|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
VERIFICAREA SEMNIFICATIEI STATISTICE
A REZULTATELOR ESTIMARII.
TESTUL T. TESTUL F
Motivele pentru care etapa verificarii nu trebuie sa fie absenta in activitatea de elaborare si utilizare a reprezentarilor econometrice pot fi redate, seccint, astfel:
- datele utilizate provin dintr-un esantion care nu intotdeauna este reprezentativ;
- rolul cauzelor accidentale ca si cel al intamplatoarelor analogii in ceea ce priveste evolutiile factorilor inclusi in model poate conduce la estimatii pentru parametrii care fie contrazic aspecte evidente si anticipate din economie, fie exprima deformat rolul factorilor;
- lipsa de experienta si subiectivismul celui care elaboreaza modelul econometric, slabiciuni care se manifesta fie la alegerea factorilor, fie la la alegerea functiei.
Ca urmare, se recomanda: a) verificari prin confruntarea cu realitatea economica cunoscuta din teorie sau din practica; b) verificarea, in sens statistic, a semnificatiei rezultatelor estimarii; c) verificarea modalitatii in care o serie de ipoteze se regasesc in semnalele pe care ni le transmit rezultatele aplicarii modelului.
In acest capitol ne referim la recomandarile a) si b) iar in capitolul urmator ne va sta in atentie cea de a 3-a recomandare.
1. Verificari ale rezultatelor modelarii prin compararea acestora cu realitatea economica
In cele ce urmeaza ne referim, pe scurt, la o prima apreciere a rezultatelor bazata pe unele cunostiinte apriorice privind procesul analizat, dar si erorile asteptate.
Astfel, semnul parametrului poate confirma sau infirma cele cunoscute din teoria si practica economica. Daca, de exemplu, avem in vedere relatia pret-vanzari, ne asteptam ca semnul parametrului "atasat" pretului sa fie minus, asa cum in cazul unei functii de productie ne asteptam ca semnul sa fie plus. Daca, in urma estimarii, astfel de asteptari nu sunt confirmate se recomanda efectuarea de verificari in ce priveste corectitudinea calculelor, corectitudinea datelor utilizate pentru estimare, calitatea specificarii in sensul reevaluarii numarului de factori sau a functiei pentru care am optat.
In exemplul considerat (tab. 3.1), ne asteptam ca atat veniturile in crestere cat si investitiile si implicit oferta in crestere sa influenteze in sensul cresterii cererii, ceea ce semnul pozitiv al ambelor estimatii confirma.
Un
alt gen de verificare a etapelor parcurse presupune generarea de valori ![]() pe baza modelului estimat si compararea lor cu datele
empirice (rezultate din observarea "pe teren" privind variabila y).
Generarea de valori implica inlocuirea in model al simbolurilor
pe baza modelului estimat si compararea lor cu datele
empirice (rezultate din observarea "pe teren" privind variabila y).
Generarea de valori implica inlocuirea in model al simbolurilor ![]() cu estimatiile
pentru parametrii si atribuirea de valori factorilor asa cum
rezulta din tabelul cu date (3.1.). reamintim ca
cu estimatiile
pentru parametrii si atribuirea de valori factorilor asa cum
rezulta din tabelul cu date (3.1.). reamintim ca ![]() ;
; ![]() ;
; ![]() .
.
![]()
![]()
![]()
![]()
![]()
![]()
Ne asteptam ca valorile ajustate sa fie asemanatoare cu cele empirice, abaterile sa fie relativ mici, avand o evolutie intamplatoare atat ca semn cat si ca marime. Daca dimpotriva, abaterile sunt relativ mari sau prezinta o succesiune sistematica atunci avem motive sa revedem fie calculele, fie datele, fie specificarea.
In aplicatia la care facem referire abaterile pot fi apreciate ca fiind relativ mici si aleatoare ca succesiune.
2. Verificarea semnificatiei statistice a fiecarui parametru estimat. Testul T
Obiectivul verificirii consta in aprecierea in sens statistic a marimii estimatiei obtinute asa incat sa putem afirma, intr-un mod cat mai obiectiv, ca respectiva estimatie releva ceva semnificativ, care nu s-ar dataora intamplarii si, ca urmare, factorul al carui rol este cuantificat este realmente determinant pentru procesul analizat. Desigur, rezultatele testului pot confirma sau infirma o astfel de asteptare.
Pebtru o mai buna intelegere a domeniului verificarilor de natura statistica, este necesara o prealabila familiarizare cu principalele notiuni specifice precum:
- semnificatie - importanta, relevanta, deosebire marcanta a rezultatului estimarii in raport cu ceea ce ar rezulta ca urmare a jocului intamplarii. Similar poate fi apreciata abaterea dintre doua marimi de aceeasi natura in sensul aprecierii daca abaterea este semnificativa, datorita unei cauze relevante, sau nesemnificativa, datorata intamplarii.
- test statistic - procedeu ale carui etape conduc la o concluzie cu privire la o ipoteza preformulata care poate fi confirmata sau respinsa in baza unei repartitii si a unei probabilitati de a gresi in ce priveste concluzia.
-
nivel (prag) de semnificatie -
probabilitate, de regula, prestabilita cu privire la riscul de a
gresi in concluzia finala. Astfel, acceptam ca in 5% din
cazuri concluzia prin care se afirma ca ipoteza nula este
falsa, poate fi gresita (ceea ce ar insemna ca ipoteza
nula este corecta). Intrucat apelam la datele unui esantion
este necesar sa stabilim o limita superioara ![]() (prag de
semnificatie) pana la care acceptam inerenta incertitudine,
ramanand un nivel de incredere rezonabil de mare (1-
(prag de
semnificatie) pana la care acceptam inerenta incertitudine,
ramanand un nivel de incredere rezonabil de mare (1-![]() );
);
- interval de incredere - distanta dintre 2 valori in cadrul careia se plaseaza cu o probabilitate rezonabil de mare parametrul care formeaza obiectul estimarii. Daca un astfel de interval il denumim bilateral, intrucat se extinde de o parte ti de alta a unui nivel-pivot, intervalul unilateral se refera la distanta dintre nivelul-pivot si una dintre limitele extreme.
-
repartitie statistica -
multimea perechilor ordonate de valori ![]() si
si ![]() reprezentand, fiecare
dintre perechi, nivelul variabilei aleatoare (
reprezentand, fiecare
dintre perechi, nivelul variabilei aleatoare (![]() ) si probabilitatea (P
) si probabilitatea (P![]() ), pozitiva sau nula, de realizare a respectivului
nivel
), pozitiva sau nula, de realizare a respectivului
nivel ![]() ;
;
- grade de libertate - coordonate independente in sensul de valori liber alese pe care le poate inregistra o variabila daca este restrictionata de conditii ce pot fi prestabilite;
-
ipoteza statistica -
presupunere cu privire la repartitia urmata de o variabila sau
cu privire la parametrii si semnificatia acestora. Astfel de
presupuneri urmeaza sa fie verificate asa incat sa rezulte
fie acceptarea ipotezei nule (![]() ), de tip negativist, fie acceptarea ipotezei alternative (H
), de tip negativist, fie acceptarea ipotezei alternative (H![]() ) a confirmarii supozitiei initiale;
) a confirmarii supozitiei initiale;
- nivelul calculat nivel tabelat - daca nivelul calculat rezulta in urma aplicarii, de catre cel interesat, a unei formule care, de regula, genereaza valori comparabile cu cele specifice unei anumite repartitii, nivelul tabelat rezulta in urma preluarii lui dintr+un tabel, corespunzator repartitiei, nivel pozitionat la "intersectia" pragului de semnificasie acceptat si gradele de libertate.
Intregul
demers presupus de testul t se
bazeaza pe prezumtia conform careia abaterile estimatiei ![]() de la media sa M(
de la media sa M(![]() ), care s-ar obtine in cazul repetarii
estimarii pentru mai multe esantioane de volum identic, urmeaza
o repartitie normala. Daca avem in vedere ca abaterea de la
medie impartita la abaterea medie patratica
), care s-ar obtine in cazul repetarii
estimarii pentru mai multe esantioane de volum identic, urmeaza
o repartitie normala. Daca avem in vedere ca abaterea de la
medie impartita la abaterea medie patratica ![]() urmeaza, pentru
esantioane de volum mic (n<30), repartitia Student (de unde
nivelul t-tabelat), ne
intereseaza o astfel de transformare a estimatiei obtinute incat
sa devina comparabila cu nivelul t-tabelat pentru (n-k) grade de libertate si un risc
urmeaza, pentru
esantioane de volum mic (n<30), repartitia Student (de unde
nivelul t-tabelat), ne
intereseaza o astfel de transformare a estimatiei obtinute incat
sa devina comparabila cu nivelul t-tabelat pentru (n-k) grade de libertate si un risc ![]() apriori ales.
apriori ales.
Intrucat,
de regula, nu dispunem de mai multe esantioane ci, la fel ca si
in aplicatia exemplificata, avem date pentru un singur esantion,
preferam sa consideram abaterea estimatiei in raport cu
zero ![]() . Acesta ar fi motivul pentru care ne pronuntam in
urma acestui test, cu privire la deosebirea semnificatica sau
nesimnificativa a estimatiei in raport cu zero. Relatia de
calcul, folosind notatiile
. Acesta ar fi motivul pentru care ne pronuntam in
urma acestui test, cu privire la deosebirea semnificatica sau
nesimnificativa a estimatiei in raport cu zero. Relatia de
calcul, folosind notatiile ![]() pentru estimatia
supusa verificarii si
pentru estimatia
supusa verificarii si ![]() pentru abaterea medie
patratica a estimatiei este urmatoarea:
pentru abaterea medie
patratica a estimatiei este urmatoarea:
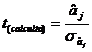 (1)
(1)
Rezultatul se compara cu nivelul tabelat (repartitia Student anexa II) pentru un risc acceptat si un numar de grade de libertate egal cu numarul de cazuri minus numarul de parametrii din model (k=3 in modelul bifactorial). Asadar, n*g*l=15-3=12.
In cele ce urmeaza ne referim concret la etapele verificarii folosind, pentru exemplificare, rezultatele estimarii obtinute in etapa anterioara.
1.
stabilirea ipotezei nule, a nesemnificatiei (H![]() ): estimatia rezultata nu fifera semnificativ
de zero.
): estimatia rezultata nu fifera semnificativ
de zero.
In
aplicatia la care ne referim aceasta ar insemna ca atat ![]() cat si
cat si ![]() sau
sau ![]() , prezinta valori doar intamplator diferite de zero
si aceasta, probabil, din cauza unor "potriviri" intamplatoare a
datelor.
, prezinta valori doar intamplator diferite de zero
si aceasta, probabil, din cauza unor "potriviri" intamplatoare a
datelor.
2. Repartitia pe care o avem in vedere este repartitia Student, esantionul fiind relativ mic (n=15<
3.
nivelul calculat (t-calc) reyultat pe baza relatiei (1) presupune ca in
prealabil sa estimam abaterea medie patratica privind
estimatia - ![]() .
.
In cazul modelului unifactorial y=a+bx+u abaterea medie patratica rezulta astfel:
-
pentru estimatia ![]() ,
, 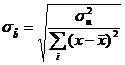 (2)
(2)
-pentru
estimatia ![]() ,
, 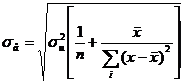 (3)
(3)
In
cazul multifactorial recomandam untilizarea valorilor centrate Y=y-![]() , respeectiv, X=x-
, respeectiv, X=x-![]() ; Z=z-
; Z=z-![]() , asa cum am procedat ib etapa estimarii (3.16,
.317, 3.17a), caz in care utilizam relatiile:
, asa cum am procedat ib etapa estimarii (3.16,
.317, 3.17a), caz in care utilizam relatiile:
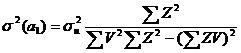 (4)
(4)
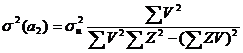 (5)
(5)
iar dispersia ![]() va fi inlocuita
cu estimata ei (
va fi inlocuita
cu estimata ei (![]() ) obtinuta pe baza relatiei:
) obtinuta pe baza relatiei:
![]() , unde k=numarul de parametrii (6)
, unde k=numarul de parametrii (6)
In
sitauatiile in care in vederea estimirii utilizam relatia (3.29)
mai simplu este sa multiplicam matricea inversa (X'X)![]() cu un scalar reprezentat de valoarea estimata a
dispersiei variabilei reyiduale,
cu un scalar reprezentat de valoarea estimata a
dispersiei variabilei reyiduale, ![]() (6).
(6).
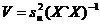 (6a)
(6a)
Rezultatele
obtinute in urma inmultirii constantei cu elementele de pe diagonala
matricei inverse notate ![]() reprezinta
dispersiile pentru factorii considerati in succesiunea aparitiei lor
in model. In ce priveste abaterea medie patratica (
reprezinta
dispersiile pentru factorii considerati in succesiunea aparitiei lor
in model. In ce priveste abaterea medie patratica (![]() ) utila pentru testarea fiecarui parametru
(numitorul relatiei 1), aceasta este data de estimatie ei (s):
) utila pentru testarea fiecarui parametru
(numitorul relatiei 1), aceasta este data de estimatie ei (s):
![]() (6b)
(6b)
Preluarea din tabelul repartitiei Student
a valorii corespunzatoare riscului acceptat (![]() ) si numarului gradelor de libertate g*l=n-k. In
exemplu nostru g*l=15-3=12 si
) si numarului gradelor de libertate g*l=n-k. In
exemplu nostru g*l=15-3=12 si ![]() =0,05, asadar
=0,05, asadar ![]() .
.
5. Comparatia dintre nivelul t-calculat si nivelul t-tabelat in vederea confirmarii (daca t-calculat<t-tabelat) sau infirmarii (daca t-calculat>t-tabelat) ipotezei nule.
Mentiuni cu privire la utilizarea testului t:
- semnul fiecirui parametru nu influenteaza rezultatul comparatiei dintre t-calculat si t-tabelat intrucat retinem pentru calculul raportului (1) estimatia in valoare absoluta, asa incat raportul nu poate fi decat pozitiv;
- in cazurile in care datele provin dintr-un esantion relativ mare, adica n>30, putem apela la repartitia normala redusa pentru care apare in anexa 1 variabila z, care va fi considerata nivelul t-tabelat (numarul gradelor de libertate nu mai reprezinta o coordonata);
-
riscul notat cu![]() (de a comite o eroare de genul l in sensul acceptarii a ceea ce n-ar trebui acceptat) poate
fi egal cu 0,05; daca dorim o precizie mai mare, putem alege o valoare mai
mica precum 0,025 sau 0,01 sau 0,001, asa cum, daca
acceptam un risc mai mare de a ajunge la o concluzie gresita,
putem opta pentru
(de a comite o eroare de genul l in sensul acceptarii a ceea ce n-ar trebui acceptat) poate
fi egal cu 0,05; daca dorim o precizie mai mare, putem alege o valoare mai
mica precum 0,025 sau 0,01 sau 0,001, asa cum, daca
acceptam un risc mai mare de a ajunge la o concluzie gresita,
putem opta pentru ![]() =0,10;
=0,10;
-
daca suntem interesati in stabilirea unui interval de incredere in
cadrul caruia sa avem suficiente garantii (ceea ce depinde de
praful de semnificatie (![]() ) acceptat) ca se situeaza adevarata valoare a
parametrului a
) acceptat) ca se situeaza adevarata valoare a
parametrului a![]() (deci nu cea estimata ci cea care s-ar obtine
daca am avea date pentru intreg ansamblul de cazuri), putem sa ne
bazam in continuare pe ratiunile care au stat la baza testului t. La acestea adaugam si
urmatoarele aspecte demonstrabile: media estimatiilor se aproprie
pana la coincidenta de valoarea adevarata a parametrului
(calitatea estimatiei
(deci nu cea estimata ci cea care s-ar obtine
daca am avea date pentru intreg ansamblul de cazuri), putem sa ne
bazam in continuare pe ratiunile care au stat la baza testului t. La acestea adaugam si
urmatoarele aspecte demonstrabile: media estimatiilor se aproprie
pana la coincidenta de valoarea adevarata a parametrului
(calitatea estimatiei ![]() de a fi
nedeplasata),
de a fi
nedeplasata), ![]() ; parametrul se poate situa ca marime peste sau sub
valoarea estimata (
; parametrul se poate situa ca marime peste sau sub
valoarea estimata (![]() ), asa incat probabilitatea de a gresi (notata
), asa incat probabilitatea de a gresi (notata
![]() ) este divizata, in sensul ca se accepta
) este divizata, in sensul ca se accepta ![]() pentru fiecare dintre
cele 2 subintervale. Ca urmare,
pentru fiecare dintre
cele 2 subintervale. Ca urmare, ![]() in care
in care ![]() , pentru un risc acceptat (
, pentru un risc acceptat (![]() ). Daca izolam pe
). Daca izolam pe ![]() si avem in vedere
"diviziunea riscului" putem reda acest raport si in forma
si avem in vedere
"diviziunea riscului" putem reda acest raport si in forma
![]()
![]()
unde
![]() =estimatia abaterii medii patrate (vezi 2, 3, 6.b)
=estimatia abaterii medii patrate (vezi 2, 3, 6.b)
In acest fel am stabilit intervalul de incredere pentru un parametru oarecare din model.
Daca
ne propunem sa exemplificim pentru parametrul a![]() din aplicatia care ne sta in atentie, atunci
avem in vedere ca
din aplicatia care ne sta in atentie, atunci
avem in vedere ca ![]() iar
iar ![]() asa incat,
corespunzator formulei (9) obtinem:
asa incat,
corespunzator formulei (9) obtinem:
![]()
ceea ce inseamna
ca putem afirma, cu o probabilitate de a nu gresi de 0,95, ca
adevarata marime a parametrului ![]() se situeaza intre
1,15 si 4,5349.
se situeaza intre
1,15 si 4,5349.
3. Verificarea semnificatiei rolului ansamblului factorilor asupra variabilei efect. Testul F
Testul F urmareste verificarea semnificatiei simultane a tuturor estimatiilor obtinute pentru parametrii. Rezultatul verificarii se refera asadar, la aprecierea pe ansamblu a modelului, considerat ca o reprezentare care descrie un mecanism relational complet diferit de ceea ce ar putea fi atribuit intamplarii.
Modelul
de regresie descrie rolul factorilor determinanti prin parametrii de
regresie iar efectul conjugat al factorilor determinanti rezulta
inlocuind parametrii cu estimarile obtinute iar factorilor
atribuindu-le valori, ceea ce condice la obtinerea de "valori ajustate": ![]() .
.
Valorile
ajustate (![]() ) se abat de la medie (
) se abat de la medie (![]() ) in masura in care se abat la randul lor de la medie,
actionand mai intens sau mai putin intens. Ca urmare, si efectul
se va situa sub medie sau peste medie, in functie de deplasarea factorilor
de la niveluri mici spre niveluri mari. Asadar, deosebim abateri (
) in masura in care se abat la randul lor de la medie,
actionand mai intens sau mai putin intens. Ca urmare, si efectul
se va situa sub medie sau peste medie, in functie de deplasarea factorilor
de la niveluri mici spre niveluri mari. Asadar, deosebim abateri (![]() ) datorate factorilor determinanti inclusi in
model. Notam suma patratelor abaterilor de acest gen cu SSR. Singurul motiv pentru care
adoptam aceasta notatie este o mai clara expunere a
etapelor verificarii.
) datorate factorilor determinanti inclusi in
model. Notam suma patratelor abaterilor de acest gen cu SSR. Singurul motiv pentru care
adoptam aceasta notatie este o mai clara expunere a
etapelor verificarii.
![]()
Un
alt gen de abateri care pot interveni s-ar datora perturbatiei, astfel
spus actiunii factorilor reziduali exprimati prin simbolul "u". Suma
patratelor unor astfel de abateri datorate intamplarii o notam
cu SSU si ea reprezinta
suma patratelor diferentelor dintre valorile ajustate, generate de
model si valorile empirice (![]() ), reprezentate de deatele numerice (y).
), reprezentate de deatele numerice (y).
![]()
Ne
asteptam ca rolul factorilor sistematici (![]() ) sa fie net superior rolului factorilor minori,
perturbatori (u), aspect care poate fi verificat raportand suma care ne
asteptam sa fie mai mare (SSR) la suma reziduurilor ridicate la
patrat (SSU). Aceasta din urma suma ne asteptam
sa fie de cateva ori mai mica decat SSR daca modelul
elaborat este performant. Afirmatia "de cateva ori mai mica" este
vaga si, ca urmare, este
necesara o baza obiectiva care se confere rigurozitate
demersului. Acesta este motivul pentru care apelam la repartiia raportului
dispersiilor (repartitia Snedecor), ceea ce implica transformarea
sumelor (SSR, SSU) an dispersii, precum acceptarea unei
probabilitati (
) sa fie net superior rolului factorilor minori,
perturbatori (u), aspect care poate fi verificat raportand suma care ne
asteptam sa fie mai mare (SSR) la suma reziduurilor ridicate la
patrat (SSU). Aceasta din urma suma ne asteptam
sa fie de cateva ori mai mica decat SSR daca modelul
elaborat este performant. Afirmatia "de cateva ori mai mica" este
vaga si, ca urmare, este
necesara o baza obiectiva care se confere rigurozitate
demersului. Acesta este motivul pentru care apelam la repartiia raportului
dispersiilor (repartitia Snedecor), ceea ce implica transformarea
sumelor (SSR, SSU) an dispersii, precum acceptarea unei
probabilitati (![]() ) legate de riscul de a gresi in ce priveste
concluzia care incheie verificarea. Obtinem dispersii divizand suma
patratelor abaterilor la numarul gradelor de libertate. Raportul
dispersiilor la care ajungem este notat
) legate de riscul de a gresi in ce priveste
concluzia care incheie verificarea. Obtinem dispersii divizand suma
patratelor abaterilor la numarul gradelor de libertate. Raportul
dispersiilor la care ajungem este notat ![]() .
.
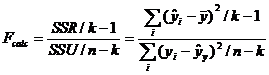 , unde k= numarul de partametrii (7)
, unde k= numarul de partametrii (7)
Etapele aplicarii testului F, pe baza aplicatiei pentru care am estimat parametrii, sunt:
- stabilim ipoteza nula, a nesemnificatiei: dispersia de la numaratorul relatiei (7) nu se abatre semnificativ de la dispersia pozitionata la numitor.
-
determinam nivelul F-calculat (7). desigur, obtinerea marimii F
implica pentru numarator: obtinerea valorilor ajustate ![]() , calculul abaterilor acestor valori de la medie (
, calculul abaterilor acestor valori de la medie (![]() ), ridicarea la patrat a fiecarei diferente,
insumarea patratelor diferentelor si raportarea sumei la
numarul de parametrii (mai putin unu) din model; in ce priveste
numitorul, este suficient sa determinam diferentele dintre
valorile ajustate
), ridicarea la patrat a fiecarei diferente,
insumarea patratelor diferentelor si raportarea sumei la
numarul de parametrii (mai putin unu) din model; in ce priveste
numitorul, este suficient sa determinam diferentele dintre
valorile ajustate ![]() si valorile reale (y), sa le ridicam pe fiecare
la patrat si sa insumam patratele, dupa care
divizam suma la numarul de cazuri minus numarul de parametri:
si valorile reale (y), sa le ridicam pe fiecare
la patrat si sa insumam patratele, dupa care
divizam suma la numarul de cazuri minus numarul de parametri:
Pentru aplicatia la care facem referire obtinem:
SSR (k-1)=[(10,284-16)![]() +(10,763-16)
+(10,763-16)![]() ++(20,758-16)
++(20,758-16)![]() ]:(3-1)=131,778:2=65,889
]:(3-1)=131,778:2=65,889
SSU/(n-k)=[(10,284-10)![]() +(10,763-11)
+(10,763-11)![]() ++(20,758-21)
++(20,758-21)![]() ]:(15-3)=6,222:12=0,5185
]:(15-3)=6,222:12=0,5185
F![]() =65,889/0,5185=127,077
=65,889/0,5185=127,077
-
preluam din tabelul repartitiei raportului dispersiilor nivelul
tabelat (F![]() ) corespunzator
) corespunzator ![]() si (k-1), respectiv (n-k) grade de libertate
si (k-1), respectiv (n-k) grade de libertate
Daca acceptam ![]() =0,05 si avem in vedere 3-1=2 garde de libertate, respectiv
15-3=12 grade de libertate gasim F
=0,05 si avem in vedere 3-1=2 garde de libertate, respectiv
15-3=12 grade de libertate gasim F![]() =6,93.
=6,93.
-
comparam nivelul![]() cu nivelul
cu nivelul![]() si in cazul in care valoarea calculata este mai
mare, infirmam ipoteza nula, a nesemnificatiei, ceea ce confirma
modelul ca fiind valid, in sensul ca, in general, estimatiile privind
parametrii sunt semnificative; daca dimpotriva,
si in cazul in care valoarea calculata este mai
mare, infirmam ipoteza nula, a nesemnificatiei, ceea ce confirma
modelul ca fiind valid, in sensul ca, in general, estimatiile privind
parametrii sunt semnificative; daca dimpotriva, ![]() <
<![]() ipoteza nula este confirmata cu tot ceea ce
implica ea.
ipoteza nula este confirmata cu tot ceea ce
implica ea.
Unele mentiuni:
- valorile tabelate sunt supraunitare, ceea ce implica ca in toate cazurile de aplicare a testului F sa raportam dispersia de marime maxima la dispersia minima;
- testul implica sume de abateri (SSR, SSU care impreuna formeaza SST), ceea ce ofera prilejul de a extinde verificarea in directtia determinarii si interpretarii coeficientului de determinatie a carui relatie de definire este urmatoarea:
![]() (8)
(8)
Un astfel de coeficient exprima ponderea rolului factorilor determinanti din model in raport cu variatia totala a variabilei-efect s-ar datora factorilor determinanti inclusi in analiza.
Coeficientul de determinatie se poate obtine si pe baza relatiei echivalente:
![]() (9)
(9)
Daca
avem in vedere relatia privind ![]() (7) si daca impartim si
numaratorul si numitorul la SST, rezulta:
(7) si daca impartim si
numaratorul si numitorul la SST, rezulta:
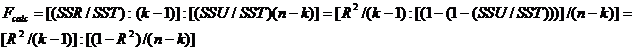 (10)
(10)
Acest din urma raport face posibila aplicarea testului F in situatia in care cunoastem coeficientul de determinatiei.
Mentionam,
de asemenea, ca indeosebi pentru comparatii, se recomanda
varianta ajustata a coeficinetului de determinatie (![]() ):
):
![]() (11)
(11)
In exemplul considerat:
![]() adica
adica ![]() din variatia efectului
este determinata de cei doi factori.
din variatia efectului
este determinata de cei doi factori.
In varianta ajustata ![]() .
.
![]()
Copyright © 2025 - Toate drepturile rezervate
| Statistica | |||
|
|||
|
| |||
|
| |||
|
|
|||