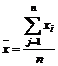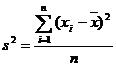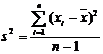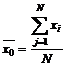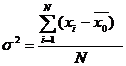|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
Continut:
1. Generalitati
2. Notiuni si importanta
Procedee si modalitati de alcatuire a esantioanelor
4. Estimarea mediei si dispersiei populatiei folosind sondajul statistic
Precizia estimatiei, probabilitatea de incredere, intervalul de incredere
Rezumat: Unul dintre capitolele esentiale ale statisticii, menit sa usureze consistent munca cercetatorului, este sondajul. In cadrul lui, o buna cunoastere si intelegere presupune stapanirea riguroasa a notiunilor teoretice, alaturi de intelegerea conceptelor de reprezentativitate si estimatie. In vederea efectuarii in bune conditii a unui sondaj este importanta alegerea procedurii corecte de alcatuire a esantionului si dimensionarea corecta a acestuia. In vederea calculului si estimarii cat mai aproape de adevar a mediei si dispersiei colectivitatii generale este pus la dispozitie aparatul statistico-matematic adecvat.
1. Generalitati
Necesarul de informatie in continua crestere, coroborat cu faptul ca sursele economice (in principal cele financiare) sunt de regula limitate, determina cresterea gradului de utilizare a metodei sondajului statistic ca forma a observarii partiale.
Sondajul statistic este uneori singura forma de obtinere a informatiei si este cu atat mai avantajoasa cu cat presupune un consum redus de resurse, oferind posibilitatea de a obtine informatii referitoare la intreaga colectivitate, prin observarea si cercetarea unei parti a acesteia.
Partea cercetata este numita subpopulatie sau esantion, fiind intalnita in literatura de specialitate sub numele de sondaj sau selectie.
In practica cel mai des se foloseste sintagma 'colectivitate de selectie' pentru esantion.
Toate ipotezele, afirmatiile, clasele stabilite pe baza unui sondaj nu pot fi considerate de tip determinist, ele avand caracterul unor ipoteze, afirmatii de tip statistic, efectuate in conditiile unei anumite probabilitati, deci cu un anumit nivel de incredere.
2. Notiuni Si importanTa
Culegerea datelor se face prin observatii totale si partiale. Daca observatia partiala se face in scopul inlocuirii unei observari totale, atunci statistica foloseste metoda selectiva, care presupune obtinerea unor esantioane reprezentative, extrase dupa criterii strict elaborate, si care se supun observarii in conformitate cu o serie de reguli prestabilite.
Reprezentativitatea este proprietatea conform careia, intr-un numar mai mic de unitati, care formeaza impreuna un esantion, se regasesc aceleasi trasaturi esentiale ca si in intreaga populatie supusa cercetarii statistice.
Se considera suficient de reprezentativ, sondajul care conduce la erori de cel mult 5 % intre colectivitatea de selectie si colectivitatea generala.
La aplicarea metodei sondajului statistic, se utilizeaza o serie de notiuni-perechi ale colectivitatii de selectie si colectivitatii generale dupa cum urmeaza:
|
Colectivitatea |
Volum |
Caracteristica nealternativa |
Caracteristica alternativa |
Medie |
Dispersie |
Medie |
Dispersie |
|
|||||||||||||||||||||||
|
Colectivitatea de selectie |
n |
|
|
|
|
|||||||||||||||||||||||||
|
Colectivitatea generala |
N |
|
|
|
|
|||||||||||||||||||||||||
De retinut ca, in orice conditii volumul colectivitatii totale este o constanta, deci parametrii colectivitatii totale (media, dispersia) pot lua fiecare cate o singura valoare distincta. In acelasi timp, dintr-o populatie totala de N unitati pot fi extrase mai multe esantioane de acelasi volum sau de volum diferit. Rezulta de aici ca media si dispersia colectivitatii de sondaj se transforma in variabile aleatoare, cu valori si frecvente diferite de aparitie.
Dintr-un volum de N unitati pot fii extrase ![]() esantioane.
Numarul total al esantioanelor este
esantioane.
Numarul total al esantioanelor este ![]() .
.
De aici rezulta ca media si dispersia colectivitatii de sondaj se transforma in variabile aleatoare cu valori diferite si cu frecvente diferite.
Pentru fiecare indicator calculat la nivel de colectivitate generala sau esantion, exista diferente in plus sau in minus. Aceste diferente se numesc erori de selectie si sunt: de sondaj sau de reprezentativitate.
Erorile de sondaj sunt erori de care isi au sursa in incalcarea principiului fundamental al sondajului si anume caracterul aleator al prelucrarilor. Ele se concretizeaza in deplasari ale valorilor parametrilor stabiliti pentru colectivitatea de selectie, comparativ cu parametrii existenti pentru populatia originara.
Datorita proprietatilor mediei, la calculul erorii de sondaj se ia in discutie ca principal masurator al erorii, diferenta dintre media de selectie si media generala.
Eroarea de reprezentativitate reprezinta diferenta dintre media generala a populatiei si media esantionului, aceasta din urma fiind calculata pe baza sondajului.
Aceasta eroare este expresia in
unitati concrete de masura, considerandu-se ca
media ![]() a
colectivitatii de selectie este reprezentativa pentru media
generala (m) a colectivitatii generale, daca este
reflectata relatia:
a
colectivitatii de selectie este reprezentativa pentru media
generala (m) a colectivitatii generale, daca este
reflectata relatia:
![]() sau
sau ![]()
Diferenta ![]() se numeste eroare de esantionare sau eroare de reprezentativitate si este de 2 tipuri:
se numeste eroare de esantionare sau eroare de reprezentativitate si este de 2 tipuri:
b1) eroare de reprezentativitate sistematica, provenind de la nerespectarea principiilor fundamentale ale efectuarii sondajului: "alegerea la intamplare a unitatilor esantionului".
b2) eroare de reprezentativitate intamplatoare, care nu poate fi evitata si care tine de natura esantionarii ca cercetare partiala.
Practica demonstreaza ca indiferent de precautiile luate, nu este posibila reproducerea pana la identitate a structurii populatiei totale si de aici rezulta ca eroarea de reprezentativitate poate fi calculata daca media generala este cunoscuta dintr-o cercetare anterioara, comparandu-se media esantionului inregistrat, calculata in cursul cercetarii, cu aceasta medie generala recunoscuta.
In acest caz se spune ca a fost calculata eroarea efectiva de sondaj si daca ea se incadreaza in marja de 5% este verificat si gradul de reprezentativitate.
Nu in toate cazurile exista o medie precalculata a colectivitatii generale. Din acest motiv se utilizeaza mai multe sondaje de proba, verificandu-se stabilitatea mediei si a dispersiei acestor sondaje prin metode cunoscute de la seriile de distributie.
Avantajul selectiei statistice consta in faptul ca permite calcularea marimii erorii si stabilirea prealabila a marimii acesteia, cu conditia ca la formarea esantionului sa se foloseasca o schema probabilistica sau un procedeu derivat dintr-o schema probabilista.
In acest caz, se pot interpreta si calcula erorile de selectie, cu ajutorul proprietatilor diferitelor functii de probabilitate.
3. Procedee si modalitati de alcatuire a esantioanelor
Metoda sondajului ofera tehnici variate de prelucrare, diferentiate si adaptate diferitelor tipuri de populatie, astfel incat sa se asigure caracterul aleator al selectiei unitatilor si reprezentativitatea esantionului.
Dupa modul de prelucrare sau extragere, exista urmatoarele tipuri de sondaje:
a) sondaj simplu aleator
- repetat
- nerepetat
b) sondaj tipic (stratificat):
c) sondaj de serie
d) sondaj in mai multe trepte
e) sondaj secvential utilizat la controlul calitatii
f) sondaj subiectiv (organizat sau dirijat)
g) sondaj sistematic sau mecanic
In practica, in marea majoritate a cazurilor, esantioanele se extrag din populatii finite. Aceste esantioane se trateaza prin analogie cu extragerea sondajelor din populatii infinite.
In functie de revenirea sau nerevenirea fiecarei unitati in baza de extragere, sondajele sunt repetate, daca unitatea extrasa revine in baza in vederea unei noi extrageri, si nerepetate in caz contrar.
Sondajul repetat este sondajul in care fiecare unitate extrasa din populatia generala este introdusa din nou in aceasta, in vederea unei noi extrageri. In acest caz, variabilele sunt independente intre ele si fiecare unitate poate fi extrasa de mai multe ori.
In sondajul simplu repetat varianta de sondaj da nastere unei repartitii teoretice dupa modelul Bernoulli.
Dintr-o colectivitate care contine N
unitati se pot extrage mai multe esantioane de volum n, care pot
sa fie diferite ca structura una de cealalta ,deci succesiunea
probelor de sondaj este infinita. Numarul de variante de esantionare este
totusi finit si este egal cu: ![]() .
.
Prin sondaj nerepetat se intelege un sondaj analog cu modelul bilei extrase din urna, fara ca ea sa mai fie pusa inapoi.
In acest caz, variantele sunt dependente intre ele, si fiecare unitate poate aparea o singura data in sirul succesiv al probelor. Este practic un sondaj efectuat dintr-o populatie finita , cu fractia de sondaj depinzand de volumul esantionului.
Atat in cazul bilei revenite, cat si in cel al bilei nerevenite se obtin mai multe esantioane de acelasi volum. Efectuand toate esantioanele posibile cu acelasi volum, mediile de selectie pot fi considerate ca valori diferite ale unei variabile statistice aleatoare, care pot estima media generala cu o abatere mai mare sau mai mica. Rezulta de aici ca exista sondaje mai eficiente sau mai putin eficiente.
Prin
definitie, un sondaj A de volum n,
in baza caruia se estimeaza media m
a unei populatii pentru variabila x
prin estimatia ![]() este mai eficace decat
sondajul B, de acelasi volum n,
in baza caruia se estimeaza aceeasi medie m a caracteristici x,
daca exista relatiile:
este mai eficace decat
sondajul B, de acelasi volum n,
in baza caruia se estimeaza aceeasi medie m a caracteristici x,
daca exista relatiile:
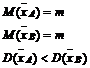
Acest lucru se explica pe baza
inegalitatii lui Cebisev, care exprima cu o probabilitate
mai mare decat ![]() urmatoarele:
urmatoarele:
- in cazul sondajului A media teoretica
m se gaseste cuprinsa in intervalul ![]() ;
;
- in cazul sondajului B ![]() ..
..
Concluzie:
Cu aceeasi probabilitate, se gaseste pentru media teoretica un interval mai mic de acoperire in cazul sondajului A decat in cazul sondajului B, motiv pentru care spunem ca sondajul A este mai eficient si il preferam sondajului B.
Intreaga metodologie de calcul si interpretare statistica a rezultatelor unei cercetari selective, se bazeaza pe sondajul simplu, aleator, care corespunde cel mai bine schemei Bernoulli si are ca model teoretic repartitiile binomiala si hipergeometrica.
Alcatuirea esantioanelor poate fi facuta prin mai multe procedee:
a) procedeul bilei revenite si nerevenite procedeu in care elementele populatiei generale se noteaza de la 1 la N, si fiecare nr. se noteaza pe un cartonas. Toate cartonasele se introduc intr-o anumita urna (urna lui Bernoulli) si se amesteca bine. Extragerile se fac la intamplare.
Elementul extras se considera component al esantionului. Daca elementele nu se mai introduc in urna lui Bernoulli, sondajul aleator este nerepetat. In caz contrar, sondajul este repetat.
La sondajul repetat, dupa fiecare reintroducere, cartonasele din urna lui Bernoulli sunt din nou amestecate.
b) procedeul tabelului numerelor aleatoare reprezinta o varianta de selectie probabilista, care porneste de la conceptul de nr. aleator si care are sens prin asociere cu anumite experimente si anumite consemnari, privind frecventa de aparitie a unui fenomen sau a unei anumite caracteristici intr-un proces.
Utilizarea tabelelor cu numere aleatoare consta in preluarea din cadrul populatiei a unitatilor ale caror numere de ordine prestabilite printr-o numaratoare prealabila au fost citite dupa o anumita ordine din tabel. Citirea se face de sus in jos si de la stanga la dreapta.
Exista algoritmi care genereaza numere aleatoare. Pentru ca selectia sa fie riguros intamplatoare, punctul de pornire in acest tabel se alege tot intamplator.
Daca nu exista corespondenti intre numarul citit din tabel si numarul elementului, se trece mai departe la alt numar aleator.
c) procedeul mecanic de formare a esantionului solicita ca elementele colectivitatii generale supuse cercetarii sa fie prelevate dupa un interval determinat, denumit frecvent ' pas de numarare', care se aplica bazei de sondaj.
Spre exemplu, daca volumul esantionului ar fi de 1/10 din cel al colectivitatii generale, preluarea elementelor in esantion se face din 10 in 10, pornindu-se dintr-un punct al colectivitatii ales intamplator.
4. Estimarea mediei si dispersiei populatiei generale folosind sondajul statistic
4.1. Sondajul aleator simplu repetat
Analiza formulelor de estimare pentru medie si dispersie duce la concluzia ca sondajul aleator simplu repetat este cel mai apropiat ca estimare pentru medie si dispersie, fiind de asemenea cel mai acoperitor din punctul de vedere al bazei teoretice si pentru celelalte procedee. In acest caz media de selectie este o variabila care urmeaza o anumita lege de probabilitate. Se demonstreaza ca functia de probabilitate depinde de volumul esantionului. Acest principiu sta la baza calculului erorii probabile de reprezentativitate.
Prin estimatie se intelege operatia de extindere, in limitele specificate de incertitudinea exprimata in termeni probabilistici, a rezultatelor obtinute in sondaj asupra intregii populatii.
Estimatiile reprezinta evaluari aproximative ale adevaratelor valori ale parametrilor estimati, deoarece sunt afectate de erori.
Eroarea estimatiei afecteaza precizia ei. Rezulta de aici ca estimarea parametrului general se face printr-un interval de estimare numit si interval de incredere.
Acest interval va avea 2 limite: limita inferioara ![]() , limita superioara
, limita superioara
![]() .
.
Pentru parametrul real este indeplinita urmatoarea relatie de probabilitate:
![]()
In acest caz,1-a este nivelul de incredere, iar a se mai numeste prag de semnificatie.
Jumatatea intervalului de incredere
se numeste eroare limita admisa si se noteaza cu:
![]()
Folosind independenta valorilor
variabilelor din esantion, notate cu x1,x2.xn,
se arata ca media de sondaj
va fii : ![]()
![]()
poate fi un estimator nedeplasat al mediei m a colectivitatii generale daca se indeplineste conditia ca media mediilor de selectie sa fie egala cu media generala, adica:
![]() = m
= m
Dispersia mediei de sondaj:
![]()
Abaterea
medie patratica a mediei de sondaj 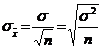
4.2. Sondajul aleator simplu nerepetat
In caracterizarea si calculul parametrilor acestui tip de sondaj se considera ca X este o caracteristica de tip cantitativ. Problema principala a sondajului este estimarea mediei m a colectivitatii generale pe baza mediei x a colectivitatii de selectie, precum si a unor parametrii rezultati in urma aplicarii metodei selectiei statistice.
Este evident ca numai din punct de vedere pur teoretic sau absolut intamplator este posibil ca m sa fie egal cu x. In general, media colectivitatii de selectie sau a esantionului se apropie mai mult sau mai putin de media colectivitatii generale, deci va apartine unei varietati a acesteia. Cu cat aceasta varietate este mai restransa, cu atat estimarea este mai constanta iar selectia mai reusita.
Daca N este volumul
colectivitatii generale atunci probabilitatea producerii fenomenului
xi = 1/N, iar X2 = x2 in conditiile in care deja X1 = x1 = 1/N ![]()
Cu alte cuvinte, daca in momentul initial probabilitatea extragerii unui anumit element din cadrul esantionului este egala cu 1/volumul colectivitatii, dupa ce aceasta extragere s-a produs probabilitatea extragerii unui alt element creste deoarece volumul colectivitatii s-a diminuat cu o unitate si numitorul fiind mai mic, expresia e mai mare. Acest lucru e valabil pentru sondajul aleator simplu nerepetat.
Media de selectie va fii o variabila aleatoare a carei dispersie este data de relatia:
![]()
unde: ![]() este dispersia colectivitatii generale.
este dispersia colectivitatii generale.
De asemenea abaterea medie patratica a mediei de
selectie 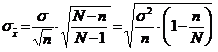
Daca raportul dintre colectivitatea
de selectie si cea generala (n/N) < 0,2, adesea in calcule
factorul ![]() nu se mai ia in
consideratie.
nu se mai ia in
consideratie.
De aici rezulta un paradox care arata ca erorile sondajelor care cuprind o parte neinsemnata din colectivitatea generala depind numai de numarul absolut al variatiilor colectivitatii de selectie si de marimea abaterii medii patratice a colectivitatii generale.
De altfel, precizia estimatiei mediei m a colectivitatii generale prin media x a colectivitatii de selectie depinde foarte putin de volumul N al colectivitatii generale; aceasta precizie depinde mult mai mult de valoarea absoluta a volumului n a esantionului.
Cand volumul esantionului (n) creste, precizia creste de
aproximativ ![]() ori, dupa cum in
aproximativ acelasi raport se micsoreaza abaterea mediei
patratica a mediei de selectie. Aceasta
dependenta a abaterii medie patraticea mediei de selectie
de volumul colectivitatii de selectie da posibilitatea
utilizarii in practica a unor sondaje nu foarte mari ca volum,
deoarece cresterea cu putin a volumului colectivitatii de
selectie nu influenteaza cu aproape nimic precizia.
ori, dupa cum in
aproximativ acelasi raport se micsoreaza abaterea mediei
patratica a mediei de selectie. Aceasta
dependenta a abaterii medie patraticea mediei de selectie
de volumul colectivitatii de selectie da posibilitatea
utilizarii in practica a unor sondaje nu foarte mari ca volum,
deoarece cresterea cu putin a volumului colectivitatii de
selectie nu influenteaza cu aproape nimic precizia.
Concluzie:
daca volumul N al colectivitatii generale este foarte mare,
si volumul n al colectivitatii de selectie este foarte mic,
atunci expresia:![]()
De aici rezulta ca in astfel de situatii in care n este foarte mic, rezultatele sondajului repetat si a celui nerepetat difera foarte putin.
De retinut si faptul ca in
totdeauna ![]() , motiv pentru care eroarea sondajului nerepetat va fii
totdeauna mai mica decat eroarea sondajului repetat sau cu revenire.
, motiv pentru care eroarea sondajului nerepetat va fii
totdeauna mai mica decat eroarea sondajului repetat sau cu revenire.
Acest lucru se explica prin faptul ca revenirea acelorasi unitati in sondaj inrautateste reprezentativitatea, aparitia repetata in urna lui Bernoulii a aceleiasi unitati ducand la o pierdere substantiala de informatii.
Adaugand acestor avantaje si faptul ca extractia nerepetata se realizeaza mai usor din punct de vedere organizatoric rezulta evantaiul complet al argumentelor care determina ca in practica sondajul nerepetat sa fie mai utilizat decat cel repetat.
In ultima instanta se
remarca faptul ca precizia sondajului, eroarea medie a acestei
precizii depinde nu de proportia de sondaj n/N, ci de volumul n al
sondajului, ![]() fiind o constanta.
fiind o constanta.
4.3. Estimarea dispersiei
Intreaga procedura utilizata
pentru estimarea mediei m presupunea ca dispersia![]() a colectivitatii generale era aprioric
cunoscuta.
a colectivitatii generale era aprioric
cunoscuta.
Daca nu este cunoscuta
aceasta dispersie, in locul ei se utilizeaza estimatorul numit
dispersia de sondaj: 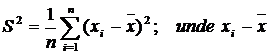 reprezinta abaterile individuale ale valorilor
colectivitatii de sondaj xi fata de media lor
reprezinta abaterile individuale ale valorilor
colectivitatii de sondaj xi fata de media lor ![]() .
.
Pentru un sondaj repetat, dispersia ![]() este un estimator deplasat al dispersiei
este un estimator deplasat al dispersiei ![]() a colectivitatii generale.
a colectivitatii generale.
Aplicand regulile de calcul ale dispersiei si introducand m al colectivitatii generale de obtine:
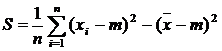 ceea ce arata
ca S2 este un estimator deplasat, utilizarea lui comportand
anumite riscuri referitoare la eroarea de reprezentativitate.
ceea ce arata
ca S2 este un estimator deplasat, utilizarea lui comportand
anumite riscuri referitoare la eroarea de reprezentativitate.
Un estimator nedeplasat, mai exact se
obtine in cazul sondajelor de volum redus cu formula: 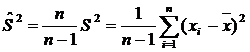
Daca volumul colectivitatii de selectie este mic, sub o zecime, sau chiar mai mic, atunci acest estimator pentru dispersia colectivitatii generale este mult mai realist, mai aproape de valoarea reala a acesteia.
Concluzie: In cazul sondajului nerepetat,
dispersia medie de sondaj ![]() poate fii estimata din urmatoarele marimi:
poate fii estimata din urmatoarele marimi: 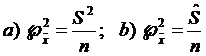 , iar abaterea media patratica este:
, iar abaterea media patratica este: 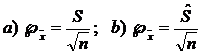
5. Precizia estimatiei, probabilitatea de incredere,
intervalul de incredere.
5.1 Estimarea mediei
Daca ![]() este estimatorul
mediei m a unei populatii, calculat pe baza unui esantion
este estimatorul
mediei m a unei populatii, calculat pe baza unui esantion
de volum n,
probabilitatea de incredere (1 - α) reprezinta siguranta cu care
se afirma ca intervalul de incredere (![]() ;
; ![]() ) cuprinde valoarea teoretica estimata
) cuprinde valoarea teoretica estimata
P (![]() < m <
< m < ![]() ) = 1 - α
) = 1 - α
Considerand o variabila de sondaj z definita dupa variabila normala normata de forma:
zα = ![]()
Intervalul de incredere pentru medie va fi:
![]() < m <
< m < ![]()
unde: zα - este valoarea tabelara care satisface ecuatia Φz = 1 - α;
Φ - functia lui Laplace tabelara;
![]() - abaterea medie patratica a mediei de sondaj sau
eroarea standard.
- abaterea medie patratica a mediei de sondaj sau
eroarea standard.
5.2. Determinarea volumului n al esantionului
In cazul sondajului repetat:
![]() ,
,
de unde in final rezulta:
n = ![]()
in care zα se citeste din tabelele functiei Laplace.
In cazul sondajului nerepetat:
![]() ,
,
de unde in final rezulta:
n = 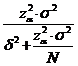
5.3 Estimarea preciziei in cazul caracteristicii binare (alternative)
Daca sondajul , k unitati cercetate poseda caracteristica X si n - k nu o poseda si in plus x1 = x2 = . = xk = 1 si xk+1 = xk+2 = . = xn = 0, proportia in esantion a elementelor care poseda caracteristica X este media
![]()
care este tocmai frecventa relativa a caracteristicii cercetate in esantion, notata cu f.
Se observa ca frecventa relativa f a
caracteristicii x in esantion este un estimator nedeplasat al
probabilitatii p deoarece din relatia generala ![]() = m rezulta
imediat in baza celor precedente ca
= m rezulta
imediat in baza celor precedente ca ![]() .
.
Dispersia σ2 a caracteristicii alternative x in colectivitatea generala se calculeaza dupa formula:
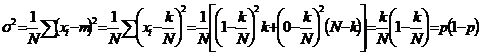 Tinand
seama de relatiile anterioare se obtine precizia cu care se
estimeaza probabilitatea p prin frecventa relativa f, pentru
sondajul repetat si nerepetat:
Tinand
seama de relatiile anterioare se obtine precizia cu care se
estimeaza probabilitatea p prin frecventa relativa f, pentru
sondajul repetat si nerepetat:
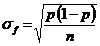
respectiv:
![]()
Intervalul de incredere pentru probabilitatea p in cazul sondajului repetat este:
f - ![]() < p < f +
< p < f + ![]()
Intervalul de incredere pentru probabilitatea p in cazul sondajului nerepetat este:
f - ![]() < p < f +
< p < f + ![]()
Volumele celor doua tipuri de sondaje sunt date de relatiile:
n = ![]()
unde p
se inlocuieste cu o estimatie p calculata cu ajutorul
frecventei relative f = ![]() de volum n.
de volum n.
In cazul sondajului nerepetat, volumul n se obtine din relatia:
![]() ,
,
de unde in final:
n = 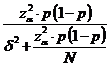
Sondajul tipic (stratificat)
In cazul sondajului stratificat trebuie sa se asigure reprezentativitatea fiecarei grupe in esantion. In acest caz esantionul se divide in subesantioane.
Se considera populatia generala impartita in k subpopulatii partiale c1, c2, . ,ck numite grupe (straturi), carora le corespund urmatoarele valori ale caracteristicii: c1: x11, x21, . , xN11
c2: x12, x22, . , xN22
ck: x1k, x2k, . , xNkk
Stratul c1 are N1 unitati, c2 are N2 etc., numarul total al unitatilor populatiei c fiind:
N1 + N2 + . + Nk = N
Din fiecare strat se fac cate n1, n2, . , nk extrageri la intamplare nerepetate, astfel incat:
n1 + n2 + . + nk = n
Din fiecare strat se efectueaza cate un sondaj, obtinand k esantioane ale caror unitati au caracteristici cu valorile:
x11, x21, . , xN11
x12, x22, . , xN22
x1k, x2k, . , xNkk
Se introduc notatiile:
m = ![]() - media generala
- media generala
mj = ![]() - media stratului j.
- media stratului j.
Rezulta ca media generala mai poate fi scrisa:
m = ![]()
In cadrul sondajelor, daca notam
![]() =
= ![]()
![]() =
= ![]()
rezulta : ![]() =
= ![]()
Pentru estimarea mediei generale m se considera:
![]() =
= ![]()
care reprezinta o medie ponderata a rezultatelor ![]() obtinute in fiecare grupa.
obtinute in fiecare grupa.
Se
arata ca ![]() este un estimator
nedeplasat si consistent al mediei m deoarece se demonstreaza
ca:
este un estimator
nedeplasat si consistent al mediei m deoarece se demonstreaza
ca:
![]()
si:
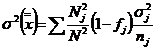
unde:
![]()
Daca se foloseste dispersia din populatia de baza, eroarea limita va fi:
pentru sondajul repetat:
![]()
de unde:
n = ![]()
pentru sondajul nerepetat:
![]()
de unde:
n = 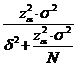
Sondajul tipic proportional
Se caracterizeaza prin faptul ca din fiecare grupa tipica in care a fost impartita populatia generala se extrag atatea unitati astfel incat raportul dintre numarul lor si volumul grupei din care s-au extras sa fie egal cu raportul dintre volumul general al esantionului si volumul populatiei generale, adica:
![]()
Din relatia de mai sus se deduce:
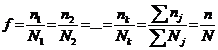
de unde:
![]()
Sondajul tipic optim
Daca volumul sondajului de grupa nj este astfel dimensionat incat eficienta sa fie maxima, atunci sondajul tipic este optim. Acest fapt duce la determinarea numerelor nj care sa satisfaca conditia:
n1 + n2 + . + nk = n
si pentru care:
sa fie minima. Folosind metoda multiplicatorilor lui Lagrange se obtine:
![]()
Aplicatia 1
In scopul analizei capacitatii de cazare turistica dintr-o zona montana o firma interesata efectueaza un sondaj simplu aleatoriu de volum 10% din colectivitatea generala, obtinand urmatoarele date sistematizate:
|
Intervale de variatie a capacitatii de cazare/locuri/unitate |
Numar unitati turistice |
|
Total |
a) Sa se determine capacitatea medie de cazare in esantion si sa se precizeze daca valoarea medie obtinuta este o valoare reprezentativa pentru colectivitatea de selectie analizata;
b) Sa se calculeze eroarea medie probabila de selectie si eroarea limita admisa daca rezultatele se garanteaza cu o probabilitate de 95% pentru care z = 1,96;
c) Sa se estimeze limitele intre care se va situa capacitatea medie de cazare pe unitate turistica in colectivitatea generala si limitele intre care se va situa capacitatea totala de cazare;
d) Sa se determine noul volum de selectie care va fi necesar, daca firma ce efectueaza analiza, doreste ca eroarea limita sa se reduca la jumatate, iar probabilitatea cu care se garanteaza rezultatele sa fie 95,45% (z = 2);
e) Sa se estimeze intre ce limite se va incadra ponderea unitatilor turistice cu capacitatea de cazare de 80 si peste 80 de locuri si limitele intre care se va situa numarul acestor unitati daca rezultatele se garanteaza cu o probabilitate de 99,73% (z = 3).
a)
|
Intervale de variatie a capacitatii de cazare/locuri/unitate |
Numar
unitati turistice ( |
|
|
|
|
|
||||
|
|
|
|||
|
|
||||
|
|
||||
|
|
||||
|
Total |
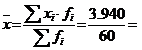 65,67 locuri/unitate
65,67 locuri/unitate
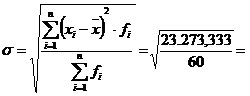 19,69
19,69
![]()
Valoarea medie obtinuta este o valoare reprezentativa pentru colectivitatea de selectie analizata deoarece coeficientul de variatie V= 29,98 % este mia mic de 35 %.
b)
Selectia aleatoare simpla cu revenire
Eroarea medie de selectie:
![]()
Eroarea limita admisa:
![]()
c) Intervalul de incredere pentru:
capacitatea medie de cazare
![]() <
< ![]() <
< ![]()
65,67 - 4,98 < ![]() < 65,67 + 4,98
< 65,67 + 4,98
60,69 locuri/unitate turistica < ![]() < 70,65
locuri/unitate turistica
< 70,65
locuri/unitate turistica
capacitatea totala de cazare
N(![]() ) < N·
) < N·![]() < N(
< N(![]() )
)
n = 60 = ![]() N = 600
N = 600
600 (65,67 - 4,98) < N·![]() < 600 (65,67 + 4,98)
< 600 (65,67 + 4,98)
36.414 locuri/unitate turistica < ![]() < 42.390
locuri/unitate turistica
< 42.390
locuri/unitate turistica
d) ![]()
![]()
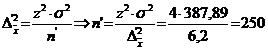 unitati turistice
unitati turistice
e) Calculam greutatea specifica (media):
![]()
m = 7 + 3 = 10 (suma frecventelor ce depasesc frecventa corespunzatoare intervalului ce contine cele 80 de locuri de cazare)
n = 60
Dispersia: w (1- w) = 0,167 (1- 0,167) = 0,139
Eroarea medie de selectie:
![]() (4,8%)
(4,8%)
Eroarea limita admisa:
![]() (14,4%)
(14,4%)
Limitele (intervalul de incredere) intre care se va incadra ponderea unitatilor turistice
100 · (w - Δw) < p < 100 · (w + Δw)
100 · (0,167 - 0,144) < p < 100 · (0,167 + 0,144)
2,3 % < p < 31,1 %
Limitele intre care se va situa numarul unitatilor:
N · (w - Δw) < M < N · (w + Δw)
600 · (0,167 - 0,144) < M< 600 · (0,167 + 0,144)
14 < M< 187 unitati turistice
Selectia aleatoare simpla fara revenire
b) Eroarea medie de selectie:
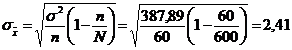
Eroarea limita admisa:
![]()
c. Intervalul de incredere pentru:
capacitatea medie de cazare
![]() <
< ![]() <
< ![]()
65,67 - 4,72 < ![]() < 65,67 + 4,72
< 65,67 + 4,72
60,95 locuri/unitate turistica < ![]() < 70,39
locuri/unitate turistica
< 70,39
locuri/unitate turistica
capacitatea totala de cazare
N(![]() ) < N·
) < N·![]() < N(
< N(![]() )
)
n = 60 = ![]() N = 600
N = 600
600 (65,67 - 4,72) < N·![]() < 600 (65,67 + 4,72)
< 600 (65,67 + 4,72)
36.570 locuri/unitate turistica < ![]() < 42.234
locuri/unitate turistica
< 42.234
locuri/unitate turistica
d) ![]()
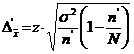
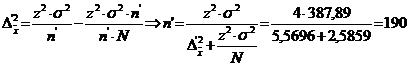 unitati turistice
unitati turistice
e) Calculam greutatea specifica (media):
![]()
m = 7 + 3 = 10 (suma frecventelor ce depasesc frecventa corespunzatoare intervalului ce contine cele 80 de locuri de cazare)
n = 60
Dispersia: w (1- w) = 0,167 (1- 0,167) = 0,139
Eroarea medie de selectie:
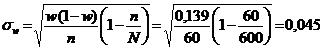 (4,5%)
(4,5%)
Eroarea limita admisa:
![]() (13,5%)
(13,5%)
Limitele (intervalul de incredere) intre care se va incadra ponderea unitatilor turistice
100 · (w - Δw) < p < 100 · (w + Δw)
100 · (0,167 - 0,135) < p < 100 · (0,167 + 0,135)
3,2 % < p < 30,2 %
Limitele intre care se va situa numarul unitatilor:
N · (w - Δw) < M < N · (w + Δw)
600 · (0,167 - 0,135) < M< 600 · (0,167 + 0,135)
19 < M < 181 unitati turistice
Copyright © 2025 - Toate drepturile rezervate
| Statistica | |||
|
|||
|
| |||
|
| |||
|
|
|||