|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
FRAGMENTAREA VERTICALA
Fragmentarea verticala produce dintr-o relatie r fragmentele r1,r2,,rn fiecare din ele contine o submultime din atributele schemei lui R la fel ca si cheia primara a lui R. Obiectivul fragmentarii verticale este partitionarea relatiei intr-o multime de relatii mai mici astfel incat mai multe aplicatii utilizator sa poata executa un fragment. In acest context, o fragmentare optima este aceea care produce o schema de fragmentare care minimizeaza timpul de executie pentru aplicatiile utilizatorilor ce se executa pe aceste fragmente.
Fragmentarea verticala a fost cercetata in afara contextului sistemelor de baze de date centralizate, la fel ca si cele distribuite. Motivatia acesteia fara contextul centralizat este aceia de a fi un instrument de proiectare, in care fiecare fragment contine o submultime de atribute din schema R si cheia primara a lui R. Obiectivul fragmentarii verticale este partitionarea relatiei intr-o multime de relatii mai mici astfel incat mai multe aplicatii utilizator sa poata executa un fragment. In acest context, o fragmentare optima este aceea care produce o schema de fragmentare care minimizeaza timpul de executie pentru aplicatiile utilizatorilor ce se executa cu aceste fragmente.
Fragmentarea verticala a fost cercetata in afara contextului sistemelor astfel ca sa sa permita interogarilor utilizatorilor sa se foloseasca de relatiile mai mici, ce acceseaza un numar mai mic de pagini. Este de asemenea sugerat ca cele mai active subrelatii pot fi cele de identificare care sunt stocate in memoria rapida a subsistemului.
Partitionarea verticala este in totalitate mai complexa decat partitionarea
orizonatala. Aceasta este o parte din numarul total de alternative
care ne sunt disponibile. De exemplu daca in partitionarea
orizontala, numarul total de predicate simple in P este n, atunci sunt posibile ![]() predicate minterne,
care pot fi definite din ele. In concluzie,
stim ca , cateva dintre acestea vor contrazice existenta implicatiilor care mai departe reduc cantitatea
fragmentelor ce trebuie considerate. In cazul partitionarii
verticale, indiferent, daca o relatie are m atribute neprime(care
nu fac parte ditr-o cheie), numarul fragmentelor posibile este egal cu B(m), care este numarul
m-Bell(Niamir, 1978). Pentru valori foarte mari ale lui m,
predicate minterne,
care pot fi definite din ele. In concluzie,
stim ca , cateva dintre acestea vor contrazice existenta implicatiilor care mai departe reduc cantitatea
fragmentelor ce trebuie considerate. In cazul partitionarii
verticale, indiferent, daca o relatie are m atribute neprime(care
nu fac parte ditr-o cheie), numarul fragmentelor posibile este egal cu B(m), care este numarul
m-Bell(Niamir, 1978). Pentru valori foarte mari ale lui m, ![]() , de exemplu, pentru
m=15, B(m)=109, pentru m=30, B(m)=1023
, de exemplu, pentru
m=15, B(m)=109, pentru m=30, B(m)=1023
Aceste valori indica ca nu este util sa se incerce sa obtinerea de solutii optime pentru problema partitionarii verticale; Vom incerca numai abordari euristice. Exista doua tipuri de abordari euristice pentru fragmentarea verticala a relatiilor globale.
1. Gruparea: Se incepe cu repartizarea fiecarui atribut la un singur fragment, si la fiecare pas a unei multimi de legaturi dintre fragmente pana cand sunt satisfacute criteriile date. Gruparea a fost prima sugestie de grupare a bazelor de date si a fost folosita mai tarziu pentru distribuirea bazelor de date.
2. Partitionarea Se incepe cu o relatie si se decide daca partitionarea este utila daca respecta comportamentul de acces al aplicatiilor la atribute.
In continuare se vor discuta tehnicile de fragmentare, mai apropiate de metodologia algoritmului top-down. Mai mult, defragmentarea genereaza nesuprapunerea fragmentelor, avand in vedere gruparea rezultatelor tipice in suprapunerea fragmentelor. In contextul sistemului de baze de date distribuite ne preocupa nesuprapunerea fragmentelor pentru motive evidente. Bine-nteles nesuprapunerea se refera numai la atributele cheii neprimare.
Replicarea cheii relatiei globale in fragmente este o proprietate a fragmentarii verticale care permite reconstituirea relatiei globale. De aceea fragmentarea se aplica numai atributelor care nu fac parte din cheia primara
Replicarea atributelor cheii constitue un mare avantaj, in ciuda problemelor care le cauzeaza. Acest avantaj se refera la integritate. De retinut, ca orice dependenta este de fapt o constrangere care trebuie pastrata tot timpul de toate valorile atributelor relatiei respective. Majoritatea dependentelor implica atributele cheie ale unei relatii. Daca acum proiectam baza de date astfel incat atributele cheie sunt parti ale unui fragment care este alocat pe un site si atributele implicate sunt parti ale altui fragment care este pe un al doilea site, fiecare interogare de actualizare ce determina o verificare integritatii, va necesita o comunicare intre site-uri. Replicarea atributelor cheii pe fiecare fragment reduce sansele ca acesta sa apara, dar nu o elimina definitiv, din moment ce asemenea comunicare ar putea fi necesara datorita restrictiilor de integritate ce nu implica cheia primara, la fel si datorita controlului concurentei.
O alternativa la replicarea atributelor cheii este folosirea identificatoarelor de tupluri (TID) care sunt atribuiri de valori unice tuplurilor unei relatii. Aceste identificatoare de tupluri sunt intretinute de sistem, fragmentele sunt disjuncte in ceea ce priveste utilizatorul.
Informatii cerute de fragmentarea verticala
Informatia principala ceruta de fragmentarea
verticala este cea legata de
aplicatii. Din moment ce partitionarea verticala pune in mod
obisnuit intr-un fragment anumite atribute care sunt accesate impreuna necesare anumite "masuri" care ar defini mai concret notiunea de unire. O masura
este data de afinitatea
atributelor care indica cat de strans sunt legate atributele. Din nefericire este foarte greu ca proiectantul unei baze de date sau un utilizator sa
fie capabili sa o specifice. Prezentam acum o modalitate prin care ei o pot obtine din date primitive. Cea mai importanta cerinta
legata de aplicatii este frecventa cu care sunt accesate. Fie ![]() o multime de
interogari (aplicatii) ale unui utilizator care vor rula pe relatia r(A1,A2,..,An). Atunci pentru
fiecare interogare
o multime de
interogari (aplicatii) ale unui utilizator care vor rula pe relatia r(A1,A2,..,An). Atunci pentru
fiecare interogare ![]() si fiecare atribut
si fiecare atribut ![]() asociem o valoare
atributului , notata cu
asociem o valoare
atributului , notata cu ![]() si
definita dupa cum
urmeaza:
si
definita dupa cum
urmeaza:

Vectorii
![]() pentru fiecare
aplicatie sunt usor de
definit daca proiectantul stie
aplicatiile ce vor rula pe baza de date
pentru fiecare
aplicatie sunt usor de
definit daca proiectantul stie
aplicatiile ce vor rula pe baza de date
Exemplul 5.15 Consideram relatia Proiecte din figura 3. Sa presupunem ca urmatoarele aplicatii sunt definite astfel incat sa ruleze pe aceasta relatie. In fiecare caz dam de asemenea si specificari SQL.
![]() : Sa se gaseasca bugetul proiectului dat
printr-un numar de identificare
: Sa se gaseasca bugetul proiectului dat
printr-un numar de identificare
SELECT DENUMIRE
FROM Proiecte
WHERE ID_PROIECT Value
![]() : Sa se gaseasca numele
si bugetele tuturor proiectelor.
: Sa se gaseasca numele
si bugetele tuturor proiectelor.
SELECT DENUMIRE BUDGET
FROM Proiecte
![]() : Sa se gaseasca numele proiectelor situate intr-un
oras dat.
: Sa se gaseasca numele proiectelor situate intr-un
oras dat.
SELECT DENUMIRE
FROM Proiecte
WHERE LOC Value
![]() : Sa se bugetul total al proiectelor pentru un oras dat.
: Sa se bugetul total al proiectelor pentru un oras dat.
SELECT SUM(BUDGET)
FROM Proiecte
WHERE LOC Value
Din aceste patru aplicatii valorile utilizate ale atributelor pot fi definite. Notand cu
A1 ID_PROIECT A2 DENUMIRE A3 BUDGET A4 LOC Valorile utilizate
sunt definite de matricea din figura 5.15, unde intrarea (i,j) defineste ![]() .
.![]()
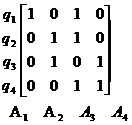
Figura 5.15
Valorile utilizate ale atributelor nu sunt suficient de generale pentru
a forma baza fragmentarii schemelor de atribute. Aceasta se intampla, deoarece aceste valori nu reprezinta in esenta frecventele aplicatiei. Masura frecventei poate fi inclusa in definitia
masurii afinitatii atributului ![]() , care masoara legatura dintre doua
atribute dintr-o relatie tinand cont de modul in care sunt accesate
aplicatiile.
, care masoara legatura dintre doua
atribute dintr-o relatie tinand cont de modul in care sunt accesate
aplicatiile.
Masura afinitatii atributului dintre doua atribute
Ai si Aj ale unei relatii r(A1,A2,..,An) cu privire la o
multime de aplicatii ![]() este definita
astfel :
este definita
astfel :
![]() ,
,
Unde ![]() este numarul de
accesari ale atributelor
este numarul de
accesari ale atributelor ![]() pentru fiecare
executie a aplicatiei
pentru fiecare
executie a aplicatiei ![]() din situl
din situl ![]() si
si ![]() este masura
frecventei de acces a
aplicatiei definita anterior si modificata sa
includa prezenta la diverse situri. Rezultatul acestei comutari este o matrice de
dimensiune nxn , unde fiecare element este o masura definita mai sus. Numim aceasta
matrice, matricea de afinitate a atributelor (AA).
este masura
frecventei de acces a
aplicatiei definita anterior si modificata sa
includa prezenta la diverse situri. Rezultatul acestei comutari este o matrice de
dimensiune nxn , unde fiecare element este o masura definita mai sus. Numim aceasta
matrice, matricea de afinitate a atributelor (AA).
Exemplul 5.16 Sa continuam cu cazul care l-am examinat in exemplul 5.15. Pentru simplitate sa
presupunem ca ![]() pentru toti
pentru toti ![]() si
si ![]() .
.
Daca frecventele aplicatiei sunt:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
atunci, masura afinitatii intre atributele A1 si A3 poate fi masurata astfel:
![]() . Din moment ce singura aplicatie care
acceseaza ambele atribute este
. Din moment ce singura aplicatie care
acceseaza ambele atribute este ![]() . Matricea de afinitate a atributelor completa este aratata in figura 5.16. Sa observam ca
valorile de pe diagonala sunt de asemenea calculate chiar daca
ele nu inseamna nimic.
. Matricea de afinitate a atributelor completa este aratata in figura 5.16. Sa observam ca
valorile de pe diagonala sunt de asemenea calculate chiar daca
ele nu inseamna nimic.
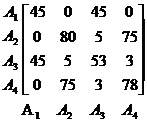
Figura 5.16 Matricea de afinitate a atributelor
Matricea de afinitate a atributelor va fi folosita in restul acestui capitol pentru a ghida efortul fragmentatii. Procesul implica mai intai gruparea atributelor cu afinitate ridicata unul pentru fiecare altul, apoi partitionarea relatiei in mod corespunzator.
Algoritmul de grupare
Obiectivul fundamental in proiectarea algoritmului de fragmentare verticala este de a gasi cateva mijloace de grupare a atributelor unei relatii bazate pe valori de afinitate ale atributelor din AA. A fost sugerat de catre [Hoffer and Severance, 1975] si [ Navathe el al. 1984] ca algoritmul de legatura(BEA) [McCormick et al., 1972] ar trebui folosit in acest scop. E considerat adecvat pentru urmatoarele motive:
1. Este proiectat in mod specific pentru a determina grupuri de itemi asemanatori
spre deosebire de, sa zicem, itemi ordonati liniar (gruparea atributelor cu valoarea
afinitatii mare, impreuna, si cele valoare mica , impreuna).
2. Gruparile finale sunt insensibile la ordinea in care itemii sunt prezenti in algoritm.
3. Timpul de compilare al algoritmului este rezonabil (o(n2)), unde n este numarul de
atribute.
4. Interrelatiile secundare dintre grupurile de atribute sunt identificabile.
Algoritmul de grupare (BEA) ia ca date de intrare matricea de afinitate a atributelor, permuta coloanele si liniile acesteia, si genereaza o matrice de afinitate (CA). Permutarea este facuta in asemenea mod pentru a maximiza urmatoarea masura de afinitate globala:
![]()
Unde
![]()
Ultima multime de conditii urmareste cazurile in care un atribut este inclus in CA in stanga celui mai din stanga atribut, sau in dreapta celui mai din dreapta atribut, in timpul permutarii coloanelor si inaintea celei mai de sus linii, si dupa ultima linie in timpul permutarii liniilor. In aceste cazuri luam 0 pentru valorile aff dintre atributul considerat fixat si vecinii lui din dreapta sau din stanga (sus sau jos), care nu exista in CA.
Functia de maximizare ia in calcul numai cei mai apropiati vecini, de unde rezulta grupari de valori mari cu lungime mare si valori mici cu lungime mica. De asemenea matricea de afinitate a atributelor (AA) este simetrica, unde functia obiectiv a formularii de mai sus este:
![]()
Detaliile algoritmului de grupare (BEA) sunt date in algoritmul 5.3. Generarea matricei de afinitate grupata este data de trei pasi:
1. Initializarea. Pozitionam si fixam arbitrar una din coloanele lui AA in CA.
2. Iteratia. Alegem fiecare dintre n-i coloane ramase (i este numarul de coloane deja plasate in CA) si incercam sa le plasam pe cele i+1 pozitii ramase in matricea CA. Alegem pozitionarea care aduce cea mai mare contributie la masura de afinitate globala descrisa mai sus. Continuam acest pas pana cand nu mai raman coloane de pozitionat.
3. Ordonarea liniilor.Odata ce ordonarea coloanelor este determinata, pozitionarea liniilor ar trebui de asemenea schimbata astfel incat pozitia lor relativa ar trebui sa se potriveasca cu pozitia relativa a coloanelor. Algoritmul BEA
Start[BEA]
2. Input
CA( AA(*,1)
6.1 for i from 1 to index-1 by 1 do
6.1.1 calculeza cont(Ai+1 , Aindex,Ai)
calculeza cont(Aindex-1 , Aindex,Aindex+1)
6.3 loc pozitia data de valoarea maxima a lui cont
6.4 for j from index to loc by -1 do
6.4.1 CA(*,j) CA(*,j-1)
6.5 CA(*,loc) AA(*,index)
6.5.1 Index index+1
Continue
Se ordoneaza liniile in concordanta cu ordinea relativa a coloanelor
7. Output
. Stop
Pentru ca al doilea pas al algoritmului sa mearga trebuie sa definim ceea ce inseamna contributia unui atribut la masurarea afinitatii. Aceasta contributie poate fi derivata dupa cum urmeaza. Sa ne amintim ca masura de afinitate globala AM a fost definita anterior ca:
![]()
poate fi rescrisa ca:
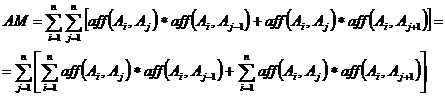
Sa definim legatura dintre doua atribute Ax si Az astfel :
![]()
Apoi AM poate fi scrisa ca:
![]()
Sa consideram acum urmatoarele n atribute
![]()
Masura de afinitate globala pentru aceste atribute poate fi scrisa astfel:
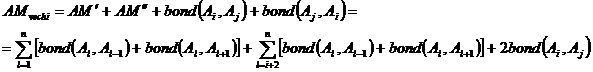
Acum sa consideram pozitionarea unui nou atribut Ak intre atributele Ai si Aj in matricea de afinitate globala. Noua masura de afinitate globala poate fi in mod asemanator scrisa astfel:
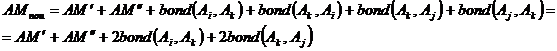 Astfel, "contributia la masura de afinitate globala in plasarea atributului Ak intre atributele Ai
si Aj este:
Astfel, "contributia la masura de afinitate globala in plasarea atributului Ak intre atributele Ai
si Aj este:
![]()
Exemplul 5.17 Sa consideram matricea AA data in figura 5.16 si sa studiem contrubutia atributului mobil A4 intre atributele A1 si A2 data prin formula:
![]()
Calculand fiecare termen avem
![]()
![]()
![]()
Asadar,
![]()
Sa observam ca: calcularea legaturii dintre doua atribute cere inmultirea elementelor respective din cele doua coloane reprezentand acele atribute si luand suma pe linii.
In algoritm ne am concentrat pe coloanele din matricea de afinitate a atributelor. Putem sa sa reproiectam algoritmul pentru a functiona si pentru linii. Din moment ce matricea este simetrica, ambele abordari vor genera acelasi rezultat.
Pentru a imbunatati eficienta algoritmului BEA, a doua coloana trebuie de asemenea sa fie fixata si pozitionata langa prima in timpul pasului de initializare. Aceasta situatie este acceptabila din moment ce, conform algoritmului, A2 poate fi pozitionat ori in stanga ori in dreapta lui A1. Legatura dintre cele doua, totusi este independenta de pozitia lor relativa una fata de cealalalta.
In final, ar trebui sa indicam problema de calculare a lui cont in punctele finale. Daca un atribut Ai este considerat pozitionat in stanga celui mai din stanga atribut, una din ecuatiile de legatura ce trebuie calculate este intre un element stang inexistent si Ak [bond(A0, Ak)]. In continuare avem nevoie sa ne referim la impusa in definitia masurii afinitatii globale, unde CA(0,k) . Celalalt extrem este daca Aj este cel mai din dreapta atribut care este deja pozitionat in matricea CA, si verificam contributia pozitionarii atributului Ak in dreapta lui Aj. In acest caz bond(k,k+1) trebuie sa fie calculat. Totusi, din moment ce nici un atribut nu este pozitionat in coloana k+1 din matricea CA, masura afinitatii nu este definita. Asadar, conform conditiilor de la punctele finale, valoarea acestui bond este de asemenea 0.
Exemplul 5.18 Sa consideram atributele unei relatii J grupate, si sa folosim matricea de afinitate a atributelor AA din figura 5.16.
In conformitate cu pasul de initializare, noi copiem coloanele 1 si 2 ale matricii AA in matricea CA(figura 5.17) si incepem cu coloana a treia. Aici exista trei alternative de plasare unde coloana 3 poate fi pozitionata: in stanga coloanei 1, rezultand ordinea (3-1-2), intre coloanele 1 si 2, dandu-ne (1-3-2), si in dreapta coloanei 2 rezultand(1-2-3). De retinut, pentru calcularea contributiei din ultima organizare, calculam cont(A2,A3,A4), apoi calculam cont(A1,A2,A3). In plus, in acest context A4 se refera la pozitia indexului al patrulea in matricea CA, care este goala, nu exista atribute A4 in coloana matricii AA. Sa calculam contributia masurii afinitatii globale in fiecare varianta
Ordinea (0-3-1):
![]()
Stim ca
![]()
![]()
Astfel
![]()
Ordinea (1-3-2):
![]()
![]()
![]()
![]()
Astfel
![]()
Ordinea (2-3-4):
![]()
![]()
![]()
![]()
Astfel
![]()
Din moment ce, contributia ordinii(1-3-2) este mare, selectam sa pozitionam A3 in dreapta lui A1(figura 5.17b). Similar, calculele pentru A4 , indica ca acesta trebui pozitionat in dreapta lui A2 (figura 5.17c).
In final liniile sunt organizate in ordinea in care sunt aratate coloanele si rezultatele din figura 5.17d.
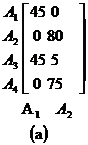

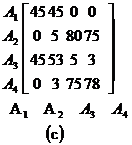
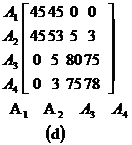
Figura 5.17 Calcularea Matricii CA.
In figura 5.17(d) observam doua grupari: una este in coltul din stanga sus, si contine valori mici ale anfinitatii, si alta se afla in coltul din dreapta jos si contine valori mari ale afinitatii. Aceasta grupare indica modul in care, atributele relatie J trebuie impartite. Cu toate acestea, in general , marginea pentru aceasta impartire nu este o taietura clara. Cand matricea CA este foarte mare, de obicei, mai mult de doua grupari sunt formate si atunci exista mai multe variante de partitionare. Astfel, in aceasta privinta este nevoie sa abordam aceasta problema mai sistematic.
Algoritmul de partitionare
Obiectivul activitatii de impartire este sa se gaseasca seturile de atribute care sunt accesate exclusiv, sau in cea mai mare parte, de seturile de aplicatii diferite. De exemplu, este posibil sa identificam doua atribute, A1 si A2, care sunt accesate de aceeasi aplicatie q1, si atributele A3 si A4, care sunt accesate de, sa zicem, doua aplicatii q2 si q3, care trebuie sa fie cat se poate de exacte pentru a decide fragmentele. Scopul se afla in gasirea unei metode algoritmice de identificare a acestor grupuri.
Sa consideram matricea de atribute asociate din figura 5.18. Daca un punct de-a lungul
diagonalei principale este fixat, doua multimi de atribute sunt
identificate. O multime ![]() se afla in
contul din stanga sus, si a doua multime
se afla in
contul din stanga sus, si a doua multime ![]() in coltul din dreapta jos a acestui punct. Numim prima
multime top, si a doua multime button si notam
multimile de atribute TA, respectiv BA.
in coltul din dreapta jos a acestui punct. Numim prima
multime top, si a doua multime button si notam
multimile de atribute TA, respectiv BA.

Figura 5.18 Localizarea unui punct de partitionare.
Ne intoarcem acum la multimea de aplicatii ![]() si definim multimile de aplicatii care
acceseaza numai TA, numai BA, sau amandoua. Aceste multimi sunt
definite dupa cum urmeaza:
si definim multimile de aplicatii care
acceseaza numai TA, numai BA, sau amandoua. Aceste multimi sunt
definite dupa cum urmeaza:
![]()
![]()
![]()
![]()
Prima dintre aceste ecuatii defineste multimea de atribute accesate de aplicatia ![]() ; TQ si BQ sunt multimile de aplicatii care
acceseaza numai TA sau numai TB, si OQ este multimea de
aplicatii care le acceseaza pe amandoua.
; TQ si BQ sunt multimile de aplicatii care
acceseaza numai TA sau numai TB, si OQ este multimea de
aplicatii care le acceseaza pe amandoua.
Exista o problema de optimizare. Daca exista n atribute intr-o relatie , exista n-1 pozitii posibile unde punctul de impartire poate fi pozitionat de-a lungul diagonalei matricii de atribute asociate pentru acea relatie. Cea mai buna pozitie pentru divizare este una care produce multimile TQ si BQ astfel incat accesele totale la numai un fragment sunt maximizate, in timp ce accesele totale la toate fragmentele sunt minimizate. Definim asadar urmatoarele ecuatii de cost:
![]()
![]()
![]()
![]()
Fiecare dintre ecuatiile de deasupra calculeaza numarul total de accese la atribute, de
aplicatii la clasele lor respective. Bazata pe aceste masuri,
problema optimizarii este definita prin gasirea punctului x (![]() ) astfel incat expresia
) astfel incat expresia
![]() este maximizata
[Navathe et al., 1984]. Caracteristica importanta a acestei este ca
defineste doua fragmente astfel incat valorile lui CTQ
si CBQ sunt pe cat posibil
aproximativ egale. Aceasta activeaza balansarea incarcarilor de procesare cand fragmentele sunt
distribuite pe mai multe site-uri. Este clar ca algoritmul de partitionare are o complexitate liniara in termini
numarului de attribute din relatie, care este O(n).
este maximizata
[Navathe et al., 1984]. Caracteristica importanta a acestei este ca
defineste doua fragmente astfel incat valorile lui CTQ
si CBQ sunt pe cat posibil
aproximativ egale. Aceasta activeaza balansarea incarcarilor de procesare cand fragmentele sunt
distribuite pe mai multe site-uri. Este clar ca algoritmul de partitionare are o complexitate liniara in termini
numarului de attribute din relatie, care este O(n).
Exista doua complicatii la care trebuie sa ne referim. Cititorul grijului ar fi trebuit sa observe ca procedura partitioneaza multimea in doua moduri. Pentru multimi de attribute mai mari, este destul de probabil ca metoda m de partitionare sa fie necesara.
Proiectarea unui metode n pe partitionare este posibila, dar este greu de calculat. De-a lungul diagonalei matricii CA, este necesar sa incercam 1,2,3, . ,n-1 puncte de partitionare si pentru fiecare din acesta este necesar sa verificam care pozitie maximizeaza z. Astfel complexitatea unui astfel de algoritm este O(2n). Bineinteles, definitia lui z a fost modificata pentru acele cazuli in care exista mai multe puncte de partitionare. Solutia alternativa este sa apelam recursive algoritmul de partitionare binara la fiecare din fragmentele obtinute in timpul iteratiei anterioare. Se poate calcula TQ, BQ si OQ la fel de bine ca si masurile de acces asociatepentru fiecare dintre fragmente, si sa le partitionam mai departe.
A doua complicatie are legatura cu locatia blocului de attribute care ar trebui sa formeze un fragment. Discutia noastra de pana acum a presupus ca punctual de partitionare este unic si imparte matricea CA in partitia din stanga sus si o a doua partitie formata din restul atributelor. Partitia poate fi formata , totusi, in mijlocul matricii. In acest caz trebuie sa modificam putin algoritmul. Cea mai din stanga coloana a matricii CA este deplasata in dreapta celei mai din dreapta coloane, si cea mai se sus linie este nutata jos. Operatia de mutare este urmata de verificarea celor n-1 pozitii de pe diagonala pentru a gasi valoarea maxima a lui z. Ideea din spatele acestei modificari este de a muta blocul de attribute care ar trebui sa formeze un grup in coltul din stanga sus al matricii, unde pot fi usor identificate. Cu adaugarea operatiei de mutare , complexitatea algoritmului de partitionare creste cu un factor al lui n si devine O(n2).
Presupunand ca procedura mutare numita MUTARE a fost deja implementata, algoritmul de
partitionare este dat in algoritmul 5.4. Datele de intrare ale
algoritmului Partitionare este matricea de afinitate CA, si
relatia R care trebuie
fragmentata. Datele de iesire sunt multimile de fragmente![]() , unde
, unde ![]() si
si ![]() cheia atributelor din relatia R. Observam ca
pentru metoda n de partitionare aceasta rutina ar trebui
invocata iterativ, sau implementata ca o procedura recursiva.
cheia atributelor din relatia R. Observam ca
pentru metoda n de partitionare aceasta rutina ar trebui
invocata iterativ, sau implementata ca o procedura recursiva.
Algoritmul 5.4 PARTITIONARE
Input: CA: matricea de afiniate; R: relatia
Output: F:multimea de fragmente
Begin
Calculeaza CTQn-1
Calculeaza CBQn-1
Calculeaza COQn-1
Bun CTQn-1*CBQn-1-(COQn-1)2
Do
Begin
for i from n-2 to by-1 do
begin
Calculeaza CTQi
Calculeaza CBQi
Calculeaza COQi
Bun CTQi*CBQi-(COQi)2
if z>bun then
begin
bun z
retine pozitia de mutare
end-if
end-for
call MUTARE(CA)
end-begin
until nu mai este posibila nici o mutare
reface matricea in conformitate cu pozitia mutata
![]()
![]()
![]()
End.
Exemplul 5.19
Cand algoritmul PARTITIONARE este aplicat matricii CA
obtinand pentru relatia J,
rezultatul este definirea fragmentelor ![]() , unde
, unde ![]() si
si ![]() . Atunci
. Atunci
J1=
J2=
Sa retinem ca in acest exercitiu noi imbunatatim fragmentarea pentru intreaga multime de atribute.
Verificarea pentru corectitudine.
Urmam argumente similare ca pentru partitionarea orizontala pentru a demonstra ca algoritmul PARTITIONARE admite o fragmentare corecta.
Completitudinea
Completitudinea este garantata de algoritmul PARTITIONARE din moment ce fiecare atribut al relatiei globale este rapartizat unui dintre fragmente. Multimea de atribute A peste care este definita relatia R consista in
![]() completitudinea
fragmentarii verticale este asigurata.
completitudinea
fragmentarii verticale este asigurata.
Reconstructia
Am mentionat deja ca reconstructia relatiei globale
originale este posibila
datorita opertiei de unire. Astfel, pentru o relatie R cu
fragmentarea verticala ![]() unde si atributele cheie k,
unde si atributele cheie k, ![]() . Asadar atata
timp cat fiecare Ri este complet, opereatia de unire va
reconstrui in mod corespunzator R. Un alt punct important este ca ori
fiecare Ri ar trebui sa contina atributele cheie ale
lui R, ori ar trebui sa contina tuplul sistem atribuit
IDs(TIDs).
. Asadar atata
timp cat fiecare Ri este complet, opereatia de unire va
reconstrui in mod corespunzator R. Un alt punct important este ca ori
fiecare Ri ar trebui sa contina atributele cheie ale
lui R, ori ar trebui sa contina tuplul sistem atribuit
IDs(TIDs).
Separarea
Asa cum am indicat mai inainte, separarea fragmentelor nu este asa de importanta in fragmentarea verticala, precum este in cea orizontala. Exista doua cazuri aici:
1. Este folosit TIDs, in care caz fragmentele sunt separate deoarece TIDs este replicat in fiecare fragment repartizat unui sistem si administrarea entitatilor, total invizibile petru utilizatori.
2. Atributele cheilor sunt replicate in fiecare fragment, in acelasi caz nu putem cere ca cheia sa fie separata in acest sens strict al termenului. Oricum, e important sa realizam ca aceasta duplicare a atributelor cheii este stiuta si adiminstrata de sistem si nu are aceeasi implicatie ca duplicarea tuplurilor in partitionarea fragmentelor orizontal.
Fragmentarea hibrida(mixta)
Se realizeaza prin aplicarea succesiva a operatiilor de fragmentare orizontala si verticala. Astfel, fragmentele mixte pot fi obtinute prin aplicarea fragmentarii orizontale la un fragment vertical, respectiv prin aplicarea fragmentarii verticale la un fragment orizontal. Aceste operatii pot fi repetate recursiv generand arbori de fragmentare de orice complexitate. In practica este recomandat sa existe cel mult doua niveluri de fragmentare.
In multe cazuri a fragmentarii orizontale sau verticale a schemei bazelor de date nu sunt suficiente sa satisfaca interogariile aplicatiilor utilizatorilor. In acest caz a fragmentarii verticale trebuie sa urmeze una orizontala, sau invers, producand un arbore de partitionare structurata. Din moment ce doua tipuri de strategii de partitionare sunt aplicate una dupa alta, aceasta alternativa se numeste fragmentare hibrida sau fragmentare mixta.
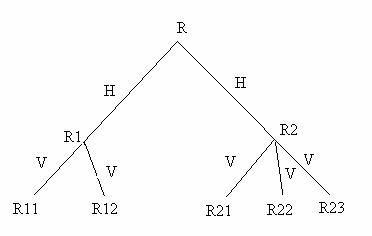
Figura 5.19 Fragmentarea hibrida.
Un exemplu bun pentru necesitatea fragmentarii hibride este relatia J, cu care am lucrat. In exemplul 5.11 fragmentam in sase fragmente orizontale bazate pe doua aplicatii. In exemplul 5.19 fragmentam aceeasi relatie in doua. Ce avem, deci, o multime de fragmente orizontale, pe care mai departe le partitionam in doua fragmente verticale.
Numarul nivelelor de serii poate fi foarte mare, dar este cu certitudine finit.In cazul fragmentarii orizontale, trebuie sa ne oprim atunci cand fiecare fragment consta intr-un singur tuplu, unde punctul terminal pentru fragmentarea verticala este un atribut pe fragment. Aceste limite sunt cat se poate de academice, oricum, pana acum nivelele de serii in cele mai multe aplicatii practice nu depasesc doi. Este exact adevarat ca normalizarea relatiei globale are deja grad mic si nu se pot face prea multe fragmentari verticale inainte ca costurile de unire sa devina foarte mari.
Nu vom discuta in detaliu corectitudinea regulilor si conditiilor pentru fragmentarea hibrida. Fragmentarea este completa daca fragmentele intermediare si cele terminale sunt complete. In mod asemanator, disjuncitvitatea este garantata daca fragmentele intermediare si cele terminale sunt disjuncte.
ALOCAREA
Alocarea resurselor de-a lungul nodurilor unei retele de calculatoare este o problema care a fost intens studiata. Cea mia mare parte din aceasta munca totusi, nu se refera la problema proiectarii bazelor de date distribuite, ci mai degraba la plasarea fisierelor individuale pe o retea de calculatoare.
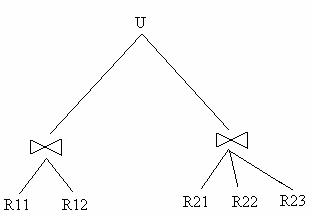
Figura 5.20 Reconstructia Fragmentarii Hibride
Vom examina pe scurt diferentele dintre cele doua. In primul rand trebuie sa definim problema alocarii mia precis.
Problema alocarii
Sa presupunem ca exista o multime de fragmente![]() si o retea compusa din site-utile
si o retea compusa din site-utile ![]() pe care multimea
aplicatiilor
pe care multimea
aplicatiilor ![]() se executa.
Problema alocarii presupune gasirea distributiei
optime a lui F pe S.
se executa.
Problema alocarii presupune gasirea distributiei
optime a lui F pe S.
Unul dintre subiectele importante care trebuie discutate este definirea optimalitatii. Optimalitatea poate fi definita cu privire la doua masuri [Dowdy si Foster, 1982
1. Costul minimal.Functia cost consta in costul memorarii fiecarui fragment Fi la sete-ul Sj, costul interogariilui Fi la site-ul Sj, costul actualizarii lui Fi la toate site-urile unde este stocat, si costul de comunicare la datelor. Problema alocarii atunci, tinde sa gaseasca o schema de alocare care minimizeaza o functie de cost combinata.
2. Performante. Strategia de alocare este proiectata sa mentina o performanta metrica. Doua bine cunoscute astfel de strategii sunt pentru a minimiza timpul de raspuns si pentru a maximiza rezultatul sistemului la fiecare site.
Cele mai multe dintre modelele care au fost propuse pentru date fac aceasta distinctie de optimizare. Totusi, daca examinam aceasta problema in profunzime, in aparenta, masura de optimalitate ar trebui sa includa atat performanta cat si factorii de cost. Cu alte cuvinte ar trebui sa cautam o schema de alocare care, de exemplu raspunde interogarilor utilizatorului in timp minimal, pastrand in acelasi timp si costul minim al procesului. O afirmatie similara poate fi facuta pentru maximizarea rezultatului. Ne putem atunci intreba de ce astfel de modele nu au fost dezvoltate. Raspunsul este destul de simplu:complexitatea.
Sa
consideram o formulare foarte simpla a problemei. Fie F, S definite ca mai inainte. De aceasta data
consideram un singur fragment ![]() . Facem cateva presupuneri si definitii care ne vor
permite sa modelam problema de alocare.
. Facem cateva presupuneri si definitii care ne vor
permite sa modelam problema de alocare.
1. Presupunem ca Q poate fi
modificata astfel incat este posibil sa identificam
interogatile de actualizare si de refacere numai , si sa definim
urmatoarele pentru un singur
fragment ![]() .
.
![]() unde
unde ![]() este traficul numai de citire, generat la siteul
este traficul numai de citire, generat la siteul ![]() pentru fragmentul
pentru fragmentul ![]() si
si
![]() unde
unde ![]() este actualiyarea
traficului generat la site-ul
este actualiyarea
traficului generat la site-ul ![]() pentru fragmentul
pentru fragmentul ![]() .
.
2. Presupunem ca costul comunicatiei intre doua site-uri ![]() si ,
si ,![]() oricare ar fi i
si j, este fixat pentru o unitate de trafic . Mai mult presupunem ca este diferit pentru actualizari si refaceri si definim
urmatoarele:
oricare ar fi i
si j, este fixat pentru o unitate de trafic . Mai mult presupunem ca este diferit pentru actualizari si refaceri si definim
urmatoarele:
![]()
![]() unde
unde ![]() este costul unei unitati de comunicatie pentru cererile de refacere intre site-urile
este costul unei unitati de comunicatie pentru cererile de refacere intre site-urile ![]() ,
,![]() si
si ![]() este costul unei
unitati de comunicatie pentru cererile de actualizare intre
sire-urile
este costul unei
unitati de comunicatie pentru cererile de actualizare intre
sire-urile ![]() si
si ![]() .
.
3. Fie ![]() costul de stocare al unui fragment pe site-ul
costul de stocare al unui fragment pe site-ul ![]() . Astfel vom defini
. Astfel vom defini ![]() pentru costul de
stocare al fragmentului
pentru costul de
stocare al fragmentului ![]() in toate site-urile.
in toate site-urile.
4. Presupunem ca nu sunt constrangeri de capacitate de stocare pentru nici unul dintre site-urile retelei de comunicatie.
Atunci problema alocatiei poate fi pusa ca o
problema de minimizare de cost unde incercam sa gasim multimea ![]() care specifica
unde vor fi stocate copiile
fragmentului. In continuare
care specifica
unde vor fi stocate copiile
fragmentului. In continuare ![]() inseamna
variabila de decizie pentru plasament astfel incat
inseamna
variabila de decizie pentru plasament astfel incat 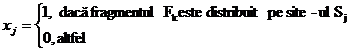
Specificatia exacta este urmatoarea: 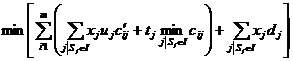 cu
cu ![]()
Al doua parte a functiei obiective calculeaza costul total al depozitarii tuturor copiilor ale fragmentului. Pe de alta parte prima conditie corespunde costului transmiterii reacutalizarii catre toate site-urile care contin copii ale fragmentului , si costul de executie a cererilor de refacere catre site, care vor rezulta intr-un cost minim de transmitere de date.
Acesta este o formulare foarte simplista care nu este potrivita proiectarii bazelor de date distribuite. Dar chiar daca ar fi, mai exista o problema. Aceasta formulare data de Casey in 1972 a fost demonstrat ca este NP- completa(Eswaran1974). S-a demonstrat ca, mai multe formulari ale problemei sunt la fel de grele de-a lungul anilor. Dificultatea este , ca pentru probleme mari , obtinerea de solutii optime nu este realizabila computational. Cercetari considerabile au fost destinate gasirii de logici care sa furnizeze solutii suboptime. Sunt cateva motive pentru care formularile simpliste ca si cea pe care am discutat-o nu sunt potrivite pentru proiectarea bazelor de date distribuite.Acestea sunt inerente pentru toate modelele timpurii de alocari de fisiere pentru retele de calculatoare.
1. In primul rand nu putem trata fragmentele ca fisiere individuale care pot fi alocate pe rand in izolare. Partitionarea unui fragment are impact, de obicei, asupra deciziilor de plasament pentru celelalte fragmente care sunt accesate impreuna, deoarece costul de acces la fragmentele ramase se poate schimba. De aceea trebuie sa se tina cont de relatiile intre fragmente.
2. Accesul la date de catre aplicatii poate fi modelat foarte simplu. O cerere a utilizatorului este adresata unui site si toate datele de raspuns sunt transferate acelui site. In sistemele dazelor de date distribuite accesul la date este mai complicat decat modelul simplu propus "Remote file acces". Asa ca relatiile intre procesele de alocare si interogare ar trebui modelate corespunzator.
3. Aceste modele nu iau in considerare costul mentinerii integritatii chiar daca localizarea a doua fragmente implicate in aceleasi constrangeri de integritate pe doua site-uri diferite, pot fi costisitoare.
4. Similar costul mecanismului de control al concurentei ar trebui luat in considerare.
Pe scurt, sa ne amintim interrelatiile intre problemele de baze de date distribuite infatisate in figura 1.8. Din moment ce alocasia este centrala, relatia sa cu algoritmii implementati pentru alte probleme este nevoie sa fie reprezentata in modelul de alocare. Totusi acest lucru este exact ceea ce face dificila rezolvarea acestor modele. Pentru a separa problemele traditionale de alocare de fisiere de alocarea de fragmente in proiectarea bazelor de date, numim pe prima "file allocation problem"(FAP) si pe cea de-a doua "database allocation problem"( DAP). Nu exista modele euristice generalizate care iau ca date de intrare o multime de fragmente si produce un subiect de alocare aproape optim pentru tipurile de constrangeri discutate aici. Modelele dezvoltate pentru date fac un numar de presupuneri de simplificare si aplicabile unei anume formulari specifice. Asa ca, in loc sa prezentam unul sau mai multi din acesti algoritmi, prezentam un model relativ general, apoi discutam un numar de metode care pot fi folosite pentru rezolvarea algoritmului.
Cereri de informatii.
In stadiul de alocare avem nevoie de informatii cantitative despre daza de date, aplicatii care lucreaza cu ea, limite de depozitare pentru fiecare site din retea. Vom discuta fiecare din aceste detalii.
Informatii despre daza de date.
Pentru a executa fragmentarea orizontala am definit
selectivitatea minternelor. Acum avem nevoie sa extindem definitia la
fragmente si sa definim selectivitatea unui fragment![]() , referitor la interogarea
, referitor la interogarea ![]() . Aceasta este numarul tuplurilor lui
. Aceasta este numarul tuplurilor lui ![]() de care sunt nevoie
pentru a procesa
de care sunt nevoie
pentru a procesa ![]() . Aceasta valoare poate fi notata
. Aceasta valoare poate fi notata ![]() . O alta piesa de informatie necesara
asupra fragmentelor de baze de date este dimensiunea lor. Dimensiunea unui
fragment
. O alta piesa de informatie necesara
asupra fragmentelor de baze de date este dimensiunea lor. Dimensiunea unui
fragment ![]() este determinata prin
este determinata prin ![]() unde
unde ![]() este lungimea (in
biti) unui tuplu al fragmentului
este lungimea (in
biti) unui tuplu al fragmentului ![]() .
.
Informatii despre aplicatii
Majoritatea informatiilor relatate despre
aplicatii sunt deja compilate pe
durata procesului de fragmentare, dar in plus sunt cerute de procesul de
alocare. Cele doua masuri importante sunt numarul de
accesuri de citire pe care o interogare ![]() le face la un fragment
le face la un fragment
![]() in timpul
executiei, si controlul pentru accesul de actualizare. Acesta ar
putea de exemplu sa numere accesele la blocuri cerute de interogare. Mai
avem nevoie sa definim doua
matrici UM si RM cu elemente
in timpul
executiei, si controlul pentru accesul de actualizare. Acesta ar
putea de exemplu sa numere accesele la blocuri cerute de interogare. Mai
avem nevoie sa definim doua
matrici UM si RM cu elemente ![]() si
si ![]() care sunt date de
relatiile:
care sunt date de
relatiile:
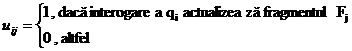
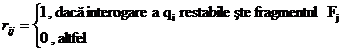
Un vector O cu
valorile O(i) este de asemenea definit, unde O(i) specifica
site-initiator al interogarii ![]() . In sfarsit pentru a defini constanta timp de raspuns
ar trebui specificat timpul maxim de raspuns de alocare al fiecarei
aplicatii.
. In sfarsit pentru a defini constanta timp de raspuns
ar trebui specificat timpul maxim de raspuns de alocare al fiecarei
aplicatii.
Informatii despre site
Pentru fiecare site-computer avem nevoie sa stim despre el
capacitatea de stocate si de procesare. Evident aceste valori pot fi
calculate prin metode de functii elaborate sau prin estimare. Costul de
stocare a datelor pentru o unitate in site-ul ![]() va fi notat cu
va fi notat cu ![]() . De asemenea este
nevoie sa specificam o masura a costului
. De asemenea este
nevoie sa specificam o masura a costului ![]() , ca si costul de
procesare al unei unitati de lucru la site-ul
, ca si costul de
procesare al unei unitati de lucru la site-ul ![]() , unitatea de lucru va fi identica cu aceea a
masurilor RR si UR.
, unitatea de lucru va fi identica cu aceea a
masurilor RR si UR.
Informatii despre retea
In modelul nostru presupunem , existenta unei
retele simple de comunicatii unde costul comunicatiilor
este definit in termenii unei
unitati de data. In
consecinta, ![]() denota costul
comunicatiei pe transfer dintre site-urile
denota costul
comunicatiei pe transfer dintre site-urile ![]() . Pentru a face posibila calcularea
numarului mesajelor folosim fsize ca si dimensiunea in biti a unui transfer. Nu
exista indoiala ca sunt multe modele de retele elaborate care iau in considerare capacitatea de transfer, distanta intre
site-uri, depasirea protocolului, etc. Totusi derivarea acestor ecuatii este deasupra
scopului acestui capitol
. Pentru a face posibila calcularea
numarului mesajelor folosim fsize ca si dimensiunea in biti a unui transfer. Nu
exista indoiala ca sunt multe modele de retele elaborate care iau in considerare capacitatea de transfer, distanta intre
site-uri, depasirea protocolului, etc. Totusi derivarea acestor ecuatii este deasupra
scopului acestui capitol
Modele de alocare
Vorbim despre un model de alocare care incearca sa minimizeze costul total de procesare si de stocare in timp ce incearca sa indeplineasca anumite restrictii de timp de raspuns. Modelul cere il folosim are forma urmatoare:
min(Total Cost ) cu referire la :
restrictii la timpul de raspuns;
restrictii la stocare;
restrictii la procesare;
In aceasta sectiune extindem componentele acestui model bazat pe cererile de informatii discutate in sectiunea 5.4.2.Variabila
de decizie este ![]() care este
definita ca
care este
definita ca
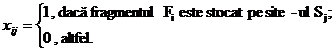
Costul total
Functia cost total are doua componente: procesarea interogarilor si depozitarea. Acestea pot fi exprimate astfel:
![]() unde
unde ![]() este costul
procesarii interogarilor aplicatiei
este costul
procesarii interogarilor aplicatiei ![]() si
si ![]() este costul
stocarii fragmentului
este costul
stocarii fragmentului ![]() la site-ul
la site-ul ![]() .
.
Sa consideram mai intai costul alocarii.
Este dat simplu de: ![]() si cele doua
sume fiind costul total de stocare la toate site-urile
pentru toate fragmentele.
si cele doua
sume fiind costul total de stocare la toate site-urile
pentru toate fragmentele.
Costul procesarii interogarii este mai dificil de specificat. Majoritatea modelelor
FAP se separa in doua componente: costul procesarii de refacere
si costul procesarii de actualizare. Alegem o alta abordare in modelul nostru de alocare a problemelor
DAP si specificam aceasta a consta in costul de procesare(PC) si a
costului de transmitere (TC). Asa ca costul de procesare a
interogarii pentru aplicatia ![]() este
este ![]() .
.
Potrivit schitelor prezentate in sectiunea 5.4.1 componenta de procesare , PC consta in trei factori de cost: costul de acces (AC),
costul de mentinere a integritatii (IE), costul de control al
concurentei (CC). ![]() .
.
Specificatiile detaliate a fiecaruia dintre acesti factori de cost depind de algoritmii folositi pentru a indeplini aceste sarcini. Totusi, pentru a ne demonstra opinia , vom specifica AC in detaliu :
![]()
Primi doi termeni din formula de mai sus calculeaza numarul
acceselor interogarilor utilizator la fragmentul ![]() . Sa retinem ca
. Sa retinem ca ![]() ne dau numarul
total de accese de actualiyare si refacere. Presupunem ca costurile
locale pentru procesarea lor sunt identice. Suma ne da numarul total
de accese pentru toate fragmentele direntionate de
ne dau numarul
total de accese de actualiyare si refacere. Presupunem ca costurile
locale pentru procesarea lor sunt identice. Suma ne da numarul total
de accese pentru toate fragmentele direntionate de ![]() . Inmultirea cu
. Inmultirea cu ![]() ne da costul
acestui acces la site-ul
ne da costul
acestui acces la site-ul ![]() . Folosim din nou
. Folosim din nou ![]() pentru a selecta numai
acele valori de cost pentru site-urile unde fragmentele sunt stocate. O
problema foarte importanta trebuie evidentiata aici.
Functia de cost a accesurilor presupune ca procesarea unei
interogari impica
descompunerea ei intr-un set de
subinterogari care lucreaza fiecare asupra unui fragment stocat pe un
site, urmata de transmiterea
rezultatelor inapoi la site-ul de unde interogarea isi are originea. Cum
am discutat mai inainte, este o vedere foarte simpla care nu ia in considerare complexitatea
procesarii bazelor de date. De
exemplu, functia de cost nu tine seama de costul stabilirii
relatiilor, care se pot face in mai multe feluri. Intr-un model care este
mai realistic decat modelul generic consideram ca aceste probleme nu ar trebui omise.
pentru a selecta numai
acele valori de cost pentru site-urile unde fragmentele sunt stocate. O
problema foarte importanta trebuie evidentiata aici.
Functia de cost a accesurilor presupune ca procesarea unei
interogari impica
descompunerea ei intr-un set de
subinterogari care lucreaza fiecare asupra unui fragment stocat pe un
site, urmata de transmiterea
rezultatelor inapoi la site-ul de unde interogarea isi are originea. Cum
am discutat mai inainte, este o vedere foarte simpla care nu ia in considerare complexitatea
procesarii bazelor de date. De
exemplu, functia de cost nu tine seama de costul stabilirii
relatiilor, care se pot face in mai multe feluri. Intr-un model care este
mai realistic decat modelul generic consideram ca aceste probleme nu ar trebui omise.
Factorul cost de mentinere a intergitatii poate fi specificat de multe ori, ca si componenta de procesare, cu exceptia cand costul locat de procesare pentru o unitate va trebui probabil sa se schimbe pentru a reflecta adevaratul cost al mentinerii integritatii.Din moment ce verificarea integritatii si metodele de control al concurentei sunt discutate mai tarziu in carte, nu este necesar sa studiem aceste componente de cost in detaliu aici.
Functia de transmitere a costului este formulata in liniile functiei costului de acces. Totusi, depasirea transmiterii de date de actualizare si acelea pentru cererile de refacere sunt destul de diferite. In interogarile de actualizare este nevoie sa informam toate site-urile unde exista copii, in timp ce pentru interogarile de refacere este suficient sa accesam numai una din copii. La finalul unei interogari de actualizare nu exista nici o transmisie de date inapoi catre site-ul initiator, in afara de un mesaj de confirmare, unde se pot gasi transmisiile de date importante. Componenta de actualizare a functiei de transmitere este :
![]() .
.
Primul termen este pentru transmiterea mesajului de
actualizarede la site-ul initiator o(i) al lui ![]() catre toate copiile
fragmentului care trebuie actualizat. Al doilea termen este pentru confirmare.
catre toate copiile
fragmentului care trebuie actualizat. Al doilea termen este pentru confirmare.
Costul de refacere poate si specificat astfel:
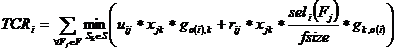 .
.
Primul termen in TCR reprezinta costul transmiterii interogarii de refacere catre acele site-uri care au copii ale fragmentului ce trebuie accesat. Al doilea termen conteaza pentru transmiterea
rezultatelor de la aceste site-uri la site-urile initiatoare. Ecuatia
ne spune ca dintre toate site-urile cu copii ale aceluiasi fragment, numai site-ul care detine
costul total minim de transmitere ar trebui selectat pentru executia
operatiei.Functia de cost pentru interogarea ![]() transmitere poate fi
specificata astfel:
transmitere poate fi
specificata astfel: ![]() care specifica pe
deplin functia de cost total.
care specifica pe
deplin functia de cost total.
Constrangeri
Functiile de constrangere pot fi specificate in detalii similare. Totusi, in loc sa descriem aceste functii ca atare, vom indica cum ar trebui sa arate. Restrictia de timp de raspuns este specificata astfel:
Timp_de_executie_al_lui qi Timp_maxim_de_raspuns_al_lui qi qi Q
De preferat masura de cost in functia propriu-zisa ar trebui specificata in termeni de timp, ceea ce face specificatia restrictiei de timp de raspuns imediata. Restrictia de stocare este :
![]() unde restrictia
de procesare este
unde restrictia
de procesare este ![]() . Aceasta completeaza proiectul nostru de model de
alocare. Chiar daca nu l-am dezvoltat in totalitate, precizia din unii
termeni indica cum trebui sa formulam o asemenea
problema.Ca adaugare la acest
aspect am indicat lucrurile importante care trebuie referite in modelele de alocare.
. Aceasta completeaza proiectul nostru de model de
alocare. Chiar daca nu l-am dezvoltat in totalitate, precizia din unii
termeni indica cum trebui sa formulam o asemenea
problema.Ca adaugare la acest
aspect am indicat lucrurile importante care trebuie referite in modelele de alocare.
Copyright © 2026 - Toate drepturile rezervate