|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
Prelucrarea datelor experimentale prin regresie
Activitatea unui inginer presupune lucrul cu numere, nu in sens abstract (ca in matematica) sau virtual (ca in finante), ci avand marimi si masuri foarte bine precizate (vezi Partea I). Valorile absolute ale marimilor sunt mai importante ca in fizica, de aceea se face raportarea permanenta la experimente. Datele numerice manevrate de inginer sunt intotdeauna rezultatele unor experimente - uneori proprii (masurate intr-o instalatie de laborator, prototip sau pilot, vezi Preliminarii), cel mai adesea insa preluate (adoptate) din literatura (reviste, enciclopedii, baze de date). Extrem de putine valori numerice (ale constantelor universale mai uzuale) pot fi memorate (impreuna cu unitatile lor), dar si in aceste cazuri se recomanda consultarea unor surse bibliografice, macar pentru o eventuala precizie superioara (vezi Anexele II si III).
Dupa prelevarea unor date experimentale, prima activitate ce trebuie desfasurata este prelucrarea primara, indispensabila in cazul datelor proprii si care trebuie considerata efectuata deja de autori in cazul datelor preluate (din surse de incredere!). Aici intra aplicarea unor metode de analiza numerica (statistica matematica) - devenite clasice - in scopul corelarii datelor (fitting), adica verificarii credibilitatii acestora si eliminarii eventualelor valori eronate (grosolan, accidental, sistematic) din setul de determinari, astfel incat acesta sa devina self-consistent. Uneori, prelucrarea primara poate impune chiar necesitatea unor determinari suplimentare (reluate sau extinse), dupa care intreaga procedura se reia pentru noul set de date.
Prin corelare se intelege stabilirea unei dependente functionale intre marimile masurate - cel mai simplu caz se refera la masurarea a doua caracteristici, x si y, in scopul gasirii functiei de legatura y = f(x). Aceasta simplificare este extrema deoarece nu exista in natura fenomene care sa fie descrise de numai doua marimi - intotdeauna vor exista si alte influente (perturbatii sau fluctuatii), ca sa nu mai vorbim de imprecizii ale metodei, aparatelor sau chiar experimentatorului. Considerand valabila (la o anumita scala si pe un anumit domeniu) dependenta de mai sus, sa subliniem ca exista doua cazuri, complet diferite din punct de vedere fizic, tratate insa identic din punct de vedere statistic! În primul caz, forma functiei f este cunoscuta, eventual pana la o constanta (coeficient, factor, exponent, termen liber), din legile fizicii - exista si situatia in care se doreste chiar verificarea legii (sau regulii) respective, deci f se cunoaste in totalitate. Al doilea caz are in vedere situatia in care nu se cunoaste nici macar forma dependentei y(x), corelarea datelor neavand decat alternativa incercarii unor dependente tipice din punct de vedere matematic (polinom, putere, exponentiala, logaritmica, etc.). Statistic vorbind, ambele cazuri vor fi tratate identic, pentru ca legile fizicii respecta (in general) acelasi tip de dependente - mai mult, din diverse ratiuni (simplificari, neglijari, generalizari), modelele din fizica se abat de la realitate (vezi cazul gazului ideal) si trebuie "ajustate" oricum pentru corectii de acelasi tip (coeficienti, exponenti, termeni liberi). Se obtin astfel relatii empirice, bazate in totalitate pe analiza numerica a datelor experimentale - corelate fara a sti vreo forma a dependentei y(x), respectiv semi-empirice (au la baza o lege fizica, ajustata astfel incat sa corespunda unui set de date experimentale). Trebuie subliniat ca toate cantitatile numerice obtinute astfel (aflarea functiei f se numeste regresie) sunt dependente de unitatile de masura in care au fost introduse datele experimentale! Practic, aceste constante sunt dimensionale (vezi Partea I, capitolul 3 si Anexa III) si trebuie manevrate cu atentie. Majoritatea lor (mai ales in cazul modelelor empirice) nu au nici macar un sens fizic!
Prezentam mai jos principiile regresiei liniare si multiliniare. Se va opera cu termeni specifici statisticii, cum ar fi medii, dispersii (imprastieri), abateri (erori) relative sau absolute, coeficient de corelatie, etc. Informatii complete pot fi gasite in orice carte de specialitate - s-au indicat cateva in Bibliografie. Cea mai simpla metoda de regresie este cea liniara, numita si "metoda celor mai mici patrate" (in acelasi timp este si cea mai veche!). Daca se postuleaza (sau se stie!) dependenta:
![]() (A.1)
(A.1)
(adica ecuatia unei drepte), gasirea "formei" f inseamna aflarea celor doi parametri, ordonata la origine (b0), respectiv panta (coeficientul unghiular), b1. Se aplica un algoritm de optimizare, mai exact de minimizare a patratelor abaterilor, exprimate ca diferente intre valorile calculate cu (A.1) si notate ycalc, respectiv cele masurate, notate yexp:
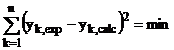 (A.2)
(A.2)
S-a notat cu n - numarul de (perechi de) valori determinate experimental. Datorita ridicarii la patrat semnele diferentelor dispar, astfel ca nu conteaza ordinea din expresia (A.2) si nu poate interveni o "compensare" a abaterilor pozitive cu cele negative. În sens grafic, procedura echivalenta este de a "duce o dreapta printre punctele experimentale", astfel incat suma deviatiilor sa fie cat mai mica (minima). Analiza numerica are drept scop inlaturarea impreciziei si subiectivismului (!), inerente unui procedeu grafic.
Conditia de minim din (A.2) este echivalenta cu anularea derivatelor partiale de ordinul I in raport cu necunoscutele, adica cei doi parametri ai regresiei, b0 si b1:
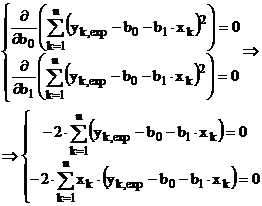
Se obtine un sistem de doua ecuatii ce poate fi scris in forma matriceala (dupa simplificare, rearanjare si introducerea sumelor in paranteze, deoarece ele actioneaza doar pentru xk si yk):
 (A.3)
(A.3)
Se observa ca determinantul sistemului este simetric fata de prima diagonala, precum si faptul ca, pentru rezolvarea sistemului prin metoda stiuta, trebuie evaluate sumele ce joaca rol de coeficienti. Daca pana nu demult se recomanda intocmirea unui tabel si efectuarea de sume pe coloane, astazi se poate lucra in Microsoft Excel, software ce cuprinde facilitati pentru ambele aspecte (tabel si sumare). Dupa obtinerea celor doi parametri, ecuatia de regresie liniara trebuie verificata! Subliniem ca aceasta etapa, de obicei trecuta cu vederea, este la fel de importanta ca celelalte - aici intra teste de semnificatie ale coeficientilor, experimente repetate in acelasi punct, etc. De regula se calculeaza doar coeficientul de corelatie (aici liniara), dupa formula:
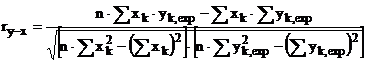 (A.4)
(A.4)
Se observa ca in (A.4) intervin aceleasi sume care figureaza si in determinantul sistemului (A.3) ori in termenii liberi (deci calculate deja!). Valorile acestui coeficient de corelatie sunt cuprinse intre 0 si 1 - deci alta marime de tip fractie! - semnificatia lui fiind apropierea relativa intre linia (aici dreapta) de regresie si punctele experimentale. O corelatie "puternica" va calcula acest coeficient foarte putin subunitar, in vreme ce una "slaba" va gasi valori mult subunitare, apropiate chiar de zero! Explicatia este simpla - forma ecuatiei de regresie (aici dreapta) s-a considerat a priori valabila; daca insa exista influente necuantificate (adica sunt variabile independente suplimentare!) in datele experimentale, punctele se vor abate foarte mult (mai ales la marginile intervalului) de la ecuatia propusa (practic, graficul nu mai este o dreapta!).
În situatia descrisa mai sus (cand corelatia liniara se dovedeste falimentara), echivalenta cunoasterii a priori a unei dependente neliniare, algoritmul descris aici poate fi generalizat la asa-numita regresie multiliniara. De exemplu, o functie liniara dependenta de doua variabile independente care se doreste a fi gasita prin regresie are forma:
![]() (A.5)
(A.5)
Dupa un tratament absolut similar (abateri patratice minimizate, sistem omogen generat de anularea derivatelor partiale), consecinta aparitiei termenului suplimentar este regasita in "bordarea" ecuatiei matriceale (A.3) cu linii si coloane corespunzatoare noii variabile, forma elementelor fiind aceeasi:
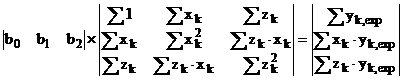
Determinantul sistemului a fost construit tinand cont de simetria fata de prima diagonala, precum si de scrierea liniilor 2 si 3 pornind de la prima linie amplificata pe rand cu xk, respectiv zk (valabil si pentru coloana termenilor liberi). Devine limpede procedura prin care se poate "extinde" regresia la oricate variabile independente, forma ecuatiei fiind in continuare liniara. Se complica doar evaluarea determinantilor - probabil ca utilizarea computerelor devine indispensabila (vezi exemplul de mai jos). Absolut acelasi lucru se obtine si daca se doreste o regresie patratica (parabolica), sau, mai general, polinomiala - daca in relatia (A.5) se substituie variabila z cu x2 ecuatia matriceala devine:
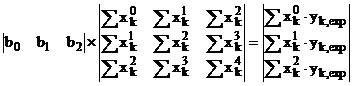
in care, pentru simetrie, s-a inlocuit 1 cu x0. Este foarte clar procedeul prin care se poate extinde regresia la ecuatii cubice sau de orice ordin. Observati ca forma elementelor determinantului se preteaza perfect la utilizarea calculatorului, precum si faptul ca sumele ce trebuie calculate suplimentar sunt tot mai putine.
Aplicatie
Sa se stabileasca ecuatia de regresie cubica pentru datele de mai jos:

Se utilizeaza pachetul software Microsoft Excel, in care se completeaza primele 3 coloane cu datele problemei. Se exploateaza facilitatile de calcul functional si optiunea Auto Fill pentru obtinerea celorlalte coloane si a liniei de sumare de la baza tabelului. Fiind in posesia tuturor elementelor din ecuatia matriceala, se poate rezolva sistemul si afla coeficientii regresiei cubice. Este recomandabil sa utilizam tot Microsoft Excel - pe de o parte, calculul determinantilor de rangul 4 este destul de laborios, iar pe de alta parte, pachetul software are o sectiune destinata special calculului de regresie! O prima varianta ar fi reprezentarea grafica (XY Scatter) a punctelor (X, Yexp), dupa care se apeleaza (cu right click pe unul din puncte) optiunea Add Trendline, de unde alegem regresia dorita (aici polinomiala, de gradul 3) si bifam optiunile Display equation on chart, respectiv Display R-squared on chart:
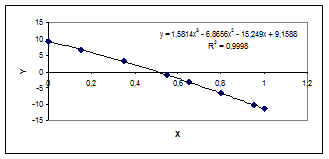
astfel incat, impreuna cu parametrii regresiei, obtinem si confirmarea ca ecuatia obtinuta reprezinta foarte bine datele experimentale. Eventual, se pot incerca mai multe regresii polinomiale (de diverse ordine) urmarind valorile parametrului ry-x in scopul maximizarii lui (acesta nefiind proportional cu rangul polinomului!).
În sfarsit, procedura de regresie multiliniara poate fi extinsa la (aproape) orice dependenta y(x), cu conditia liniarizarii ei prealabile prin artificii matematice (logaritmari, inversari ori combinari de variabile, etc.). De exemplu, aflarea parametrilor cinetici din relatia Arrhenius (I.11) presupune artificiul:
![]()
astfel ca identificarea cu relatia (A.1) conduce la necesitatea logaritmarii constantei de viteza si la inversarea temperaturii in vederea aplicarii algoritmului (prelucrare primara in raport cu regresia). Ulterior aflarii constantelor, trebuie facuta delogaritmarea lui b0 pentru aflarea lui k0, respectiv inmultirea cu (- RG) pentru calculul energiei de activare.
Aplicatie
Sa se afle parametrii cinetici prin regresie pe urmatoarele date experimentale:
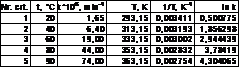
Dupa
prelucrarile din coloanele 4 ÷ 6 se face reprezentarea
grafica, se adauga linia si ecuatia de regresie,
calculand in final ![]() , respectiv (vezi Anexa II pentru valoarea lui RG)
, respectiv (vezi Anexa II pentru valoarea lui RG)
![]() .
.
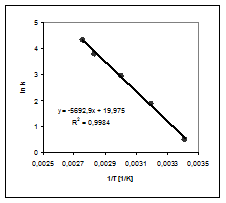
Un alt exemplu este aflarea coeficientilor din ecuatia Antoine (vezi Partea a II-a, capitolul 2) din date experimentale de presiuni de vapori functie de temperatura
![]()
Forma relatiei reclama in cadrul prelucrarii primare atat logaritmarea presiunii (cu logaritm natural sau zecimal), cat si aducerea expresiei in forma:
![]()
Deoarece dependenta are forma (A.5), se poate aplica regresia multiliniara - observati combinarea variabilelor si a constantelor! Desigur ca sunt necesare si calcule suplimentare pentru "revenirea" la constantele initiale (aici pentru B0).
Nu este indispensabila reprezentarea grafica pentru calculul si afisarea ecuatiei de regresie liniara in Microsoft Excel. Alternativa o constituie utilizarea functiilor pre-definite din grupul Statistical: panta si ordonata la origine pot fi calculate direct din tabelul de date primare cu slope, respectiv intercept; daca nu intereseaza constantele din ecuatia de regresie liniara, ci utilizarea datelor respective pentru prezicerea unei valori a variabilei dependente, se poate apela o alta functie, forecast (aceasta functie poate fi utilizata si pentru calculul valorilor ycalc in vederea estimarii erorilor absolute si relative, ca in exemplul de mai jos).
Aplicatie
Într-un experiment de filtrare s-au obtinut urmatoarele perechi de date (volum filtrat, in cm3 - timp de colectare, in min):

Ordonata la origine b0, respectiv panta b1, din ecuatia de regresie liniara (A.1) se calculeaza cu functiile amintite (intercept si slope) in extremitatea dreapta a tabelului; cu ajutorul lor putem calcula apoi datele din ultima coloana, Vcalc. Utilizarea functiei forecast este ilustrata in tabel prin calculul "derivatelor" (de fapt, a rapoartelor de diferente) din coloana (dt / dV)calc - pentru comparatie, se reprezinta grafic si valorile experimentale ale acestui raport, utilizate de altfel ca argumente in functia respectiva, impreuna cu volumele corespunzatoare:
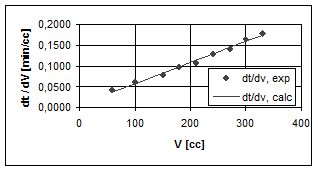
A doua etapa majora de prelucrare a datelor experimentale (atat proprii cat si adoptate) o reprezinta reconcilierea. Cu foarte putine exceptii, masuratorile care au produs setul de determinari (self-consistent) s-au mai facut, chiar daca in conditii diferite si/sau instalatii diferite (principial sau constructiv), ori au fost efectuate mai mult sau mai putin similar, insa au fost prelucrate (primar) cu alte tehnici! Trebuie avut in vedere faptul ca toate datele publicate (disponibile!) au suferit (in principiu) o prelucrare primara, eventual si reconcilieri cu determinari mai vechi. La ora actuala, accesul la o baza de date simplifica mult lucrurile, pentru ca toate aceste eforturi au fost facute deja insa costul acestui acces poate fi destul de ridicat (fie ca este vorba de baze de date mici, "portabile", incluse in pachete software de simulare, cum ar fi HYSYS, fie ca se are in vedere accesul prin Internet la baze de date uriase, tip DECHEMA). Trebuie considerata deci si aceasta faza, a verificarii corelatiilor obtinute pe seturi de date mici (proprii sau preluate) in raport cu alte corelatii (mai mult sau mai putin) asemanatoare disponibile (ori testarea lor pe alte seturi de date).
Copyright © 2025 - Toate drepturile rezervate