|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
Vom porni de la exercitiului 1 de la tema din capitol anterior (numarul de copii in SUA in functie de rasa), caruia ii aducem o modificare: in loc de cele 2 rase (albi, negri) vom lua in considerare si a treia varianta (other - ce poate fi asiatica, nativa, etc.) Ce metoda vom folosi pentru a afla daca numarul mediu de copii difera semnificativ in functie de rasa?
O prima solutie ar fi sa folosim testul t (testul Student) in trei pasi succesivi (vom vedea daca diferenta numarului mediu de copii intre "albi" si "negri", "negri" si "ceilalti", "ceilalti" si "negri" este semnificativa). Testul t ne spune ca noi vom testa probabilitatea unei valori t pentru un anumit numar de grade de libertate si o valoare predeterminata α (nivelul de semnificatie). In mod traditional valoarea t are asociata o probabilitate de 0.05 sau mai mica. Astfel, noi vom respinge ipoteza nula si vom afirma ca diferenta intre cele doua medii semnificativa (acceptam ca putem gresi in 5 sau mai putine cazuri din 100).
Ce se intampla daca noi vom folosi testul t de trei ori, si fiecare din rezultate ne va spune ca diferenta este semnificativa pentru p 0.05? (pentru exemplul dat acest lucru nu se intampla!) Sansa de a respinge in mod gresit ipoteza nula (erori de tipul I) este 5 din 100 sau mai mica? Raspunsul este: din contra, aceasta sansa creste! Cu cat marim numarul de teste t cu atat marim riscul de a face erori de gradul I (refuzul gresit al ipotezei nule). In statistica aceasta problema se numeste cresterea lui alpha (the inflation of alpha). Cum creste sansa noastra de a avea erori de tipul I? Formula dupa care se calculeaza este:
E(I)=1- (1- α)c
unde E(I) este probabilitatea de a face erori de tipul I, α este nivelul de semnificatie, iar c este numarul de comparari ce l-am facut.
Pentru problema noastra α este 0,05 iar c = 3 de unde rezulta ca E(I) este egala cu 0.1426, adica 14 din 100 ceea ce ne face sa afirmam ca in nici un caz nu vom folosi testul t pentru a testa daca diferenta intre mediile a mai mult de 2 grupuri este semnificativa statistic. Pentru astfel de probleme exista diferite metode de analiza, printre care si ANOVA.
ANOVA se concentreaza pe analiza semnificatiei diferentelor intre mediile grupurilor unui esantion (testul F). Raspunsul la aceasta problema depinde de mai multi factori:
diferenta de marime a mediilor grupurilor (variabilitatea lor).
marimea fiecarui grup: cu cat grupurile contin mai multi indivizi, cu atat sansa ca o diferenta (chiar mica intre medii) sa fie semnificativa creste.
varianta variabilei dependente in fiecare grup - diferentele dintre mediile grupurilor au o semnificatie statistica mai ridicata atunci cand diferentele din interiorul grupurilor sunt mai mici (populatia din interiorul grupurilor este mai omogena).
Analiza variantei (ANOVA, de la ANalysis Of VAriance) determina daca diferentele intre medii sunt semnificative si in acelasi timp previne cresterea lui α. ANOVA este folosita pentru a descoperi efectele principale si efectele de interactiune ale unei variabile categoriale (denumita factor) asupra unei variabile dependente de tip (cel putin) interval.
Dupa cum ii spune si numele, ANOVA are in centrul ei analiza variantei (unul din indicatorii variabilitatii), si se reduce practic la a folosi un indicator statistic cunoscut in acest moment: suma patratelor abaterilor (cunoscut din calculul abaterii standard).
Sa luam un exemplu: avem trei sub-esantioane diferite de indivizi: A, B, C, indivizii din aceste grupuri avand diferite varste. Ne intereseaza daca media varstelor pentru fiecare grup este diferita - in mod semnificativ, statistic, de exemplu pentru p 0.05. Vom rationa construind ipoteza nula (asemanator modului in care s-a facut in capitolul dedicat testului t): intre mediile grupurilor nu exista diferente semnificative. Daca ipoteza nula este respinsa atunci vom concluziona ca cel putin una din medii este diferita de celelalte. Atragem atentia ca folosind doar ANOVA nu vom descoperi si care sunt acestea.
|
Grupuri: |
A |
B |
C |
|
Varstele indivizilor: | |||
|
Total indivizi (k) | |||
|
Suma varstelor in grup | |||
|
Media varstelor in grupuri | |||
|
Media totala | |||
Tabel 7.1
Pentru a merge mai departe trebuie sa ne aducem aminte de formulele abaterii standard - din care retinem doar numitorul. Astfel Suma Patratelor abaterilor totale (notat de acum cu SPtotal) este:
SPtotal = (X - mediatotala)2.
Acest indicator, SPtotal este egal cu suma dintre Suma Patratelor din interiorul grupurilor (SPdin), adica suma patratelor abaterii valorilor in jurul mediei propriului grup (numit cateodata si Mean Square Error) si Suma Patratelor dintre grupuri (SPdintre) adica suma patratelor abaterilor medii ale grupurilor in jurul mediei grupului mare.
SPdin = Σ(X - mediagrup)2 iar
SPdintre = Σ kgrup(mediagrup - mediatotala)2
unde X sunt valorile variabilei iar k este frecventa indivizilor din interiorul fiecarui grup.
Pentru exemplul nostru vom avea:
|
X-mediaA |
X- mediaB |
X- mediaC |
Tabel 7.2
Unde mediaA reprezinta media grupului A, etc. Ridicand la patrat valorile obtinem:
|
(X-mediaA)2 |
(X- mediaB)2 |
(X- mediaC)2 |
|
|
Suma patratelor = |
|
Tabel 7.3
Astfel vom avea:
SPdin = 17,2 + 14,8 + 18,8 = 50,8
iar din tabelul 7.1 inlocuim valorile in formula SPdintre si vom avea:
SPdintre = 5*(16,6-18,2)2 + 5*(18,8-18,2)2 + 5*(19,2-18,2)2 = 19,6
Iar SPtotal = SPdin + SPdintre
Analiza variantei compara variatia dintre grupuri cu variatia din interiorul grupurilor. Daca variatia din interiorul grupurilor este mult mai mare decat variatia dintre grupuri atunci diferenta aparenta dintre grupuri poate fi cauzata de catre variatia din interiorul grupurilor si nu exista suficiente motive pentru a afirma ca diferentele dintre grupuri sunt semnificative.
Dar cele doua sume ale patratelor abaterilor nu sunt direct comparabile, deoarece SPdin se calculeaza pe N cazuri si k medii ale grupurilor (in exemplul nostru doar 15 cazuri si 3 medii ale grupurilor, dar in cazul esantioanelor mari putem avea mii de indivizi) iar SPdintre este calculat doar prin k grupuri, asa ca pentru a putea compara cele doua sume ale patratelor mai trebuie sa facem anumite operatii asupra lor: le vom diviza pe fiecare cu gradele de libertate (df) asociate, in modul urmator: pe SPdintre cu k-1, pe SPdin cu N - k iar pe SPtotal cu N - 1. Pentru exemplul nostru:
|
Suma patratelor |
df |
Media patratelor |
|
|
SPdintre | |||
|
SPdin | |||
|
SPtotal |
Tabel 7.4
Dupa ce avem calculate noile valori ale Sumelor Patratelor (coloana a 4 - a din tabel) vom calcula valoarea F:
F = (media SPdintre) / (media SPdin
Pentru exemplul nostru valoarea F este egala cu 2,315 - mai mica decat valoarea ce corespunde unui prag de semnificatie de 0,05. In acest caz nu vom putea respinge ipoteza nula ("diferentele intre medii nu sunt semnificative") si vom concluziona ca in cazul celor 3 grupuri nu exista diferente semnificative statistic.
Pentru a exemplifica folosirea analizei ANOVA in programul PACHETUL STATISTIC PENTRU STIINTELE SOCIALE vom deschide fisierul "GSS93 subset.sav". Ne intereseaza daca media numarului de ani de scoala (variabila educ: "Highest Year of School Completed") difera semnificativ in functie de statutul ocupational (variabila wrkstat: "Labor Force Status").
Vom alege procedura PACHETUL STATISTIC PENTRU STIINTELE SOCIALE din optiunea Analyze - Compare Means - One way ANOVA. Variabila dependenta este educatia (educ) iar variabila independenta, factorul, este wrkstat. La Options vom bifa casuta Descriptive pentru a vedea principalii indicatori descriptivi ai variabilei educatie pe subgrupuri, in functie de statutul ocupational: frecventa indivizilor, media, abaterea standard, eroarea standard, minimul si maximul, intervalul de incredere pentru medie (vezi tabelul urmator).
Descriptives
Highest Year of School Completed
|
N |
Mean |
Std. Deviation |
Std. Error |
95% Confidence Interval for Mean |
Minimum |
Maximum |
||
|
Lower Bound |
Upper Bound | |||||||
|
Working fulltime | ||||||||
|
Working parttime | ||||||||
|
Temp not working | ||||||||
|
Unempl, laid off | ||||||||
|
Retired | ||||||||
|
School | ||||||||
|
Keeping house | ||||||||
|
Other | ||||||||
|
Total | ||||||||
Tabel 7.5
Output-ul din PACHETUL STATISTIC PENTRU STIINTELE SOCIALE ne va afisa apoi rezultatul ANOVA:
ANOVA
Highest Year of School Completed
|
Sum of Squares |
df |
Mean Square |
F |
Sig. |
|
|
Between Groups | |||||
|
Within Groups | |||||
|
Total |
Tabel 7.6
In prima coloana sunt afisati, in ordine: SPdintre, SPdin si SPtotal iar in coloana a doua valorile ce le corespund. A treia coloana contine gradele de libertate asociate (df) cu care valorile din coloana a doua vor fi divizate. Rezultatul acestor operatii il vom vedea in coloana a patra, cu care in cele din urma va fi calculat indicatorul F: 36,239 ce este semnificativ pentru p < 0.001. Putem astfel sa respingem ipoteza nula si sa concluzionam ca mediile anilor de studiu sunt diferite in functie de statutul ocupational al persoanei.
ANOVA ne arata ca intre cele 8 medii ale grupurilor pe care le avem exista diferente semnificative dar nu ne poate spune si care sunt acele medii si grupurile ce le corespund. Pentru a rezolva aceasta problema, PACHETUL STATISTIC PENTRU STIINTELE SOCIALE-ul pune la dispozitia cercetatorului 14 teste diferite.
Ne vom opri atentia asupra unui singur test, Tukey pe care il vom gasi in casuta de dialog a ANOVA la Post Hoc (Post Hoc Multiple Comparison). Pentru exemplul precedent, daca bifam si in dreptul optiunii Tukey, in output-ul PACHETUL STATISTIC PENTRU STIINTELE SOCIALE vom primi urmatorul rezultat (aici putem alege nivelul de semnificatie pe care il dorim, in mod traditional acesta este 0.05):
Highest Year of School Completed
Tukey HSD
|
Labor Force Status |
N |
Subset for alpha = .05 |
|||
|
Other | |||||
|
Retired | |||||
|
Keeping house |
|
||||
|
Unempl, laid off | |||||
|
Working parttime | |||||
|
Temp not working | |||||
|
Working fulltime | |||||
|
School | |||||
|
Sig. | |||||
Tabel 7.7 Means for groups in homogeneous subsets are displayed.
a Uses Harmonic Mean Sample Size = 65,904.
b The group sizes are unequal. The harmonic mean of the group sizes is used. Type I error levels are not guaranteed.
Cum interpretam tabelul? Metoda Tukey HSD (Tukey's honest significant difference test) aseaza in prima coloana grupurile in ordine crescatoare, coloana a doua contine frecventele din interiorul fiecarui grup iar urmatoarele coloane valorile mediilor. Numarul acestor coloane ce apar in tabel (in cazul de fata patru) ne arata ca metoda Tukey a identificat 4 grupuri mari omogene ce contin diferitele statute ocupationale. Daca modificam pe alpha (gradul de semnificatie) si alegem valori mai mici, de exemplu 0.001, numarul grupurilor se reduce la 3. Observam ca aceleasi statute se regasesc in doua grupuri diferite: putem afirma despre acestea ca sunt tranzitorii, fac trecerea de la un grup la altul. De exemplu, grupul 4 (cu valorile cele mai mari ale anilor de educatie) este format din cei ce studiaza; banuim ca in marea majoritate acestia sunt tineri - si astfel putem observa efectul altei variabile, varsta, pentru ca cei in varsta se regasesc in grupul de pensionari, cu mai putini ani de educatie (aici putem vorbi despre efect de cohorta, de generatie: cu timpul, anii de educatie obligatorii sau medii cresc in societatile dezvoltate). Celor care sunt in scoala li se alatura in acest grup cei ce muncesc - aici trebuie sa atragem atentia ca la Descriptives putem vedea ca minimul de ani de educatie pentru acestia este 0, asa ca trebuie sa avem grija cand afirmam ca "in SUA, statutul de angajat presupune multi ani de educatie" pentru ca afirmatia nu este adevarata: exista diferite tipuri de locuri de munca, atat cele ce necesita specializare si multi ani de educatie cat si foarte multe locuri de munca necalificate (low-value added jobs). Urmatorul grup, cel al persoanelor care temporar nu muncesc ("Temp not working") este un grup tranzitoriu si poate fi inclus in grupul 4 sau grupul 3 (de preferat sa il consideram in grupul 4, explicatia o vom vedea mai jos, in Grafic 7.1, cand vom aplica un Boxplot pentru variabilele noastre).
ANOVA trebuie folosita doar cand avem variabile de nivel interval iar atunci cand variabila dependenta este de tip ordinal (Likert, etc.) se folosesc teste non-parametrice, de tip Kruskal-Wallace.
Omogenitatea variantei. Variabila dependenta trebuie sa aiba aceeasi varianta in fiecare dintre categoriile variabilei independente. Totusi, ANOVA este o metoda robusta care ramane valabila chiar si atunci cand aceasta cerinta este incalcata. Statisticienii afirma ca putem folosi ANOVA atunci cand diferentele intre valorile variantei (cea mai mica si cea mai mare valoare a variantelor din grupurile noastre) nu depaseste raportul 1:4. Incalcarea acestor reguli poate face ca indicatorul F sa fii supra sau sub-estimat.
Pentru a testa omogenitatea variantei se poate folosi Testul Levene (casuta de dialog ANOVA - Options - Homogeneity of variance test). Testul Levene este calculat de PACHETUL STATISTIC PENTRU STIINTELE SOCIALE pentru a testa asumptia ca fiecare grup (categorie) are aceeasi varianta. Daca testul Levene este semnificativ (cel putin) pentru nivelul 0.05, cercetatorul respinge ipoteza nula care afirma ca grupurile au varianta egala.
Pentru exemplul nostru, Output-ul afiseaza urmatorul tabel:
Test of Homogeneity of Variances
Highest Year of School Completed
|
Levene Statistic |
df1 |
df2 |
Sig. |
Tabel 7.8
Vedem ca testul Levene este semnificativ pentru p< 0,001 deci va trebui sa respingem ipoteza nula si sa afirmam ca variantele nu sunt egale. In aceasta situatie trebuie sa folosim alte teste pe care le avem la dispozitie.
Cand asumptia variantelor egale este incalcata, putem folosi testul Brown-Forsythe (mult mai robust decat ANOVA) si care trebuie folosit cand grupurile sunt inegale (asa cum este cazul nostru, dupa cum se observa din tabelul Descriptives). Acest test nu face asumptii asupra egalitatii variantelor.
Un alt test ce poate fi folosit este testul Welch, mai ales atunci cand variantele si marimea grupurilor sunt inegale. Atat Welch cat si Brown-Forsythe se pot alege din casuta de dialog Options in PACHETUL STATISTIC PENTRU STIINTELE SOCIALE. Mai jos avem tabelul pe care il afiseaza programul in Output atunci cand alegem aceste teste. Observam ca nivelul de semnificatie extrem de mare (p < 0.001) ramane neschimbat, asadar concluzia noastra ("exista diferente semnificative intre mediile subgrupurilor") ramane valabila.
Robust Tests of Equality of Means
Highest Year of School Completed
|
Statistic(a) |
df1 |
df2 |
Sig. |
|
|
Welch | ||||
|
Brown-Forsythe |
Tabel 7.9 a Asymptotically F distributed.
Distributia variabilei dependente trebuie sa fie normala in fiecare categorie a variabilei independente. Totusi, ANOVA este considerata robusta chiar si daca aceasta cerinta este incalcata. Putem testa asumptia de normalitate folosindu-ne de optiunea Boxplot din PACHETUL STATISTIC PENTRU STIINTELE SOCIALE, ce produce un grafic in care variabila dependenta apare pe axa Y grupata in k grupe. Dreptunghiurile ne arata imprastierea valorilor in fiecare grupa, iar linia mai groasa ne arata unde se aseaza media. Daca marea parte a dreptunghiului este asezata deasupra sau dedesubtul mediei atunci avem de-a face cu o distributie alungita si nu cu una normala. Pentru exemplul nostru avem graficul de mai jos, ce ne ajuta si sa grupam categoriile omogene (metoda Tukey).
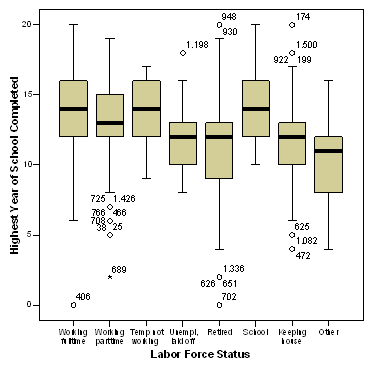
Grafic 7.1
Care este ipoteza nula testata de analiza variantei?
De ce nu putem sa folosim mai multe teste t intre toate perechile de medii pentru a vedea daca acestea sunt diferite sau nu?
Ce forma de oblicitate presupune indicatorul F?
Care sunt cele doua componente ale sumei totale ale patratelor?
Ce asumptii face ANOVA privitor la varianta in interiorul grupelor?
. 15 indivizi au rezultate diferite la un test de memorie (rezultatele se refera la itemi rezolvati corect). Stim ca acesti indivizi provin din trei clase diferite: A, B si C. Introducand datele urmatoare intr-un fisier PACHETUL STATISTIC PENTRU STIINTELE SOCIALE efectuati o ANOVA si testati diferentele intre grupuri folosind metoda Tukey pentru nivelul 0.05 de semnificatie.
A B C
6 7
3 7 7
2 8 5
1 4 7
4 6 9
. In programul PACHETUL STATISTIC PENTRU STIINTELE SOCIALE deschideti fisierul GSS93subset.sav. Efectuati o ANOVA in care variabila dependenta sa fie sibs ("Number of Brothers and Sisters") iar factorul sa fie race ("Race of Respondent"). Alegeti pragul de semnificatie 0,001, metoda Tukey pentru aflarea grupurilor omogene, verificati asumptia de omogenitate si interpretati rezultatul.
Bibliografie
Rotariu, Traian, Badescu Gabriel, Culic, Irina, Mezei, Elemer si Muresan, Cornelia (1999) Metode statistice aplicate in stiintele sociale, Iasi: Polirom.
Lungu, Ovidiu (2001) Ghid introductiv pentru PACHETUL STATISTIC PENTRU STIINTELE SOCIALE 10.0 Iasi, Seria Psihologie Experimentala si Aplicata.
On-line
https://statisticasociala.tripod.com
https://davidmlane.com/hyperstat/
https://www2.chass.ncsu.edu/garson/pa765/index.htm
https://psych.rice.edu/online_stat/
Copyright © 2025 - Toate drepturile rezervate
| Statistica | |||
|
|||
|
| |||
|
| |||
|
|
|||