|







 |  |
|
| |
 | Biologie | Chimie | Didactica | Fizica | Geografie | Informatica |
| Istorie | Literatura | Matematica | Psihologie |
Universitatea din Craiova Facultatea de Matematica - Informatica
PROIECT
Baze de Date
Notiuni de baza
Baza de date - ansamblu structurat de date inregistrate pe suporturi accesibile calculatorului, in scopul satisfacerii simultan, a mai multor cereri din partea utilizatorilor, in mod selectiv, si in timp optim
Informatie - Data
Articol ( Inregistrare , Rand)
Camp ( Atribut, Coloana)
Fisier ( Tabel )
Baza de date colectie de fisiere (sau tabele) cu legaturi logice intre ele
Banca de date sistem complex destinat conservarii, centralizarii si manipularii datelor
baza de date
hardware
software ( SGBD + aplicatii )
utilizatori - administratorul bazei de date
programatori de aplica]ie
utilizatori finali
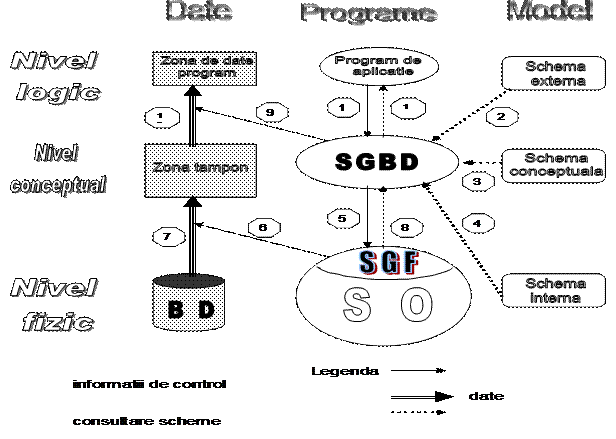
Arhitectura unui sistem de baze de date
- Un sistem de baze de date poate fi privit din patru puncte de vedere numite nivele:
Conceptual - descrie in mod natural sistemul
Extern - specifica informatiile ce pot fi privite de utilizator si modul de reprezentare al acestora
Logic - reprezentarea schemei conceptuale prin structuri abstracte
Fizic - reprezentarea sistemului intr-un anumit SGBD
- Este un sistem software care gestioneaza o baza de date si care permite utilizatorului sa interactioneze cu acesta . El actioneaza ca un depozit de date si este responsabil cu:
Stocarea datelor
Definirea structurilor de date
Manipularea datelor
Interogarea datelor
Pastrarea integritatii si securitatii datelor
Asigura un mecanism de recuperare al datelor
Asigurarea unui mecanism de indexare care sa permita accesul rapid la date
Organizarea logica a bazei de date
- La nivel logic baza de date este alcatuita din scheme;
- Obiectele schemei sunt urmatoarele:
Tabele
Vederi
Indecsi
Clustere secvente
Sinonime
Proceduri si functii de stocare
Pachete stocate
Declansatoare ale bazei de date
Legaturi ale bazei de date
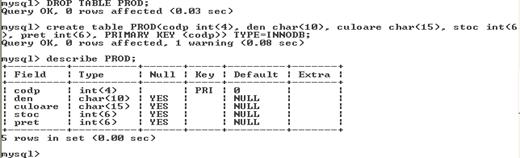
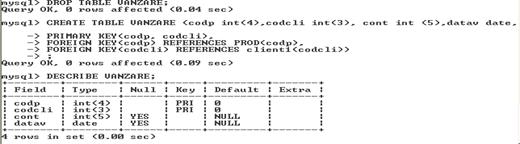
TABELE
- Tabelul este principala structura de stocare a datelor.
- Este o structura bidimensionala formata din:
randuri - inregistrari
si coloane - campuri
Crearea tabelelor
CREATE TABLE nume_tabel (nume_coloana tip_data [DEFAULT expresie] . .)
[PCTFREE intreg]
[PCTUSED intreg]
[TABLESPACE spatiu tabel]
[STORAGE parametrii_de_stocare]
o DEFAULT - desemneaza o valoare implicita pentru coloana,
o TABLESPACE - specifica spatiul tabel in care va fi stocat tabelul
o PCTFREE/PCTUSED - specifica gradul de utilizare al blocurilor
Se foloseste comanda SQL
CREATE TABLE
- Se specifica numele si tipul de date pentru fiecare coloana a tabelului
CREATE TABLE salariat
Sintaxa pentru constrangeri la nivel de tabel:
T CONSTRAINT - nume pentru integritatea definita
T NOT NULL | UNIQUE | PRIMARY KEY | FOREIGN KEY - tipuri de constrangeri
T ON DELETE CASCADE - clauza care sa poate folosi la definirea unei restrictii de integritate
Exemplu
CREATE TABLE departament cod_dept NUMBER(10)cod_tara NUMBER(10)
nume_deptPrenumeVARCHAR2(10)CONSTRAINT dept_pk PRIMARY EY(cod_dept, cod_tara));
CREATE TABLE salariat(cod_salariat NUMBER(10)CONSTRAINT sal_pk RIMARY KEY Nume VARCHAR2(10), NOT NULL Prenume VARCHAR2(10 Data_nastere DATE ,
SalariuNUMBER(10)CONSTRAINT sal_ck CHECK (salariu>0)Manager NUMBER(10) CONSTRAINT sal_sal_fk REFERENCES salariat(cod_salariat), Cod_deptNUMBER(10)
Cod_tara NUMBER(10) UNIQUE (nume, prenume, data nastere)CONSTRAINT sal_dept_fk FOREIGN KEY (cod_dept, cod_tara) REFERENCES departament (cod_dept,
cod_tara)
Comanda INSERT
Poate fi utilizata in doua moduri:
Pentru introducerea datelor intr-un tabel, cate o inregistrare la un moment dat
INSERT INTO tabel[(coloana1, coloana2, . )] VALUES (valoare1, valoare2, . )
Exemplu:
INSERT INTO profesor (cod, nume, prenume, data_nast, sef, salariu, cod_catedra)
VALUES (107, 'POPESCU', 'SERGIU', '09-DEC-
Reguli:
Coloanelel pot fi specificate in roice ordine, insa trebuie asigurata corespondenta intre coloanele si valorile furnizate (coloanei 1 ii corespunde valoarea 1, coloanei 2 ii corespunde valoarea 2) iar coloanelor nespecificate le va fi atasata valoarea Null;
In cazul in care coloanele nu sunt specificate explicit, se impune sa fie specificate valorile pentru toate coloanele si ordinea acestor valori sa coincida cu cea in care coloanele au fost definite la crearea tabelei(daca nu se cunoaste ordinea de declarare a coloanelor in tabela atunci se foloseste comanda DESCRIBE (nume_tabela )
Valorile trebuie sa aiba acelasi tip de data ca si campurile in care sunt adaugate;
Dimensiunea valorilor introduse trebuie sa fie mai mica sau cel putin egala cu dimensiunea coloanei;
Valorile introduse trebuie sa respecte restrictiile de integritate definite la crearea tabelei
Exemplu:
INSERT INTO profesor
VALUES
(107,'POPESCU', 'SERGIU', '09-DEC-
Pentru introducerea datelor intr-un tabel, prin copierea mai multor inregistrari dintr-un alt tabel sau grup de tabele; aceste inregistrari sunt rezulatatul unei comenzi SELECT;
SELECT INTO tabela [(coloana1, coloana2, . )] comanda_select;
Comanda UPDATE
Comanda folosita pentru a modifica datele existente intr-un tabel sau in tabele de baza ale unei vederi si are urmatoarea sintaxa generala
UPDATE tabela [alias]
SET atribuire_coloane, [atribuire_coloane, . ] [WHERE conditie];
Unde:
Atribuire_colaone poate avea una dintre urmatoarele forme:
Sintaxa pentru constrangeri la nivel de tabel:
T CONSTRAINT - nume pentru integritatea definita
T NOT NULL | UNIQUE | PRIMARY KEY | FOREIGN KEY - tipuri de constrangeri
T ON DELETE CASCADE - clauza care sa poate folosi la definirea unei restrictii de integritate
Exemplu
CREATE TABLE departament(cod_dept NUMBER(10) cod_tara NUMBER(10)nume_dept Prenume VARCHAR2(10) CONSTRAINT dept_pk PRIMARY KEY(cod_dept, cod_tara));
Sau:
CREATE TABLE salariat(cod_salariat NUMBER(10) CONSTRAINT sal_pk PRIMARY KEY Nume VARCHAR2(10), NOT NULL PrenumeVARCHAR2(10) Data_nastere DATE,
Salariu NUMBER(10) CONSTRAINT sal_ck CHECK (salariu>0) Manager NUMBER(10)
CONSTRAINT sal_sal_fk REFERENCES salariat(cod_salariat), Cod_dept NUMBER(10)
Cod_tara NUMBER(10) UNIQUE (nume, prenume, data nastere) CONSTRAINT sal_dept_fk FOREIGN KEY (cod_dept, cod_tara) REFERENCES departament (cod_dept, cod_tara)
Constrangerea FOREIGN KEY impune integritatea referentiale intre tabelul master (departament) si tabelul detaliu (salariat)
Aceasta inseamna ca un salariat nu poate fi adaugat decat daca departamentul corespunzator este fie NULL, fie exista in tabelul departament.
De asemenea nu poate fi sters un departament daca exista salariati in el.
Exista insa si posibilitatea de a permite stergerea unui departament in care exista salariati; in acest caz pentru mentinerea integritatii, este necesara si stergerea tuturor angajatilor dependenti.
Acest lucru este posibil prin adaugarea clauzei ON DELETE CASCADE pentru restrangerea FOREIGN KEY.
CREATE TABLE salariat(cod_salariat NUMBER(10) CONSTRAINT sal_pk PRIMARY KEYN Nume VARCHAR2(10), NOT NULL Prenume VARCHAR2(10) Data_nastere DATE,Salariu NUMBER(10) CONSTRAINT sal_ck CHECK (salariu>0) Manager NUMBER(10)CONSTRAINT sal_sal_fk REFERENCES salariat(cod_salariat), Cod_dept NUMBER(10)Cod_tara NUMBER(10) UNIQUE (nume, prenume, data nastere) CONSTRAINT sal_dept_fk FOREIGN KEY (cod_dept, cod_tara) REFERENCES departament (cod_dept, cod_tara) ON DELETE CASCADE);
Toate detaliile despre constangerile de integritate sunt stocate in dictionarul de date
De exemplu, pentru a vizualiza toate constangerile definite pentru tabelele de mai sus putem executa urmatoarea interogare asupra vederii ALL_CONSTRAINTS
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME FROM ALL_CONSTRAINTS WHERE TABLE_NAME IN ('SALARIATI', 'DEPARTAMENT');
Aceasta interogarea va avea ca rezultat:
CONSTRAINT_NAME C TABLE_NAME
-------- ----- ----- ----------
SYS_C002725 C SALARIAT
SAL_PK P SALARIAT
SAL_CK C SALARIAT
SYS_C002728 U SALARIAT
SAL_SAL_FK R SALARIAT
SAL_DEPT_FK R SALARIAT
DEPT_PK P DEPARTAMENT
Fiecare constrangere are asociat un nume.
In general este de preferat ca acesta sa fie dat in mod explicit de catre cel care creeaza tabelul.
In caz contrar numele este generat automat si va fi de forma "SYS_C . . "
MODIFICAREA TABELELOR
Se pot efectua urmatoarele tipuri de modificari:
Adaugare de noi coloane(impreuna cu eventualele constrangeri):
o ALTER TABLE departament
o ADD (localitate CHAR(10) NOT NULL);
Modificarea tipului de date sau a marimii unor coloane existente:
ALTER TABLE departament
MODIFY (nume_dept CHAR (20));
Adaugarea de noi constrangeri:
o ALTER TABLE salariat
o
ADD (CONSTRAINT data_ck
CHECK(data_nastere> '1900-10-
Stergerea unor constrangeri existente:
T ALTER TABLE salariat
T DROP CONSTRAINTS sal_ck;
Trebuie remarcat ca o constrangere PRIMAY KEY la care face referinta o constrangere FOREIGN KEY, nu poate fi stearsa decat daca impreuna cu constrangerea PRIMARY KEY sunt sterse si toate constrangerile referentiale asociate. Pentru aceasta se foloseste clauza CASCADE.
o ALTER TABLE departament
o DROP CONSTRAINTS dept_pk CASCADE;
DISTRUGEREA TABELELOR
Se foloseste comanda DROP TABLE:
T DROP TABLE salariat;
In cazul in care tabelul ce urmeaza a fi distrus are o cheie primara ce face referire la o cheie straina a altui tabel. In aceste situatii tabelul trebuie distrus impreuna cu toate constrangerile FOREIGN KEY care fac referire la cheia primara a acestuia si se realizeaza cu folosirea clauzei CASCADE CONSTRAINTS.
DROP TABLE salariat CASCADE CONSTRAINTS;
In momentul in care un tabel este distrus, vor fi sterse automat si toate datele din tabel cat si indecsii asociati lui. Vederile si sinonimele asociate unui tabel care a fost distrus vor ramane dar vor deveni invalide.
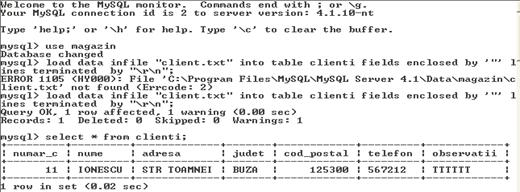
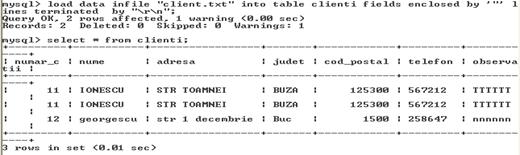
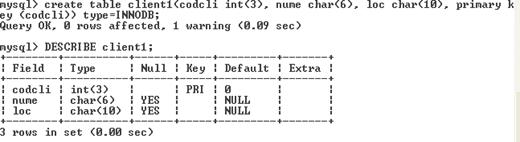
Jonctiuni
Jonctiuni echivalente
O echi-jonctiune contine operatorul egalitate (=) in clauza WHERE, combinand inregistrarile din tabele care au valori egale pentru coloanele specificate.
Pentru a afisa cadrele didactice si numele catedrei din care fac parte se combina inregistrarile din cele doua tabele pentru care codul catedrei este acelasi:
Mysql> SELECT p.nume, p.prenume, c.nume FROM professor p, catedra c WHERE p.cod_catedra=c.cod_catedra;
Raspuns:
NUME PRENUME NUME
----- ----- ---- ---------
GHEORGHIU STEFAN INFORMATICA
IONESCU VERONICA INFORMATICA
VOINEA MIRCEA INFORMATICA
MARIN VLAD ELECTRONICA
STEFANESCU MARIA ELECTRONICA
ALBU GHEORGHE ELECTRONICA
GEORGESCU CRISTIANA AUTOMATICA
Jonctiuni neechivalente
Sunt acelea care nu folosesc in clauza WHERE operatorul egal. Operatorii cei mai utilizati in cazul jonctiunilor neechivalente sunt: <,>, <=, >=, <>, BETWEEN . AND .
Tabela gradsal ce contine gradul minim al salariului dintr-un anumit grad de salarizare:
GRAD_SALARIZARE PRAG_MIN PRAG_MAX
----- ----- ------ ----- ----- ------
500 1500
1501 2000
2001 2500
2501 3500
3501 10000
Intre tabelele profesor si gradsal nu are sens definirea unei jonctiuni echivalente deoarece nu exista o coloana din tabela profesor careia sa-i corespunda o coloana din tabela gradsal. Exemplul urmator ilustreaza definirea unei jonctiuni neechivalente care evalueaza gradul de salarizare a cadrelor didactice, prin incadrarea salariului acestora intr-un interval stabilit de pragul minim si pragul maxim:
Mysql> SELECT p.nume, p.grad,p.salariu, g.grad_salarizare FROM profesor p, gradsal g,
WHERE p.salariu BETWEEN g.grad_min AND g.prag_max;
Raspuns:
NUME GRAD SALARIU GRAD_SALARIZARE
IONESCU ASIST 1500 1
VOINEA ASIST 1200 1
STANESCU ASIST 1200 1
MARIN PROF 2500 3
ALBU LECT 2200 3
GHEORGHIU PROF 3000 4
GEORGESCU CONF 2800 4
Auto-jonctiuni
v Reprezinta jonctiunea unui table cu el insusi. Pentru ca randurile dintr-un table sa poata fi compuse cu randurile din acelasi table, in clauza FROM a interogarii numele tabelului va apare de mai multe ori, urmat de fiecare data de un alias.
v De exemplu, pentru a selecta toate cadrele didactice care au un sef direct si numele acestui sef se foloseste urmatoarea auto-jonctiune:
Mysql> SELECT p.nume, p.prenume, s.nume, s.prenumeFROM profesor p, profesor s
WHERE p.sef=s.cod;
Raspuns:
NUME PRENUME NUME
MARIN VLAD GHEORGHIU STEFAN
GEORGESCU CRISTIANA GHEORGHIUSTEFAN
ALBU GHEORGHE GHEORGHIU STEFAN
VOINEA MIRCEA GHEORGHIU STEFAN
IONESCU VERONICA GEORGESCU CRISTIANA
STEFANESCU MARIA IONESCU VERONICA
v Auto-jonctiunea poate fi folosita si pentru verificarea corectitudinii interne a date lor. De exemplu este putin probabil sa existe doua cadre didactice care au cod diferit dar in schimb au acelasi nume prenume si data de nastere. Pentru a verifica daca exista astfel de inregistrari se foloseste interogarea:
Mysql> SELECT a.nume, a.prenume FROM profesor a, profesor b WHERE a.nume = b.nume AND a.prenume= b.prenume AND a.data_nast=b.data_nast AND a.cod<>b.cod;
Proiectare - Normalizare
Baze de date
Schemele bazei de date sunt: conceptuala, externa si interna.
A) Proiectarea schemei conceptuale porneste de la identificarea setului de date necesar sistemului. Aceste date sunt apoi integrate si structurate intr-o schema (exemplu: pentru BDR relationale cea mai utilizata tehnica este normalizarea). Pentru acest lucru se parcurg pasii:
. Stabilirea schemei conceptuale initiale care se deduce din modelul entitate-asociere (vezi analiza structurala). Pentru acest lucru, se transforma fiecare entitate din model intr-o colectie de date (fisier), iar pentru fiecare asociere se definesc cheile aferente. Daca rezulta colectii izolate, acestea se vor lega de alte colectii prin chei rezultand asocieri (1:1, 1:m, m:n).
. Ameliorarea progresiva a schemei conceptuale prin eliminarea unor anomalii (exemplu: cele cinci forme normale pentru BDR relationale).
. Stabilirea schemei conceptuale finale trebuie sa asigure un echilibru intre cerintele de actualizare si performantele de exploatare (exemplu: o forma normala superioara asigura performante de actualizare, dar timpul de raspuns va fi mai mare).
Tehnica de normalizare este utilizata in activitatea de proiectare a structurii BDR si consta in eliminarea unor anomalii (neajunsuri) de actualizare din structura.
Anomaliile de actualizare sunt situatii nedorite care pot fi generate de anumite tabele in procesul proiectarii lor:
. Anomalia de stergere semnifica faptul ca stergand un tuplu dintr-o tabela, pe langa informatiile care trebuie sterse, se pierd si informatiile utile existente in tuplul respectiv;
. Anomaliile de adaugare semnifica faptul ca nu pot fi incluse noi informatii necesare intr-o tabela, deoarece nu se cunosc si alte informatii utile (de exemplu valorile pentru cheie);
. Anomalia de modificare semnifica faptul ca este dificil de modificat o valoare a unui atribut atunci cand ea apare in mai multe tupluri.
Normalizarea este o teorie construita in jurul conceptului de forme normale (FN), care amelioreaza structura BDR prin inlaturarea treptata a unor neajunsuri si prin imprimarea unor facilitati sporite privind manipularea datelor.
Normalizarea utilizeaza ca metoda descompunerea (top-down) unei tabele in doua sau mai multe tabele, pastrand informatii (atribute) de legatura.
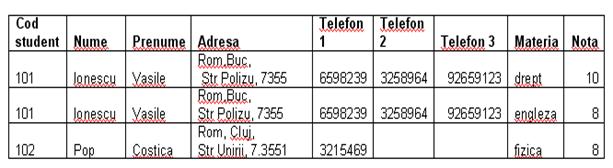
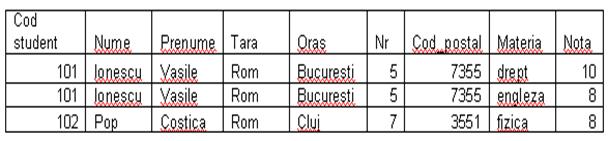
FORMA NORMALA 1
FN1. O tabela este in FN1 daca toate atributele ei contin valori elementare (nedecompozabile), adica fiecare tuplu nu trebuie sa aiba date la nivel de grup sau repetitiv. Structurile de tip arborescent si retea se transforma in tabele cu atribute elementare.
O tabela in FN1 prezinta inca o serie de anomalii de actualizare datorita eventualelor dependente functionale incomplete.
Fiecare structura repetitiva genereaza (prin descompunere) o noua tabela, iar atributele la nivel de grup se inlatura, ramanand doar cele elementare.
Algoritmul 1FN
Se inlocuiesc in tabel datele corespunzatoare atributelor compuse cu coloane ce contin componentele elementare ale acestora.
Se plaseaza grupurile de atribute repetitive, fiecare in cate un nou tabel
Se introduce in fiecare tabel nou creat la pasul 2 cheia primara a tabelului din care a fost extras atributul respectiv care devine cheie straina in noul tabel.
Se stabileste cheia primara a fiecarui nou tabel creat la pasul 2. Aceasta va fi compusa din cheia straina introdusa la pasul 3 plus una sau mai multe coloane aditionale.
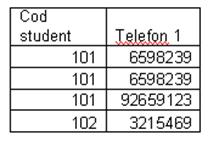
FORMA NORMALA 2
FN2. O tabela este in FN2 daca si numai daca
v este in FN1
v orice atribut neprim este complet dependent functional de orice chei candidat a relatiei
Un atribut B al unei tabele depinde functional de atributul A al aceleiasi tabele, daca fiecarei valori a lui A ii corespunde o singura valoare a lui B, care ii este asociata in tabela.
Un atribut al unei relatii se considera neprim daca nu participa in nici o cheie a relatiei
Un atribut B este dependent functional complet de un ansamblu de atribute A in cadrul aceleiasi tabele, daca B este dependent functional de intreg ansamblul A (nu numai de un atribut din ansamblu).
O tabela in FN2 prezinta inca o serie de anomalii de actualizare, datorita eventualelor dependente tranzitive.
Eliminarea dependentelor incomplete se face prin descompunerea tabelei initiale in doua tabele, ambele continand atributul intermediar (B).
A doua conditie din definitia 2FN poate fi exprimata in mod general astfel: fiecare atribut al relatiei depinde functional de cheia relatiei , in integralitatea ei.
O relatie in 1FN care are drept chei numai chei simple este o relatie in 2 FN.
Algoritmul de transformare a unei relatii echivalente aflate in 2FN este urmatorul:
Prin fiecare coloana X care depinde functional partial de o chei K, KgX, si care nu este inclusa in K, se determina K1 K un subset al lui K, astfel incat dependenta K1 gX este totala si se creeaza in nou tabel R1(K1,X), adica un tabel format numai din determinantul (K1) si determinantul (X) acestei dependente.
Daca in tabelul R exista mai multe dependente totale ca mai sus cu acelasi determinant, atunci pentru acestea se creeaza un singur tabel format din determinant - luat o singura data si din determinantii dependentelor considerate.
Se elimina din tabelul initial R toate coloanele, x, care formeaza determinantul dependentei considerate.
Se determina cheia primara a fiecarui tabel nou creat, R1. Aceasta va fi K1, determinantul dependentei considerate.
Daca noile tabele create contin alte dependente partiale, atunci se merge la pasul 1, altfel algoritmul se termina.
Algoritmul se repeta pentru toate relatiile nou create, pana cand toate acestea vor ajunge in a doua forma normala.
FORMA NORMALA 3
FN3. O tabela este in FN3 daca si numai daca
v este in FN2
v fiecare atribut neprim depinde in mod netranzitiv de cheia tabelei. Intr-o tabela T, fie A,B,C trei atribute cu A cheie. Daca B depinde de A (A B) si C depinde de B (B C) atunci C depinde de A in mod tranzitiv. Eliminarea dependentelor tranzitive se face prin descompunerea tabelei initiale in doua tabele, ambele continand atributul intermediar (B).
O tabela in FN3 prezinta inca o serie de anomalii de actualizare, datorate eventualelor dependente multivaloare.
O definitie mai riguroasa pentru FN3 a fost data prin forma intermediara BCNF (Boyce Codd Normal Form): o tabela este in BCNF daca fiecare determinant este un candidat cheie. Determinantul este un atribut elementar sau compus fata de care alte atribute sunt complet dependente functional.
Algoritmul 3FN
In relatia initiala se determina toate dependentele functionale si se selecteaza cele care au ca sursa atribute neprime; daca exista astfel de dependente atunci schema relatiei se descompune in doua subscheme, conform algoritmului de la pasul 2.
Pentru fiecare dependenta functionala identificata la pasul 1 se defineste o descompunere a schemei relatiei initiale in doua subscheme, astfel:
l Prima subschema va avea drept cheie primara sursa dependentei functionale selectate
l A doua subschema se obtine din vechea schema , prin inlaturarea atributelor incluse in prima subschema, mai putin atributele care alcatuiesc cheia primara in prima subschema.
O definitie mai riguroasa pentru FN3 a fost data prin forma intermediara BCNF (Boyce Codd Normal Form): o tabela este in BCNF daca fiecare determinant este un candidat cheie. Determinantul este un atribut elementar sau compus fata de care alte atribute sunt complet dependente functional = orice dependenta functionala XgA, unde A este un subset de coloane, iar A o coloana necontinuta in X, X este o cheie a lui R.
Pentru fiecare dependenta non-cheie XgY, unde X si Y sunt subseturi de coloane ale lui R , se creeaza 2 tabele. Una dintre ele va fi formata din coloanele , iar cealalta va fi formata din toate coloanele mai putin Y.
Daca tabelele celelalte contin alte dependente non-cheie, atunci se merge la pasul 1, altfel algoritmul se termina.
FORMA NORMALA 4
FN4. O tabela este in FN4 daca si numai daca este in FN3 si nu contine doua sau mai multe dependente multivaloare. Intr-o tabela T, fie A,B,C trei atribute. In tabela T se mentine dependenta multivaloare A daca si numai daca multimea valorilor lui B ce corespunde unei perechi de date (A,C), depinde numai de o valoare a lui A si este independenta de valorile lui C.
FORMA NORMALA 5
FN5. O tabela este in FN5 daca si numai daca este in FN4 si fiecare dependenta jonctiune este generata printr-un candidat cheie al tabelei. In tabela T (A,B,C) se mentine dependenta jonctiune (AB, AC) daca si numai daca T mentine dependenta multivaloare A -->> B sau C.
Dependenta multivaloare este caz particular al dependentei jonctiune. Dependenta functionala este caz particular al dependentei multivaloare.
Concluzii-normalizare
Normalizarea este procesul de transformare a datelor si are ca scop eliminarea redundantelor si promovarea integritatii datelor. Normalizarea este un pilon de baza al bazelor de date relationale.
Normalizarea datelor este impartita in sase etape, numite forme normale:
B) Proiectarea schemei externe are rolul de a specifica viziunea fiecarui utilizator asupra BDR. Pentru acest lucru, din schema conceptuala se identifica datele necesare fiecarei viziuni.
Datele obtinute se structureaza logic in subscheme tinand cont de facilitatile de utilizare si de cerintele utilizator.
Schema externa devine operationala prin construirea unor viziuni (view) cu SGBD-ul si acordarea drepturilor de acces.
Datele intr-o viziune pot proveni din una sau mai multe colectii si nu ocupa spatiul fizic.
C) Proiectarea schemei interne presupune stabilirea structurilor de memorare fizica a datelor si definirea cailor de acces la date.
Acestea sunt specifice fie SGBD-ului (scheme de alocare), fie sistemului de operare.
Proiectarea schemei interne inseamna estimarea spatiului fizic pentru BDR, definirea unui model fizic de alocare (a se vedea daca SGBD-ul permite explicit acest lucru) si definirea unor indecsi pentru accesul direct, dupa cheie, la date.
2)Proiectarea modulelor functionale tine cont de conceptia generala a BDR, precum si de schemele proiectate anterior. In acest sens, se proiecteaza fluxul informational, modulele de incarcare si manipulare a datelor, interfetele specializate, integrarea elementelor proiectate cu organizarea si functionarea BDR.
3) Realizarea componentelor logice. Componentele logice ale unei BD sunt programele de aplicatie dezvoltate, in cea mai mare parte, in SGBD-ul ales. Programele se realizeaza conform modulelor functionale proiectate in etapa anterioara. Componentele logice tin cont de iesiri, intrari, prelucrari si colectiile de date. In paralel cu dezvoltarea programelor de aplicatii se intocmesc si documentatiile diferite (tehnica, de exploatare, de prezentare).
4) Punerea in functiune si exploatarea. Se testeaza functiile BDR mai intai cu date de test, apoi cu date reale. Se incarca datele in BDR si se efectueaza procedurile de manipulare, de catre beneficiar cu asistenta proiectantului. Se definitiveaza documentatiile aplicatiei. Se intra in exploatare curenta de catre beneficiar conform documentatiei.
5) Dezvoltarea sistemului. Imediat dupa darea in exploatare a BDR, in mod continuu, pot exista factori perturbatori care genereaza schimbari in BDR.
Factorii pot fi: organizatorici, datorati progresului tehnic, rezultati din cerintele noi ale beneficiarului, din schimbarea metodologiilor etc.
Regulile lui Codd
E.F. Codd (cercetator
R0. Gestionarea datelor la nivel de relatie: limbajele utilizate trebuie sa opereze cu relatii (unitatea de informatie).
R1. Reprezentarea logica a datelor: toate informatiile din BDR trebuie stocate si prelucrate ca tabele.
R2. Garantarea accesului la date: LMD trebuie sa permita accesul la fiecare valoare atomica din BDR (tabela, coloana, cheie).
R3. Valoarea NULL: trebuie sa se permita declararea si prelucrarea valorii NULL ca date lipsa sau inaplicabile.
R4. Metadatele: informatiile despre descrierea BDR se stocheaza in dictionar si trateaza ca tabele ,la fel ca datele propriu-zise.
R5. Limbajele utilizate: SGBDR trebuie sa permita utilizarea mai multor limbaje, dintre care cel putin unul sa permita definirea tabelelor (de baza si virtuale), definirea restrictiilor de integritate, manipularea datelor, autorizarea accesului, tratarea tranzactiilor.
R6. Actualizarea tabelelor virtuale: trebuie sa se permita ca tabelele virtuale sa fie si efectiv actualizabile, nu numai teoretic actualizabile (exemplu atributul "valoare" dintr-o tabela virtuala nu poate fi actualizat).
R7. Actualizarile in baza de date: manipularea unei tabele trebuie sa se faca prin operatii de regasire dar si de actualizare.
R8. Independenta fizica a datelor: schimbarea structurii fizice a datelor (modul de reprezentare (organizare) si modul de acces) nu afecteaza programele.
R9. Independenta logica a datelor: schimbarea structurii de date (logice) a tabelelor nu afecteaza programele.
R10. Restrictiile de integritate: acestea, trebuie sa fie definite prin LDD si stocate in dictionarul (catalogul) BDR.
R11. Distribuirea geografica a datelor: LMD trebuie sa permita ca programele de aplicatie sa fie aceleasi atat pentru date distribuite cat si pentru date centralizate (alocarea si localizarea datelor vor fi in sarcina SGBDR-ului).
R12. Prelucrarea datelor la nivel de baza (scazut): daca SGBDR poseda un limbaj de nivel scazut (prelucrarea datelor se face la nivel de inregistrare), acesta nu trebuie utilizat pentru a evita restrictiile de integritate.
Regulile lui Codd sunt greu de indeplinit in totalitate de catre SGBDR. Pornind de la cele 13 reguli de mai sus, au fost formulate o serie de criterii (cerinte) pe care trebuie sa le indeplineasca un SGBD pentru a putea fi considerat relational intr-un anumit grad.
S-a ajuns astfel, la mai multe grade de relational pentru SGBDR: cu interfata relationala (toate datele se reprezinta in tabele, exista operatorii de selectie, proiectie si jonctiune doar pentru interogare), pseudorelational (toate datele se reprezinta in tabele, exista operatorii de selectie, proiectie si jonctiune fara limitari), minimal relational (este pseudorelational si in plus, operatiile cu tabele nu fac apel la pointeri observabili de utilizatori), complet relational (este minimal relational si in plus, exista operatorii de reuniune, intersectie si diferenta, precum si restrictiile de integritate privind unicitatea cheii si restrictia referentiale).
Obiectele bazei de date: Indecsi
Index - structura ordonata care permite:
cresterea performantelor ( localizarea directa, rapida, a unui rand al unei tablele)
asigurarea integritatii datelor (unicitatea valorilor)
Operatii:
creare
- stergere
- ( actualizarea automata la operatii de manipulare a datelor )
Clasificare indecsi
Clasificare din punct de vedere logic:
dupa o coloana (single column)
sau mai multe coloane (concatenated index)
unic (Unique) sau neunic (nonUnique)
Clasificare din punct de vedere fizic:
partitionat sau nepartitionat
de tip arbore binar (B-tree) sau bitmap
Crearea indecsilor
Un index unique este creat automat cand se defineste o restrictie de intgritate de tip PRIMARY KEY sau UNIQUE.
Manual
Utilizatorul poate crea indecsi nonunique pentru anumite coloane pentru a micsora timpul de acces la randuri
Utilitatea indecsilor
Indecsii se creaza atunci cand:
The column is used frequently in the WHERE clause or in a join condition.
The column contains a wide range of values.
The column contains a large number of null values.
Two or more columns are frequently used together in a WHERE clause or a join condition.
The table is large and most queries are expected to retrieve less than 2-4% of the rows.
Utilitatea indecsilor
Indecsii NU se creaza atunci cand:
The table is small
The columns are not often used as a condition in the query
Most queries are expected to retrieve more than 2-4% of the rows
The table is updated frequently
Crearea unui index B-Tree
CREATE [ UNIQUE ] INDEX [schema.] index
ON [schema.] tabela
( coloana [ ASC | DESC ] [, coloana [ ASC | DESC ] , ] )
[TABLESPACE tablespace ]
[PCTFREE integer ]
[STORAGE ( INITIAL integer [ ]
NEXT integer [ ]
PCTINCREASE integer
MINEXTENTS integer
MAXEXTENTS integer ) ] ;
CREATE INDEX sal_dept_ind
ON salariat(cod_dept, cod_tara) ;
CREATE UNIQUE INDEX nume_dept_ind
ON departament(nume_dept) ;
CREATE INDEX scott.emp_lname_idx
ON scott.employees(last_name)
PCTFREE 30
STORAGE(INITIAL 200K NEXT 200K
PCTINCREASE 0 MAXEXTENTS 50)
TABLESPACE indx01;
Crearea unui index Bitmap
CREATE BITMAP INDEX [schema.] index
ON [schema.] tabela
( coloana [ ASC | DESC ] [, coloana [ ASC | DESC ] , ] )
[TABLESPACE tablespace ]
[PCTFREE integer ]
[STORAGE ( INITIAL integer [ ]
NEXT integer [ ]
PCTINCREASE integer
MINEXTENTS integer
MAXEXTENTS integer ) ] ;
Exemplu
CREATE BITMAP INDEX scott.ord_region_id_idx
ON scott.ord(region_id)
PCTFREE 30
STORAGE(INITIAL 200K NEXT 200K
PCTINCREASE 0 MAXEXTENTS 50)
TABLESPACE indx01;
Modificarea parametrilor de stocare
ALTER INDEX [schema.] index
[STORAGE ( INITIAL integer [ K | M ]
NEXT integer [ K | M ]
PCTINCREASE integer
MINEXTENTS integer
MAXEXTENTS integer ) ] ;
ALTER INDEX scott.emp_lname_idx
STORAGE(NEXT 400K
MAXEXTENTS 100);
Refacerea indecsilor
ALTER INDEX [schema.] index REBUILD
[TABLESPACE tablespace ]
[PCTFREE integer ]
[STORAGE ( INITIAL integer [ ]
NEXT integer [ ]
PCTINCREASE integer
MINEXTENTS integer
MAXEXTENTS integer ) ] ;
CREATE TABLE salariatiStergerea unui index
DROP INDEX [schema.] index ;
Obtinerea de informatii asupra indecsilor
Dictionarul de date
Dictionarul de date furnizeaza informatii despre :
indecsi si coloanele ce compun indecsii
Disponibile pentru utilizator :
user_indexes
user_ind_columns
SQL> describe user_ind_columns
Name Null? Type
INDEX_NAME NOT NULL VARCHAR2(30)
TABLE_NAME NOT NULL VARCHAR2(30)
COLUMN_NAME VARCHAR2(4000)
COLUMN_POSITION NOT NULL NUMBER
COLUMN_LENGTH NOT NULL NUMBER
SQL> select * from user_ind_columns where table_name='PROD';
INDEX_NAME TABLE_NAME COLUMN_NAME COLUMN_POSITION COLUMN_LENGTH
PROD_PK PROD CODP 1 22
Comanda ANALYZE
ANALYZE INDEX [schema.] tabela
VALIDATE STRUCTURE ;
Rezultatul: in INDEX_STATS
Obiectele bazei de date: Tabele virtuale
Tabela virtuala - structura logica cu date continute in baza de date care permite:
restrictionarea accesului la baza de date
simplificarea interogarilor
realizarea independentei logice a datelor (schema externa)
prezentarea acelorasi date sub forme diferite
Operatii:
creare
- interogare
actualizare ( numai in anumite situatii )
- stergere
CREATE [OR REPLACE] [ALGORITHM = ]Obiectele bazei de date: Secvente
Secventa - Generator automat de valori numerice unice
Utilizat mai ales pentru generarea de valori pentru chei primare
Obiect partajabil
Inlocuieste secvente de cod
Mareste performantele atunci cand valori generate sunt deja memorate in cache
Operatii:
creare
invocare
- stergere
CERATE SEQUENCE nume_secventa
[INCREMENT BY intreg]
[START WITH intre]
[MAXVALUE intreg| NOMAXVALUE]
[MINVALUE intreg| NOMINVALUE]
[CYCLE|NOCYCLE]
[CACHE intreg| NOCACHE]
[ORDER| NOORDER];
INCREMENT BY - specifica intervalul intre doua numere ale secventei
START WITH - specifica prima valoare generata de secventa
MAXVALUE - specifica valoarea minima a secventei
MINVALUE - valoarea maxima a secventei
CYCLE - arata ca secventa continua sa ia valori si dupa ce a atins valoarea maxima sau valoarea minima
CACHE - arata cate valori sunt alocate de catre Oracle si tinute in memorie pentru acces mai rapid.
CREATE SEQUENCE salariat_seq
INCREMENT BY 1
START WITH 1
NOMAXVALUE
NOCYCLE
CACHE 10;
ALTER SEQUENCE salariat_seq
MAXVALUE 10000
CYCLE CACHE 20;
DROP SEQUENCE salariat_seq ;
INSERT INTO salariat (cod_salariat, nume, prenume, data_nastere)
VALUES (salariat_seq.NEXTVAL, 'GEORGESCU', 'VASILE', '11.05.03') ;
NEXTVAL
CURRVAL
Copyright © 2024 - Toate drepturile rezervate