|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
Asa cum am discutat anterior, toate testele statistice incearca sa elimine sansa ca explicatie pentru o legatura aparenta intre doua sau mai multe variabile. Cu asocierea, spectrul sansei are anumite caracteristici. Daca spre exemplu, am cauta sa gasim o legatura intre o variabila dependenta ca succesul tratamentului clientului (succes/esec) si o variabila independenta asemenea tipului de tratament (de grup/individual) pentru urmarirea evaluarii unui program de consiliere in privinta alcoolismului, sansa ar putea juca rolul scepticului. Ipoteza nula spune ca nu exista nici o legatura intre cele doua variabile: daca clientii s-au abtinut de la alcool pentru o perioada de timp (succes) sau nu s-au abtinut (esec) si daca au primit tratamentul de grup sau individual. Ocazional poate aparea ca acei clienti care s-au abtinut au fost in general cei care au primit tratamentul individual sau viceversa. Totusi, in concordanta cu ipoteza nula, aceasta aparenta legatura dintre cele dintre doua variabile poate fi explicata si de variatiile normale ale caracteristicilor intalnite in esantionul mic pe care s-a lucrat (fata de populatia tuturor alcoolicilor). Ar putea fi doar rezultatul erorii de esantionare. Ipoteza nula trebuie sa sustina ca nu exista o legatura reala intre doua variabile dintr-o populatie.
Putem pretinde existenta unei legaturi reale intre doua variabile doar daca putem demonstra ca legatura observata dintre ele este improbabil sa se fi datorat sansei, si deci orice persoana rezonabila va elimina intamplarea (si fireste factorii de deformare si alte variabile) ca explicatie improbabila. Asocierea incearca sa determine daca exista o legatura adevarata intre doua variabile, examinand in ce masura valorile specifice unei variabile sunt asociate cu valorile specifice ale celei de a doua variabile, intr-un grad de probabilitate suficient de mare ca aceasta sa nu fie doar efectul erorii de esantionare. Cand folosim asocierea nu suntem atat de ambitiosi ca sa sugeram ca o variabila poate fi cauza variatiei celeilalte variabile. Putem doar afirma, in cel mai bun caz, ca exista un anumit tip de legatura (patern). Testele de asociere sunt folosite cand dorim sa stim daca aceste legaturi sunt suficient de puternice si consistente pentru a elimina sansa (intamplarea) ca o explicatie a legaturii observate.
Analiza asocierii este una dintre cele mai simple cai pentru a determina daca exista o legatura adevarata intre doua variabile. Exemplul care urmeaza ilustreaza modul in care asocierea este folosita in examinarea eficacitatii relative a tratamentului de grup fata de tratamentul individual la clientii care au fost tratati pentru alcoolism intr-un centru nonguvernamental de tratament. Pentru a face aceasta, un grup de clienti care au primit tratamentul in grup sunt comparati direct cu un grup de clienti care au primit tratamentul individual.
Pentru a intelege procedeul asocierii este util sa incepem cu un tabel care este asemanator Tabelului 1 sau Tabelului 2 . Tabelele au multe nume: tabele de asociere, tabele hi-patrat sau tabele de contingenta. In continuare ne vom referi la ele ca tabele de asociere. In ultima coloana din dreapta Tabelului 1 si Tabelului 2, sunt totalurile (frecventele) pentru fiecare rand introdus. Totalurile pe coloane sunt introduse in linia de jos. Aceste totaluri de pe randuri si coloane sunt denumite totaluri marginale. Ele indica numarul total de cazuri care au fost observate avand o anumita valoare pentru una din variabilele - aceste sunt: tratament in grup, tratament individual, succes sau esec. Totalul general, numarul total de cazuri (N), este introdus in coltul din dreapta-jos. Suma totalurilor de pe ultima coloana si de pe ultimul rand sunt egale, si egale cu numarul total de cazuri.
Tabelul 1 Tipul de tratament dupa succesul clientului
Succes?
Tip de tratament Da Nu Total
Tratament in grup a b a+b
Tratament individual c d c+d
Total a+c b+d N
Asa cum se vede, Tabelul 1 contine doua variabile dihotomice (cu doua categorii), tipul de tratament si succesul clientului. Clientii difera dupa tipul de tratament pe care l-au primit (variabila independenta) si pot varia datorita succesului (variabila dependenta). Este, desigur, posibil a avea variabile cu mai mult de doua categorii. Tabelul de asociere va avea atunci mai multe randuri si coloane si, firesc, mai multe celule. Tabelul 1 identifica diferitele celule in exemplul nostru cu a, b, c si d.
Categoriile variabilelor din tabelul de asociere pot fi puse in orice ordine, deoarece ele sunt de nivel nominal, neexistand o ordonare dupa rang sau alte diferente cantitative. Matematic, este posibil sa folosim analiza tabelelor de asociere cu variabile de nivel ordinar, interval sau raport. Totusi, folosind tabelele de asociere cu variabile de nivel ordinal sau interval, acestea nu vor putea profita de avantajele pe care le ofera precizia de masurare a acestor variabile. Valorile, in aceste cazuri, sunt tratate fara sa se tina cont de diferentele cantitative pe care le reflecta, ca si cum ele ar reprezenta doar diferente calitative.
Tabelele de asociere prezinta de obicei frecventele pentru o variabila independenta si pentru una dependenta. In acest capitol, in toate tabelele, variabila dependenta va fi dispusa pe coloane, iar variabila independenta va fi dispusa pe linii. Aceasta nu reprezinta o lege, de aceea unele studii folosesc asezarea inversa. De fapt, in orice studiu de cercetare, in momentul calculului, indicatorul de asociere este "orb" in ceea ce priveste care dintre variabile este cea independenta si cea dependenta. Asocierea examineaza numai daca exista legaturi intre cele doua variabile. Sunt situatii cand nici una dintre variabile nu este clar dependenta sau independenta. Ele sunt doar doua variabile, a caror legatura dorim sa o studiem. Indicatorul hi-patrat este, de asemenea, potrivit pentru acest tip de situatii.
Tabelul 2 prezinta rezultatele actuale sau observate, rezultate din studiul nostru ipotetic asupra celor doua metode de tratament. Datele din cele patru celule ale Tabelului 2 reprezinta numarul observat de clienti care au realizat fiecare combinatie de valori corespunzatoare pentru cele doua variabile. Putem observa ca au existat in total 100 de clienti (N), dintre care 60 au primit tratamentul in grup (a+b) si 40 au primit tratamentul individual (c+d). Cincizeci si cinci au avut succes, in timp ce 45 au avut insucces. In plus, printre cei 60 care au primit tratamentul in grup, 40 de clienti au avut succes (celula a) si 20 de clienti au avut insucces (celula b). Printre clientii care au primit tratamentul individual, 15 au fost considerati ca avand succes (celula c) si 25 ca avand insucces (celula d).
Tabel 2 Frecvente observate a tipului de tratament dupa succesul clientului
Succes?
Tip de tratament Da Nu Total
Tratament in grup 40 20 60
Tratament individual 15 25 40
Total 55 45 100
In exemplul nostru avem nevoie sa comparam clientii care au primit tratamentul in grup cu aceia care au primit tratamentul individual, in ceea ce priveste rezultatele lor. O astfel de comparatie este relativ greu de observat in Tabelul 2 pentru ca cele doua tipuri de tratament au numere diferite de clienti (60 si 40). Evident ca pe cei 40 de clienti care au avut ca rezultat succesul cu tratamentul in grup (celula a), nu-i putem compara direct cu cei 15 clienti care au avut ca rezultat succesul, dar pe baza tratamentului individual (celula c) si astfel nu putem concluziona ca tratamentul in grup este cea mai buna metoda de tratament doar pentru ca numarul 40 este mai mare decat 15. In ciuda diferentei dintre numarul de cazuri in cele doua grupuri, este posibil sa facem o incercare de comparare intre cele doua tipuri de tratament, prin calcularea procentelor. De exemplu, putem afla ce procentaj reprezinta 40 de clienti din 60 de clienti si ce procentaj reprezinta 15 clienti din 40 de clienti. Tabelul 3 este un tabel de asociere cu procentaje pentru datele observate in Tabelul 2. El arata ca 66,7 procente ale clientilor care au primit tratamentul in grup au avut ca rezultat succesul, comparativ cu 37,5 procente ale acelor clienti care au primit tratamentul individual. Variabilele tipul de tratament primit si succesul clientilor ar putea fi deci legate. Daca procentajele (celula a si celula c) ar fi identice, cele doua variabile, in mod sigur, nu ar fi legate. Pana la acest punct, nu putem insa exclude intamplarea ca explicatie a legaturii aparente dintre variabile.
Desi cele doua variabile par sa fie intrucatva legate, totusi s-ar putea spune ca ele "nu sunt prea mult legate". Argumentul ar consta in faptul ca 29,2 procente diferenta (66,7 procente - 37,5 procente = 29,2 procente) nu este foarte mult si s-ar putea ca faptul de a fi legate este doar un rezultat al erorii de esantionare. Asa sa fie? Multe dintre rationamentele statistice sunt preocupate sa ne ajute sa decidem cat de mare diferenta este necesara pentru a elimina sansa ca explicatie posibila a unei legaturi aparente intre variabile.
Tabel 3 Procente observate a tipului de tratament dupa succesul clientului
(din tabelul 2)
Succes?
Tip de tratament Da Nu Total
Tratament in grup 66.7 33.3 100.0
Tratament individual 37.5 62.5 100.0
Tratament in grup = Celula a: 40 / 60 = 66.7%
Celula b: 20 / 60 = 33.3%
100%
Tratament individual = Celula c: 15 / 40 = 37.5%
= Celula d: 25 / 40 = 62.5%
100%
Cat de mare ar trebui sa fie diferenta intre procente pentru ca sansa sa fie o explicatie improbabila? Putem raspunde la aceasta intrebare prin concentrarea asupra a cat de mult difera frecventele observate fata de acele frecvente pe care noi ne asteptam sa le gasim mai frecvent, daca ipoteza nula ar fi adevarata - acestea sunt frecventele asteptate.
Sa ne intoarcem la Tabelul 2 si sa ne concentram doar asupra frecventelor marginale. Din totalul de 100 de clienti, 55 sau 55 % au avut ca rezultat succesul. Daca tipul de tratament nu este legat de succesul clientului, ar trebui sa ne asteptam ca aproximativ 55 de procente din totalul clientilor sa aiba succes, indiferent de tipul de tratament aplicat. Desi rezultatele dintr-un esantion particular nu vor iesi exact in acest mod, foarte adesea, intr-un numar mare de esantioane dintr-o populatie in care ipoteza nula este adevarata (variabilele in mod sigur sunt nelegate), vom gasi "rezultatul mediu" al tuturor esantioanelor; adica proportia medie de aproximativ de 55 %.
Putem construi un tabel al frecventelor asteptate presupunand ca ipoteza nula ar fi adevarata, asemanator Tabelului 4 . Pentru a calcula frecventa asteptata dintr-o celula, se ia totalul pe coloana, se inmulteste cu totalul de pe linie pentru acea celula si apoi se imparte rezultatul la numarul total de cazuri (N). Adica:
A (L) (C)
(N)
unde:
A = Frecventa asteptata intr-o celula particulara
L = Totalul pe linia celulei
C = Totalul pe coloana celulei
Inlocuind valorile vom gasi:
celula a:A = (60) (55) = 33
celula b: A = (60) (45) = 27
100
celula c: A = (40) (55) = 22
100
celula d: A = (40) (45) = 18
100
Totalul frecventelor asteptate = 100
Tabelul 4 Frecvente si procentaje asteptate
Succes?
Tip de tratament Da Nu Total
Tratament in grup 33 (55%) 27 (45%) 60 (100%)
Tratament individual 22 (55%) 18 (45%) 40 (100%)
Total 55 45 100
Tabelul 5 Diferenta dintre frecventele observate si cele asteptate
pentru tipul de tratament dupa succesul clientilor (din Tabelele 2 si 4)
Observate Asteptate = Diferente
Celule (Tabelul 2) -(Tabelul 4) = (Tabelul 5)
Celula a 40 - 33 = +7
Celula b 20 - 27 = -7
Celula c 15 - 22 = -7
Celula d 25 - 18 = +7
Total 100 - 100 = 0
Succes?
Tip de tratament Da Nu Total
Tratament in grup +7 -7 0
Tratament individual -7 +7 0
Total 0 0 0
Tabelul pentru frecventele observate este acum comparat cu tabelul frecventelor asteptate. Aceasta inseamna ca vom examina mai indeaproape diferentele dintre frecventele observate (Tabelul 3) si frecventele asteptate (Tabelul 4) pentru fiecare celula. Tabelul 5 prezinta diferentele matematice intre frecventele observate si frecventele asteptate din exemplul nostru.
Ar fi nevoie acum de un fel de rezumat al diferentelor prezentate in Tabelul 5. Simpla adunare a diferentelor pentru toate celulele nu este utila pentru ca va fi intotdeauna zero. Un rezumat mai bun este furnizat prin ridicarea la patrat a diferentelor din fiecare celula, impartirea acestor patrate la valoarea asteptata pentru fiecare celula si adunarea rezultatelor pentru toate celulele. Numarul care rezulta este numit valoarea hi-patrat, reprezentat de litera din alfabetul grec, hi cu semnul ridicarii la patrat. Putem exprima aceasta cu formula:
= (O - A)2
unde: 2= Valoarea hi-patrat
O = Frecventa observata
A = Frecventa asteptata
= Suma (tuturor celulelor)
Inlocuind literele cu valori gasim:
33 27 22 18
= (49) / 33 + (49) / 27 + (49) / 22 + (49) / 18
= 1,5 + 1,8 + 2,2 + 2,7
= 8,2 (valoarea lui hi-patrat)
Daca sunt doar patru celule, asa cum este cazul in exemplul nostru, trebuie sa mai scadem 0,5 din diferenta dintre frecventele observate si cele asteptate pentru fiecare celula inainte de ridicarea la patrat (acesta este Factorul de corectie al lui Yates). Dar de dragul simplificarii si pentru a prezenta formula obisnuita, exemplul nostru nu a mai efectuat aceasta scadere.
Inainte sa putem utiliza un tabel de asociere pentru calculul lui hi-patrat, pentru a determina daca exista o asociere statistic semnificativa intre cele doua variabile, avem nevoie sa intelegem conceptul de grade de libertate. Probabilitatea obtinerii unei valori hi-patrat mari este afectata de marimea tabelului de asociere pe baza caruia este calculat. Marimea se refera aici la numarul de coloane si de linii (adica numarul total de celule) din tabel. Cu cat tabelul este mai mare, cu atat este mai probabil sa avem o valoare mai mare al lui hi-patrat. Aceasta reiese evident din faptul ca valoarea hi-patrat este suma cifrelor derivate din fiecare dintre celule. Cu cat sunt mai multe celule intr-un tabel, cu atat vor fi mai multe cifre care adunate, vor creste valoarea lui hi-patrat.
Fiecare valoare hi-patrat trebuie sa fie evaluata tinand cont de dimensiunea tabelului, exprimata in termeni de grade de libertate. Numarul de grade de libertate pentru un tabel de asociere este egal cu numarul de linii minus unu, inmultit cu numarul de coloanelor minus unu. Putem scrie aceasta formula astfel:
df = (r-1) (c-1)
unde:
df = grade de libertate
r = numarul de linii
c = numarul de coloane
Inlocuind literele cu valorile din exemplul nostru, gasim:
df = (2-1) (2-1)
= (1) (1)
= 1 (grade de libertate)
Intr-adevar, Tabelul 2 are gradul unu de libertate, asa cum au toate tabelele formate din doua linii si doua coloane.
Pentru a determina daca valoarea lui hi-patrat pentru un tabel de asociere dat sugereaza sau nu o asociere statistic semnificativa intre variabile, trebuie sa gasim in primul rand linia care corespunde gradelor de libertate ale tabelului de asociere in Tabelul 6. Cele sase valori din fiecare linie a Tabelului 6 sunt valori hi-patrat care au probabilitatea indicata in capul de tabel al coloanelor respective. Vom citi in dreptul liniei pentru a gasi unde cade valoarea noastra hi-patrat. Daca numarul exact nu apare, vom considera numarul din stanga locului unde ar cadea valoarea lui hi-patrat. Dupa aceea ne vom deplasa la varful coloanei si vom gasi probabilitatea asociata lui.
Daca, de exemplu, fixam nivelul de probabilitate la 0,05, vom sti ca daca respingem ipoteza nula, probabilitatea statistica de a comite o eroare de tipul I este mai mica decat 5 din 100.
In exemplul nostru, valoarea obtinuta pentru hi-patrat este de 8,2, cu un grad de libertate. Luam valoarea lui hi-patrat de 8,2 si gasim cele doua valori din prima linie a Tabelului 6 intre care se gaseste aceasta valoare. Valoarea noastra hi-patrat, 8,2 este localizata intre valorile 6,64 si 10,83. Astfel, daca ipoteza noastra a fost directionala, adica "clientii care primesc tratamentul in grup au o rata statistic semnificativa mai inalta de succes decat clientii care primesc tratamentul individual", putem spune ca daca respingem ipoteza nula, exista o probabilitate de doar 0,005 de a face o eroare de tipul I (doar 5 dintr-o mie). Pe scurt, ipoteza noastra directionala poate fi considerata ca avand suport statistic, deoarece 0,005 este mult mai mic decat conventionalul 0,05. Pe de alta parte, daca ipoteza noastra ar fi fost nedirectionala, putem inca considera ca avem suport statistic pentru ea, pentru ca probabilitatea corespunzatoare este tot mai mica decat 0,01, care este mai mica decat conventionalul 0,05 .
Sa tinem minte ca trebuie sa folosim valoarea din stanga valorii calculate a lui hi-patrat pentru a determina corect nivelul probabilitatii. De exemplu, avem nevoie sa gasim o valoare hi-patrat la cel putin 2,71, cu un grad de libertate, pentru ca o ipoteza directionala sa fie sustinuta la un nivel obisnuit de semnificatie de 0,05.
Tabelul 6 Valori critice pentru hi-patrat
Nivel de semnificatie pentru un test directional
.10 .05 .025 .01 .005 .0005
Nivel de semnificatie pentru un test nedirectional
df .20 .10 .05 .02 .01 .001
10 13.44 15.99 18.31 21.16 23.21 29.59
11 163 17.28 19.68 22.62 272 31.26
12 15.81 18.55 21.03 205 26.22 32.91
13 16.98 19.81 22.36 25.47 27.69 353
14 18.15 21.06 23.68 26.87 29.14 36.12
15 19.31 22.31 25.00 28.26 30.58 37.70
16 20.46 23.54 26.30 29.63 32.00 39.29
17 21.62 277 27.59 31.00 33.41 40.75
18 22.76 25.99 28.87 32.35 380 42.31
19 23.90 27.20 30.14 33.69 36.19 43.82
20 25.04 28.41 31.41 35.02 37.57 45.32
21 26.17 29.62 32.67 36.34 38.93 46.80
22 27.30 30.81 33.92 37.66 40.29 48.27
23 28.43 32.01 35.17 38.97 41.64 49.73
24 29.55 33.20 36.42 40.27 42.98 51.18
25 30.68 338 37.65 41.57 431 52.62
26 31.80 35.56 38.88 42.86 45.64 505
26 31.80 35.56 38.88 42.86 45.64 505
27 32.91 36.74 40.11 414 46.96 55.48
28 303 37.92 41.34 45.42 48.28 56.89
29 35.14 39.09 42.69 46.69 49.59 58.30
30 36.25 40.26 43.77 47.96 50.89 59.70
32 38.47 42.59 46.19 50.49 53.49 62.49
34 40.68 490 48.60 53.00 56.06 65.25
36 42.88 47.21 51.00 55.49 58.62 67.99
38 45.08 49.51 53.38 57.97 61.16 70.70
40 47.27 51.81 55.76 60.44 63.69 73.40
44 51.64 56.37 60.48 65.34 68.71 78.75
48 55.99 60.91 65.17 70.20 73.68 804
52 60.33 65.42 69.83 75.02 78.62 89.27
56 666 69.92 747 79.82 83.51 946
60 68.97 740 79.08 858 88.38 99.61
Valoarea hi2 este semnificativa daca ea este mai mare sau egala cu valoarea listata in tabel
Prezentarea rezultatelor noastre obtinute in urma unei analize de asociere, este relativ simpla. In primul rand, vom prezenta tabelul de asociere cu frecventele observate, dupa aceea plasam valoarea hi-patrat (2), gradele de libertate (df), si probabilitatea (p) asociata valorii noastre 2 ca rezultatul sa se datoreze intamplarii, la sfarsitul tabelului. In PACHETUL STATISTIC PENTRU STIINTELE SOCIALE, in loc de notatia p pentru nivelul probabilitatii se foloseste notatia Sig. (nivel de semnificatie). Cele doua notiuni si notatiile corespunzatoare sunt absolut echivalente. Aceste trei elemente de informatie vor fi scrise astfel:
2 = 8,2; df = 1 ; p < 0,005
Tabelele 7; 8; 11 si 12 sunt exemple de prezentare a analizei de asociere.
Analiza hi-patrat poate sa ne fie foarte folositoare. Totusi, ea poate fi gresit inteleasa. Probabilitatea indicata poate sa nu fie prea adecvata in cazul in care frecventele asteptate din cateva celule ale tabelului de asociere sunt mici. Exista trei situatii in care procedeul tabelelor de asociere nu poate fi folosit:
Cand intr-un tabel cu doua linii si doua coloane (patru celule), una sau mai multe celule au valoarea asteptata mai scazuta decat 5.
Cand intr-un tabel cu mai mult decat doua linii si doua coloane, exista mai mult de 20% din celule care au valori asteptate mai mici decat 5.
Cand intr-un tabel cu mai mult decat doua linii si doua coloane, exista celule cu frecvente nule (0).
O verificare rapida daca sunt probleme cu valorile asteptate prea mici, intr-un tabel de asociere poate fi realizata prin localizarea celulei cu valoarea asteptata cea mai mica. Pentru a face aceasta, se localizeaza linia si coloana cu cele mai mici totaluri. Celula cu cea mai mica valoare se afla la intersectia liniei si coloanei localizate. Dupa aceea, valoarea asteptata a celulei este determinata cu formula (R) (C) / (N). Daca frecventa asteptata este 5 sau mai mult, este permisa folosirea analizei tabelului de asociere. Daca ea este mai mica decat 5, poate fi necesar sa combinam anumite celulele intre ele (prin grupare), astfel incat criteriul pentru folosirea lui hi-patrat sa poata fi indeplinit; sau se poate folosi un alt test statistic (vezi ultimul capitol). Desigur, un tabel 2 x 2 (doua linii si doua coloane) nu poate fi grupat.
In general, cu cat avem un esantion mai mare, cu atat avem mai multe sanse sa respingem ipoteza nula. Cu cat este mai mare dimensiunea esantionului, cu atat este mai puternic testul. (Acesta este valabil pentru orice test statistic) De fapt, cu un esantion foarte mare este extrem de probabil ca ipoteza nula sa fie respinsa, chiar daca diferenta absoluta dintre frecventele asteptate si cele observate din fiecare celula este suficient de mica. Cand oamenii interpreteaza un tabel de asociere, sunt adesea indusi in eroare de valoarea lui hi-patrat si de nivelul de probabilitate rezultat, mai ales daca nu urmaresc cu atentie volumul esantionului (N). Trebuie intotdeauna sa avem in minte ca o valoare hi-patrat si nivelul de probabilitate sunt legate direct de dimensiunea esantionului pe baza caruia sunt calculate.
Cele prezentate anterior pot parea greu de inteles, dar un acelasi tabel de asociere poate prezenta o legatura statistica importanta intre doua variabile (via indicatorul statistic hi-patrat) sau - credeti sau nu - el poate descrie o legatura slaba, dar statistic semnificativa. Pe scurt, putem aproape intotdeauna avea o valoare hi-patrat statistic semnificativa - interesand mai putin magnitudinea legaturilor dintre doua variabile - daca esantionul este suficient de mare. Astfel, trebuie intotdeauna sa privim la ceea ce inseamna legatura - nu doar nivelul de semnificatie statistica (p) al valorii hi-patrat. Aceasta este legata de discutia noastra dintr-un capitol anterior in care am facut distinctie intre: (1) legaturi statistic semnificative intre sau dintre variabile si (2) rezultate substantiale.
O continuare a exemplului nostru va clarifica cele afirmate. Sa presupunem ca intr-un alt studiu, 200 de clienti au primit tratament in cadrul programului de tratare a alcoolicilor. Rezultatul studiului poate fi asemenea celui prezentat in Tabelul 7. Asa cum poate fi observat din acest tabel, p este mai mare decat 0,20 doar daca directia legaturii nu a fost precizata si mai mare decat 0,10; daca s-a specificat directia in prealabil (vezi Tabelul 6). Cu alte cuvinte, noi am putea sa nu avem suport statistic suficient la nivelul 0,05 pentru a fi capabili sa respingem ipoteza nula.
Tabelul 7 Frecvente si procentaje observate
pentru tipul de tratament dupa succesul clientilor (N = 200)
Succes?
Tip de tratament Da Nu Total
Numar Procent Numar Procent Numar Procent
Tratament in grup 30 60.0% 20 40.0% 50 100%
Tratament individual 80 53.3% 70 46.7% 150 100%
Total 110 90 200
2 = 0,672, df = 1 ; p > 0,20 (fara predictia directiei)
Acum sa presupunem ca avem nu doar 200 de clienti, asa ca in Tabelul 7 ci de zece ori mai multi - 2000, iar proportia celor 2000 clienti in toate celulele este exact aceeasi ca si in cazul esantionului anterior, prezentat in Tabelul 7. Rezultatele se gasesc in Tabelul 8.
O privire atenta asupra Tabelelor 7 si 8 va arata ca frecventele observate in ambele tabele sunt absolut proportionale una fata de cealalta, dar diferenta intre valorile fiecarui hi-patrat si nivelele de probabilitate este foarte mare. Frecventele observate in Tabelul 7 nu sunt statistic semnificative, in timp ce frecventele observate in Tabelul 8 sunt statistic semnificative (la nivelul 0,01 pentru o ipoteza nedirectionala si la nivelul 0,005 pentru o ipoteza directionala). Daca am fi folosit 20000 clienti valoarea hi-patrat ar fi fost de 67,2; daca am fi folosit 200000 clienti, hi-patrat ar fi devenit 672 si asa mai departe. Si totusi, cele doua tabele 7 si 8 sunt aproape identice, singurul lucru care le diferentiaza este numarul de cazuri pe care le-am folosit pentru calcularea celor doua marimi hi-patrat.
Tabelul 8 Frecvente si procentaje observate
pentru tipul de tratament dupa succesul clientilor (N = 2000)
Succes?
Tip de tratament Da Nu Total
Numar Procent Numar Procent Numar Procent
Tratament in grup 300 60.0% 200 40.0% 500 100%
Tratament individual 800 53.3% 700 46.7% 1500 100%
Total 1100 900 2000
2 = 6,72, df = 1 ; p < 0,01 (fara predictia directiei)
De obicei ne concentram atentia mai intai pe legaturile dintre doua variabile. Totusi, trebuie sa avem in vedere ca o a treia variabila poate, intr-un anumit fel, "explica" legatura aparenta. In exemplul pe care-l vom folosi, incepem in primul rand cu legatura dintre cele doua variabile, tipul de tratament si succesul clientului. Este posibil ca o a treia variabila; nivelul motivatiei clientului inaintea intrarii la tratament, care nu a fost controlata metodologic, sa poate explica aparenta legatura intre variabila dependenta si cea independenta. Va trebui sa o reverificam pentru a avea o imagine mai buna asupra legaturii adevarate dintre tipul de tratament si succes. A treia variabila, motivatia clientului, se numeste variabila de control.
O modalitate de explorare a efectului celei de-a treia variabile este de a imparti clientii nostri dupa categoriile celei de-a treia variabile si de a examina legatura dintre variabilele principale, controlandu-le astfel prin prisma celei de-a treia variabile. In exemplu nostru, putem imparti esantionul in doua sub-categorii: cu motivatie inalta pentru tratament si cu motivatie scazuta pentru tratament. Putem dupa aceea construi doua tabele separate, pentru a urmari legatura dintre cele doua variabile: tipul de tratament si succesul clientului. Rezultatul poate aparea ca in Tabelul 9 (motivatie inalta pentru tratament) si Tabelul 10 (motivatie scazuta pentru tratament). Legatura dintre tipul de tratament si rezultatul clientului aproape ca a disparut, asa cum putem vedea examinand diferentele dintre frecventele observate si cele asteptate in celulele respective (ele sunt aproape zero). Astfel, controland motivatia clientilor pentru tratament, legatura aparenta dintre variabilele dependente si independente aproape ca a disparut. Este foarte probabil ca legatura aparenta dintre variabila dependenta si cea independenta sa nu fi fost una reala.
Legatura initiala nu dispare intotdeauna cand o controlam printr-o a treia variabila. Fireste, poate ramane in esenta aceeasi cu toate valorile celei de-a treia variabile. In astfel de cazuri, vom putea concluziona ca cea de a treia variabila nu joaca un rol important in explicarea legaturii initiale. Legatura poate fi mai scazuta chiar daca nu dispare. In acest caz, a treia variabila poate explica doar o parte, nu totul, dintr-o legatura initiala. Intensitatea legaturii poate sa creasca cand o a treia variabila este verificata. In asemenea situatii, cea de-a treia variabila este probabil variabila inabusita (se mai numeste si variabila latenta) aceasta ascunzand gradul real al asocierii dintre variabila dependenta si cea independenta.
Tabelul 9 Frecvente si procentaje observate pentru tipul de tratament
dupa succesul clientilor cu o motivatie inalta (N = 70)
Succes?
Tip de tratament Da Nu Total
Numar Procent Numar Procent Numar Procent
Tratament in grup 21 52.5% 19 47.5% 40 100%
Tratament individual 16 53.3% 14 46.7% 30 100%
Total 37 33 70
Tabelul 10 Frecvente si procentaje observate pentru tipul de tratament
dupa succesul clientilor cu o motivatie scazuta (N = 30)
Succes?
Tip de tratament Da Nu Total
Numar Procent Numar Procent Numar Procent
Tratament in grup 11 55% 9 45% 20 100%
Tratament individual 6 60% 4 40% 10 100%
Total 17 13 30
Astfel putem da peste un alt rezultat cand introducem o a treia variabila. Legatura dintre primele variabile poate fi diferita pentru diferitele categorii ale variabilei de control. Acesta nu este un rezultat simplu, el este adesea unul important. Nu intotdeauna este posibil sa obtinem usor rezultate rezumative; mai curand, legatura initiala trebuie sa fie descrisa pentru fiecare categorie a variabilei de control. A treia variabila este prezenta ca sa detaileze mai departe legatura dintre primele doua variabile, si se mai numeste variabila de control.
Descrierea situatiei care genereaza un studiu
Ca asistent social intr-un spital, Ioana se ocupa de internarea pacientilor. Ea a observat ca un numar mare de pacienti care au fost lasati sa traiasca cu propriile rude sunt reinternati in spital. Cunoscand ca asistentii sociali, colegi de ai ei, care se ocupa cu planificarea externarilor trimit frecvent pacientii externati la internat, ea s-a intrebat de ce a vazut atat de putine reinternari printre acei pacienti care au fost externati la internat. Ea s-a intrebat daca nu poate fi o legatura intre pacientii care sunt reinternati in spital si locul in care au fost ei externati (internat/la rude).
Ipoteza ce urmeaza a fi testata
Ioana citeste literatura de specialitate asupra temei care o preocupa. Bazandu-se apoi pe consensul general al altor practicieni de asistenta sociala, pe rezultatele cercetarilor anterioare si pe propriile intuitii si observatii subiective, ea porneste la realizarea si implementarea unei cercetari de mici proportii care va strange datele necesare testarii unei ipoteze directionale.
Pacientii externati la internat vor avea o rata de reinternare mai scazuta fata de pacientii externati la rude, statistic semnificativa.
O privire asupra metodologiei
Ioana a ales o strategie simpla pentru a testa ipoteza sa directionala. Ea a primit permisiunea supervizorilor sai sa selecteze un esantion de 10 procente din toate dosarele pacientilor care au fost externati in ultimele 18 luni, alese la intamplare. Utilizand un instrument de colectare a informatiilor standardizat intocmit de ea, a strans date de o mare varietate a variabilelor demografice pentru 148 de pacienti (10% din 1480 pacienti = 148 pacienti) care au fost externati la internat si 250 de pacienti (10% din 2500 pacienti = 250 pacienti) care au fost trimisi la rude. Esantionul total a fost de 398 pacienti (148+250=398). Variabila dependenta in ipoteza ei a fost statutul admisiei pacientilor (readmisi/nereadmisi). Variabila independenta a fost statutul externarilor pacientilor (internat/rude).
Rezultatele
Tabelul 11 prezinta rezultatele la care a ajuns Ioana, folosind procedeul tabelelor de asociere asa cum sunt prezentate in acest capitol.
Tabelul 11 Reinternarea in spital dupa starea externarii
Reinternare?
Starea externarii Da Nu Total
La internat 25 123 148
La rude 71 179 250
Total 96 302 398
2 = 7,2 , df = 1, p < 0.005 (utilizand corectia lui Yates)
Ce a aflat Ioana din testarea ipotezei directionale folosind tabelul de asociere? Din cunostintele sale generale despre testarea ipotezelor, ea stia ca p < 0.005, este un nivel de probabilitate impresionant. Aceasta a insemnat pentru ea ca diferentele dintre frecventele observate si cele asteptate au fost mari. Ea stia, de asemenea, ca daca respinge ipoteza nula pe baza analizei sale, va gresi de mai putine ori decat 5 dintr-o mie. Astfel, ea a putut respinge ipoteza nula si sa concluzioneze ca exista o legatura statistic semnificativa intre cele doua variabile. Important este ca ea a avut suport statistic pentru ipoteza ei directionala.
De asemenea, Ioana stia ca in analiza tabelei de asociere trebuie sa priveasca nu numai daca rezultatul este statistic semnificativ, dar si daca legatura intre cele doua variabile a fost in directia ipotezei. Asemenea altor teste statistice despre care vom discuta, tabelul de asociere nu ia in seama directia pretinsa a ipotezei. Deoarece in analiza tabelului de asociere se tine cont in primul rand de diferentele dintre frecventele asteptate si cele observate pentru toate celulele, el va fi sensibil la relativa marime sau micime a frecventelor observate pentru fiecare celula, netinand cont de ceea ce a fost prevazut. Mai trebuie sa ne reamintim ca o diferenta este doar o diferenta, chiar daca sugereaza numere mai mici sau chiar mai mari decat cele prezise. O diferenta mare intre frecventele observate si cele asteptate dintr-o celula (in orice directie) contribuie mult la cresterea valorii lui hi-patrat, care se va reflecta prin crestea probabilitatii ca ipoteza nula sa fie respinsa. Trebuie sa determinam daca asocierea este in directia prezisa, privind direct celulele in care se gasesc frecventele observate relativ mari, sau examinand procentajele.
Folosind Tabelul 11, Ioana a fost capabila sa determine ca aproximativ 17% (25 din 148) din pacientii externati la internat au fost readmisi in spital, comparativ cu 28% (71 din 250) dintre aceia dirijati catre rude. Aceste doua procentaje, 17 si 28 au fost consecvente cu directia ipotezei sale; pacientii eliberati catre internat au fost mai putin intalniti ca reinternati fata de pacientii externati la rude.
Inainte ca Ioana sa traga orice concluzie despre "insemnatatea" semnificatiei statistice dintre cele doua variabile, ea a stiut ca trebuie sa recunoasca efectele metodologiei de cercetare pe care a folosit-o in interpretarea rezultatelor obtinute. Ea a folosit un instrument de colectare a datelor standardizat si structurat. Totusi, validitatea si siguranta informatiilor din fisele pacientilor poate fi o problema, ca si alti factori deformatori. Din cauza lipsei unui plan experimental, lista altor variabile (factori) care ar fi putut afecta reinternarea ar putea fi mare. Printre acestia s-ar putea numara: diagnosticul pacientului, durata primei spitalizari, disponibilitatea serviciului de ingrijire de dupa externare, medicatia folosita de pacient si multi alti factori pe care ea nu are motiv sa creada ca au fost egal reprezentati in cele doua grupuri de pacienti (ingrijiti acasa / in internat).
Deci, ce ii spun rezultatele despre ipoteza? Scopul procedeului tabelelor de asociere este de a capata probe pentru sau impotriva existentei unei legaturi intre doua variabile. Cunoasterea relatiei cauza-efect nu este posibila de la inceput, datorita absentei unui plan experimental si datorita limitelor proprii ale analizei de asociere. Ceea ce Ioana a aflat este faptul ca pentru diferite motive, pacientii externati din spitalul ei catre internate, au avut o probabilitate mai mica sa fie reinternati fata de aceia care au fost eliberati acasa.
Ioana nu si-a limitat analiza asocierii doar la legatura dintre variabila independenta si cea dependente. Ea a mai adunat date despre diagnosticul pacientilor si durata primei spitalizari. Ea a putut deci examina legatura dintre aceste "alte variabile" si variabila dependenta folosind mai multe analize complexe ale tabelelor de asociere, si alte teste statistice adecvate. Fisele pacientilor pot contine informatii despre variabile suplimentare care au contribuit la luarea deciziei de externare, cum ar fi unde au locuit inainte de internare (la rude sau in internat); aceste informatii pot fi folosite pentru a tempera rezultatele analizei sale si pentru a lasa sa cada mai multa lumina pe rezultatele statistice.
Pentru a exemplifica asocierea cu ajutorul programului PACHETUL STATISTIC PENTRU STIINTELE SOCIALE, vom apela la fisierul de date "1991 US General Social Survey". Vom incerca sa vedem daca exista vreo asociere intre sexul respondentilor (variabila sex) si consumul de droguri (variabila hlth5). Vom considera sexul ca variabila independenta si consumul de droguri ca variabila dependenta, ambele variabile fiind dihotomice (cu doar doua variante de raspuns). Ipoteza de la care pornim este ca barbatii consuma intr-o masura mai mare droguri decat femeile.
Optiunile de meniu pe care le vom aplica in PACHETUL STATISTIC
PENTRU STIINTELE SOCIALE sunt: Statistics - Summarize - Crosstabs.
Fereastra de dialog deschisa de Crosstabs
contine lista tuturor variabilelor fisierului de date, din care vom
selecta variabilele ale caror categorii vor constitui randurile tabelului
(Rows - variabila sex), respectiv coloanele (Columns - variabila hlth5). Butonul Statistics
din aceeasi fereastra de dialog deschide, la randul sau, o
fereastra in care putem selecta coeficientii de asociere care dorim
sa fie calculati, in cazul nostru hi patrat - ![]() (Chi square). De la butonul Cells,
care apare tot in fereastra deschisa de optiunea de meniu Crosstabs, vom deschide o alta
fereastra in care vom opta ca in casutele tabelului sa
apara atat valorile observate, cat si cele calculate pentru cazul
independentei (frecventele asteptate sau teoretice): Counts - Observed, Expected. De
asemenea, vom opta aici pentru procente pe linii: Percentages - Row. Iata ce ne va afisa programul PACHETUL
STATISTIC PENTRU STIINTELE SOCIALE:
(Chi square). De la butonul Cells,
care apare tot in fereastra deschisa de optiunea de meniu Crosstabs, vom deschide o alta
fereastra in care vom opta ca in casutele tabelului sa
apara atat valorile observate, cat si cele calculate pentru cazul
independentei (frecventele asteptate sau teoretice): Counts - Observed, Expected. De
asemenea, vom opta aici pentru procente pe linii: Percentages - Row. Iata ce ne va afisa programul PACHETUL
STATISTIC PENTRU STIINTELE SOCIALE:
CROSSTABS
/TABLES=sex BY hlth5
/FORMAT= AVALUE TABLES
/STATISTIC=CHISQ
/CELLS= COUNT EXPECTED ROW .
Crosstabs
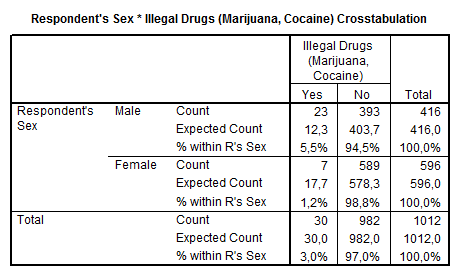
Observam ca mai intai programul PACHETUL STATISTIC PENTRU STIINTELE SOCIALE afiseaza sintaxa corespunzatoare optiunilor de meniu executate. Primul tabel este tabelul de asociere dintre variabila sex si variabila consum de droguri. Pentru ca am cerut calcularea procentelor pentru categoriile variabilei independente, putem observa o diferenta intre ponderea barbatilor si femeilor care au raportat consumul de droguri (5.5% fata de 1.2%). Ipoteza noastra pare sa fie confirmata de aceste date.
Urmatorul tabel contine valoarea coeficientului de asociere
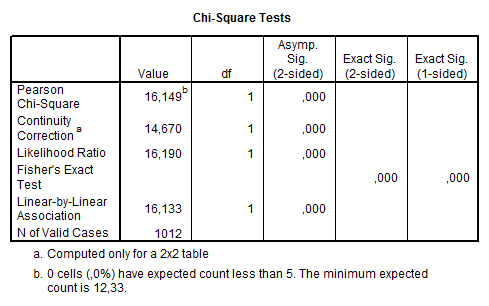
cerut, impreuna cu teste de semnificatie privind diferenta lor
fata de zero. Observam ca valoarea coeficientului de
corelatie ![]() (16,149), ne permite respingerea ipotezei nule, nivelul de
incredere fiind mai mare de 99% (p=0.000). Asadar, exista
diferente semnificative intre barbati si femei in
privinta consumului de droguri.
(16,149), ne permite respingerea ipotezei nule, nivelul de
incredere fiind mai mare de 99% (p=0.000). Asadar, exista
diferente semnificative intre barbati si femei in
privinta consumului de droguri.
Ce insemnatate au numerele din fiecare celula a unui tabel de asociere?
Ce se pierde cand se foloseste testul hi-patrat pentru date care sunt, de exemplu, de nivel interval si normal distribuite?
Poate indicatorul statistic hi-patrat sa ne spuna daca o variabila produce variatia in a doua variabila? Explicati.
Ce sunt frecventele asteptate si cum sunt ele folosite in testul hi-patrat?
Cum intervin gradele de libertate in determinarea semnificatiei statistice a unei valori hi-patrat precizate (de exemplu 10,00)?
Care este valoarea minima a frecventei asteptate necesare pentru folosirea lui hi-patrat?
Care sunt cei doi pasi ai procesului de determinare a suportului statistic pentru o ipoteza directionala?
Cum poate fi folosit hi-patrat pentru a examina legatura dintre doua variabile cand se tine sub control efectului unei a treia variabile?
Deschideti fisierul PACHETUL STATISTIC PENTRU STIINTELE SOCIALE "1991 U.S. General Social Survey ". Testati ipoteza ca femeile sunt in general mai putin fericite decat barbatii (variabilele "sex" si "happy").
Pornind de la datele din fisierul "1991 US General Social Survey", verificati daca exista vreo asociere intre sexul respondentilor si statutul de somer (variabila work1) cu ajutorul programului PACHETUL STATISTIC PENTRU STIINTELE SOCIALE. Comentati rezultatele obtinute.
Copyright © 2025 - Toate drepturile rezervate
| Statistica | |||
|
|||
|
| |||
|
| |||
|
|
|||