ales aleator. Nu exista nici o diferenta in repetarea de 10 ori sau o data: acelasi rezultat va fi obtinut de fiecare data.
Dezavantaje:
Costul computational este ridicat pentru ca intregul proces de invatare trebuie executat de n ori. Si aceasta este de obicei destul de imposibil pentru seturi de date mari.
Prin natura sa nu poate fi stratificata. Stratificarea implica proportia egala a exemplelor din fiecare clasa in setul de test si acest lucru este imposibil cand setul de test contine doar un singur exemplu.
2.3.2 Calcul erorii
Acesta este folositor atunci cand ne propunem sa comparam doua metode diferite de invatare pe aceeasi problema pentru a vedea care este cea mai buna.
Deseori nu este suficinet sa alegem doar metoda a carei estimare a erorii este cea mai mica.
Sa presupunem ca avem o problema de clasificare cu doua clase: A si B. O singura predictie are patru posibile rezultate asa cum se vede in tabelul 3.1. Cazurile true A (TA) si true B (TB) sunt clasificari corecte. Atunci cand exemplul actual este clasificat ca fiind din clasa A, dar de fapt el apartine clasei B, avem cazul false A (FA). Atunci cand exemplul actual apartine clasei A, dar este clasificat ca fiind din clasa B, avem cazul false B (FB).
|
Clasa prezisa |
||
|
Clasa actuala |
A |
B |
|
A true A |
false B |
|
|
B false B |
true B |
|
Tabelul 2.3.1 Rezultatele posibile pentru o problema cu doua clase
Rata true A este TA/(TA+FB), rata false B este FA/(FA+TB). Rata succesului se considera ca fiind numarul de clasificari corecte impartit la numarul total de clasificari: (TA+TB)/(TA+TB+FA+FB). Rata erorii se va calcula: 1-rata de succes.
Matricea de confuzie se foloseste atunci cand exista mai mult decat doua clase. Este o matrice bidimensionala:
Contine o linie si o coloana pentru fiecare clasa
Fiecare element al matricii reprezinta numarul de exemple ale caror clasa actuala este in rand, iar clasa prezisa in coloana.
Cap.3 Aplicația
Aceasta aplicatie conține o colectie de algoritmi pentru preprocesarea si clasificarea datelor.
Intreaga aplicatie este scrisa in C#, limbaj de programare orientat obiect, care a oferit suportul si uneltele necesare atat pentru crearea unei interfete friendly cat si pentru implementarea algoritmilor necesari.
Obiectivul pentru acesta aplicație a fost realizarea unui program care sa permita operarea cu fișiere de date de tip .arff, si construirea pe baza acestora a doua diferite tipuri de rețele neuronale - feedforward și probabilistice.
Programul permite citirea fișierelor .arff, cu un format bine definit, eliminand din datele fișierului instanțele ce prezinta valori lipsa.
Odata fișierul citit, din setul de date se vor extrage și separa aleator aproximativ 10% din totalul instanțelor, set ce va fi folosit la testarea rețelelor.
Datele sunt preprocesate in moduri diferite pentru cele doua rețele. Pe seturile de date folosite pentru rețele feedforward se preproceseaza doar atributele de tip label, printr-o simpla atribuire (label1 = 1, label2=2, etc). Pe seturile de date folosite la rețelele probabilistice se mai aplica in plus normalizarea acestora (se aplica radical la suma patratelor tuturor valorilor unei instanțe).
Arhitectura rețelelor feedforward asigura flexibilitate in definirea numarului de neuroni de pe cele doua nivele ascunse, permițand astfel fie nici un neuron pe nivelele ascunse, fie completarea ambelor nivele cu diferite numere de neuroni. Rata invațarii de asemenea poate fi definita de utilizator, precum și funcția de activare.
Arhitectura rețelelor probabilistice se construiește in funcție de setul de date, utilizatorul putand modifica doar coeficientul sigma. In cazul completarii campului sigma cu 0 se va construi rețeaua fara folosirea funcției radiale.
Imediat dupa antrenarea rețelelor se preia și setul de date pentru testare, astfel la sfarșitul antrenarii se afișeaza si rezultatele obținute pe setul de date test.
Specificul interfetei
3.1.2 Fereastra Clasificari:
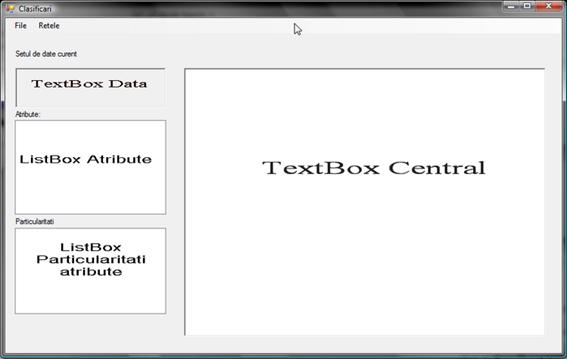
La executia aplicatiei se lanseaza o ferestra denumita Clasificari. Aceasta conține in partea de sus urmatorul meniu:
File
a. Open - permite deschiderea fisierelor de tipul '*.arff'
b. Exit - asigura iesirea din program
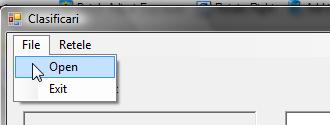
Retele
a. Feedforward - deschide o noua fereastra special pentru creearea, antrenare și testarea rețelelor feedforward
b. PNN - deschide o noua fereastra special pentru creearea, antrenarea și testarea rețelelor probabilistice
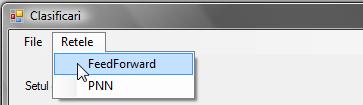
In aceasta fereastra se va executa citirea si preprocesarea datelor. Mai contine urmatoarele elemente:
Un textbox central - unde se afiseaza setul de date citit, respectiv setul de date dupa normalizare
Un textbox "Setul de date curent"- care contine informatii generale despre setul de date curent (numarul de instante, numarul de atribute, etc.)
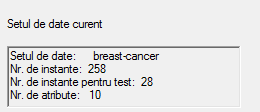
Un listbox "Atribute" - care contine o lista cu toate atributele prezente in setul de date . In momentul selectarii unuia va aparea in listbox-ul de sub acesta-"Particularitati" anumite date referitoare la tipul atributului și valorile pe care le ia acesta in intregul set de date
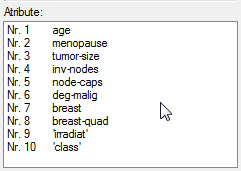
Un listbox "Particularitati" care afiseaza tipul atributului si:
o pentru atribute de tip label
afiseaza distributia pe clase

o pentru atributele numerice
afiseaza valoarea maxima, minima si media
In momentul deschiderii unui fișier, in textboxul central vor fi afișate:
Datele de antrenare in forma bruta
Datele de testare in forma bruta
Datele de antrenare normalizate
3.1.2 Fereastra Retele FeedForward
Pentru a construi și antrena o rețea Feedforward, se va face click in meniul Retele pe opțiunea FeedForward.
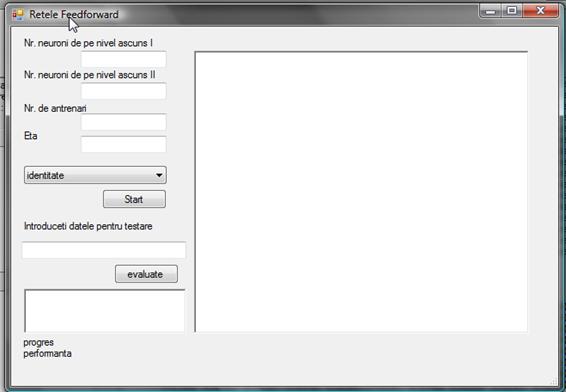
In aceasta ferastra se regasesc urmatoarele elemente:
Textboxul central in care se afișeaza rezultatele obținute pe setul de date pentru testare dupa antrenarea rețelei.
2 campuri pentru completarea numarului de neuroni ce urmeaza sa fie inițializați și folosiți in nivelele ascunse ale rețelei
1 camp pentru completarea valorii coeficientului eta - rata invațarii
1 combobox ce permite selecatrea tipului funcției de activare
Butonul de Start care pornește antrenarea rețelei
1 camp pentru introducerea unei instanțe de date pentru obținerea unei clasificari
Butonul Evaluate ce va obține clasa pentru instanța mai sus introdusa
1 camp in care se vor afișa rezultatul pentru instanța mai sus introdusa
2 labeluri
o Progres - arata antrenarea la care se afla rețeaua
o Performanța - va afișa dupa antrenare nr. de instante corect clasificate și numarul de instanțe incorect clasificate
3.1.2 Fereastra Retele Probabilistice
Pentru a construi și valida o rețea probabilistica, se va face click in meniul Retele pe opțiunea PNN.
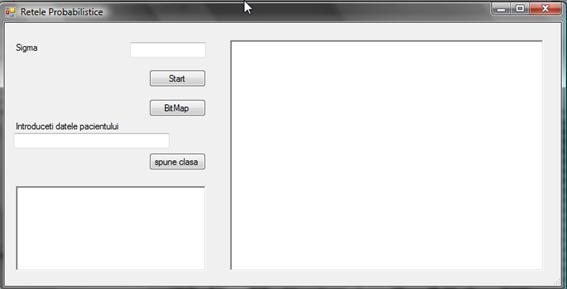
In aceasta ferastra se regasesc urmatoarele elemente:
Textboxul central in care se afișeaza rezultatele obținute pe setul de date pentru testare dupa antrenarea rețelei.
1 camp pentru completarea valorii coeficientului sigma
1 buton de Start care va construi și valida rețeaua
1 buton Bitmap care afișeaza structura rețelei odata construita
1 camp pentru introducerea unei instanțe de date pentru obținerea unei clasificari
Butonul spune clasa ce va obține clasa pentru instanța mai sus introdusa
1 camp in care se vor afișa rezultatul pentru instanța mai sus introdusa
3.2 Detalii despre cod
Codul aplicatiei este impartit pe mai multe fisiere. Tabelul de mai jos ilustreaza clasele sau structurile folosite in fiecare.
|
Data_structures.cs cu acest fisier a inceput intregul proces de programare contine o definirea structurilor folosite la citirea din fisierele .arff o definirea clasei dataSet folosita atat la citirea datelor din fisiere cat si la prelucrarea lor . |
public struct atribut conține: numele unui atribut,tipul acestuia și in cazul in care e de tip nominal conține si label-urile posibile. public struct instanta { public ArrayList stuff; public double[] getNormalizedInstance(dataSet ds) funcție pentru calcularea datelor normalizate public double[] getRawInstance(dataSet ds) funcție pentru transformarea datelor inițiale ce conțin atribute cu valori de tip label sau integer la tipul double } definește structura unei instanțe din setul de date public class dataSet { public string name; public ArrayList atribute; public ArrayList date; public double[] getRawInstance(int index) obține transformarea unei singure instanțe din setul de date, ce conține atribute cu valori de tip label sau integer la tipul double public double[] getNormalizedInstance(int index) funcție pentru normalizarea datelor dintr-o instanța public double[,] getfinalData(double[,] final) construiește tabelul de valori normalizate ale setului de date public void loadFromFile(string filePath) citirea datelor din fișierul .arff } definește structura unui set de date, oferind un mecanism rapid de accesare, modificare și organizare a datelor din fișier |
|
PNN_Network.cs Contine clasele folosite pentru construirea retelei probabilistice. |
public class neuron { public ArrayList inputIndexes; public neuron() constructorul clasei public double getOutput() calculeaza ieșirea unui neuron, iar pentru ultimul neuron ieșirea rețelei public void addInput(int index) adauga un neuron de input pe poziția index public void removeInput(int index) scoate un neuron de input de pe poziția index } definește structura generica a unui neuron public class neuralNetwork definește structura generica a unei rețele neuronale public class PNN_network:neuralNetwork { public int nrNeuroniInput; public int nrClase; public int nr_Instante; public double sigma; public double getOutput(instanta inst, dataSet ds, RichTextBox rt) calculeaza iesirea rețelei public PNN_network(dataSet ds, RichTextBox tb, double sigma_read) inițializeaza și construiește rețeaua definește structura rețelei probabilistice, moștenind clasa generica nerualNetwork public class PNN_neuronInput : neuron { double valoareAtribut; new public double getOutput() suprascrie funcția getOutput a clasei neuron obține valorile de intrare ale rețelei public void setOutput(double x) seteaza valoarea de output cu valori din setul de date } definește structura unui neuron de input, moștenind clasa generica neuron public class PNN_neuronInstanta : neuron { double[] localInstance; public double sigma; public double getOutput(neuralNetwork nn) calculeaza distanța euclidiana dintre un neuron instanța și intrarea acestuia public void setLocalInstance(double[] inst) seteaza valorile unui neuron instanta cu valorile din setul de date } definește structura unui neuron de pe straturile interioare ale rețelei, moștenește clasa generica neuron conține un vector de numere ce reprezinta o linie din setul de date public class PNN_neuronClasa : neuron { double myClass; public double getOutput(neuralNetwork nn) returneaza minimul dintre toate distanțele euclidiene calculate pentru clasa sa public double getClass() returneaza clasa public void setClass(double x) seteaza clasa } definește structura unui neuron de pe nivelul rețelei ce conține clasele setului de date moștenește clasa neuron public class PNN_neuronIesire : neuron { public double getOutput(neuralNetwork nn, RichTextBox rt) returneaza outputul rețelei } definește structura neuronului de ieșire al rețelei moștenește clasa neuron |
|
FF_Networks.cs Contine clasele folosite pentru construirea si antrenarea unei retele FeedForward. |
public class FF_Neuron : neuron { public ArrayList input; public ArrayList W; public bool isInputNeuron=false; public bool isLast = false; double returnValue; double prevOut; public double localError; public int indexFunctieActivare; public void setOutput(double x) seteaza outputul neuronilor de intrare public double getOutput(FF_Network ff) calcueaza iesirea dintr-un neuron aplicand funcția de activare public double getSumaPond(FF_Network ff) calcueaza iesirea dintr-un neuron fara a aplica funcția de activare public double activationFunction(double rez) definește funcțiile de activare public double derviFunctieiActivare(double x) definește derivata funcțiilor de activare } definește structura unui neuron din cadrul rețelei public class FF_Network : neuralNetwork { public int nrNeuroniInput; public int nrNeuroniNiv1, nrNeuroniNiv2; public FF_Network(dataSet ds, RichTextBox rt, int Hl1, int Hl2, int indexFunctieActiva) construiește rețeaua feedforward public void propagateError(double outError, RichTextBox rt) calculeaza propagarea inapoi a erorii public void fixWeights(double eta, RichTextBox rt) reajusteaza ponderile public double getOutput(instanta inst, dataSet ds) obține rezultatul rețelei } definește structura rețelei feedforward și conține funcțiile pentru antrenarea rețelei |
3.3. Folosirea aplicatiei pentru probleme concrete de clasificare
Mai jos sunt prezentate comparativ rezultatele obtinute pe diferite seturi de date.
|
Setul de date |
Retea FeedForward |
Retea porbabilistica |
|
breast-cancer Instante pentru antrenare 262 Instante pentru test 24 |
Instante corect clasificate : 15 62.50% Instante incorect clasificate: 9 37.50% |
Instante corect clasificate: 21 87.50% Instante incorect clasificate: 3 12.50% |
|
wisconsin-breast-cancer Instante pentru antrenare: 636 Instante pentru test: 63 |
Instante corect clasificate: 61 96.83% Instante incorect clasificate: 2 3.17% |
Instante corect clasificate: 59 93.65% Instante incorect clasificate: 4 6.35% |
|
pima_diabetes Instante pentru antrenare: 704 Instante pentru test: 64 |
Instante corect clasificate: 17 47.22% Instante incorect clasificate: 19 52.78% |
Instante corect clasificate: 18 50.00% Instante incorect clasificate: 18 50.00% |
|
lymphography Instante pentru antrenare: 127 Instante pentru test: 21 |
Instante corect clasificate: 15 71.43% Instante incorect clasificate: 6 28.57% |
Instante corect clasificate: 16 76.19% Instante incorect clasificate: 5 23.81% |
Corectitudinea rezultatelor obtinute prin folosirea aplicatiei implementate depinde atat de o setare corecta a parametrilor cu care aceasta opereaza, cat si de setul de date folosit.
Concluzii
Contextul in care clasificarea este fundamentala include diagnosticul preliminar a unei boli a pacientului pentru indicarea unui tratament imediat in asteptarea rezulatelor finale.
Lucrarea de fata abordeaza problemele de clasificare ce apar in stabilirea diagnosticului medical prin folosirea retelelor neuronale.
Studiul invatarii automate a dus la descrierea a numeroase metode care sa contrubuie la rezolvarea acestor probleme, variind dupa scop, date de antrenament, strategia de invatare si modalitatea de reprezentare a datelor. S-au obtinut structuri de reprezentare tot mai complexe si strategii de cautare tot mai eficiente. Printre acestea, retelele neuronale isi dovedesc in principal utilitatea in rezolvarea unor probleme dificile, cum sunt cele de estimare, identificare si predictie, sau de optimizare complexa.
Datorita capacitatii lor de a rezolva probleme complexe pe baza unei multimi de exemple, retelele deschid un spectru larg de aplicabilitate in domeniul medical.
BIBLIOGRAFIE
Bayesian Networks and Influence Diagrams, Uffe B. Kjærulff Department of
Copyright © 2026 - Toate drepturile rezervate